






2
May
寻求一个光滑的最大值函数
By 苏剑林 | 2015-05-02 | 135474位读者 | 引用在最优化问题中,求一个函数的最大值或最小值,最直接的方法是求导,然后比较各阶极值的大小。然而,我们所要优化的函数往往不一定可导,比如函数中含有最大值函数$\max(x,y)$的。这时候就得求助于其他思路了。有一个很巧妙的思路是,将这些不可导函数用一个可导的函数来近似它,从而我们用求极值的方法来求出它近似的最优值。本文的任务,就是探究一个简单而有用的函数,它能够作为最大值函数的近似,并且具有多阶导数。下面是笔者给出的一个推导过程。
在数学分析中,笔者已经学习过一个关于最大值函数的公式,即当$x \geq 0, y \geq 0$时,我们有
$$\max(x,y)=\frac{1}{2}\left(|x+y|+|x-y|\right)\tag{1}$$
那么,为了寻求一个最大值的函数,我们首先可以考虑寻找一个能够近似表示绝对值$|x|$的函数,这样我们就把问题从二维降低到一维了。那么,哪个函数可以使用呢?
22
Jun
文本情感分类(一):传统模型
By 苏剑林 | 2015-06-22 | 230159位读者 | 引用前言:四五月份的时候,我参加了两个数据挖掘相关的竞赛,分别是物电学院举办的“亮剑杯”,以及第三届 “泰迪杯”全国大学生数据挖掘竞赛。很碰巧的是,两个比赛中,都有一题主要涉及到中文情感分类工作。在做“亮剑杯”的时候,由于我还是初涉,水平有限,仅仅是基于传统的思路实现了一个简单的文本情感分类模型。而在后续的“泰迪杯”中,由于学习的深入,我已经基本了解深度学习的思想,并且用深度学习的算法实现了文本情感分类模型。因此,我打算将两个不同的模型都放到博客中,供读者参考。刚入门的读者,可以从中比较两者的不同,并且了解相关思路。高手请一笑置之。
基于情感词典
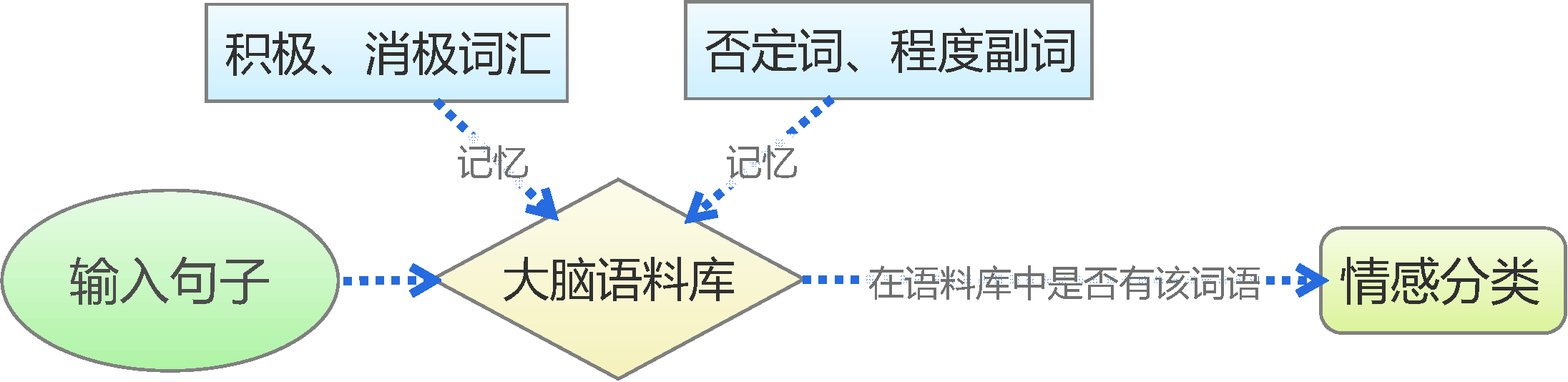
人的最简单的判断思维
7
Nov
【外微分浅谈】6. 微分几何
By 苏剑林 | 2016-11-07 | 46593位读者 | 引用终于开始谈到重点了,就是这部分内容促使我学习外微分的。用外微分可以方便地推导微分几何的一些内容,有时候还能方便计算。其主要根源在于:外微分本身在形式上是微分的推广,因此微分几何的东西能够使用外微分来描述并不出奇;然后,最重要的原因是,外微分把$dx^{\mu}$看成一组基,因此相当于在几何中引入了两组基,一组是本身的向量基(用张量的语言,就是逆变向量的基),这组基可以做对称的内积,另外一组基就是$dx^{\mu}$,这组基可以做反对称的外积。因此,当外微分引入几何时,微分几何就拥有了微分、积分、对称积、反对称积等各种“理想装备”,这就是外微分能够加速微分几何推导的主要原因。
标架的运动
前面已经得到
$$\begin{aligned}&\omega^{\mu}=h_{\alpha}^{\mu}dx^{\alpha}\\
&d\boldsymbol{r}=\hat{\boldsymbol{e}}_{\mu} \omega^{\mu}\\
&ds^2 = \eta_{\mu\nu} \omega^{\mu}\omega^{\nu}\\
&\langle \hat{\boldsymbol{e}}_{\mu}, \hat{\boldsymbol{e}}_{\nu}\rangle = \eta_{\mu\nu}\end{aligned} \tag{45} $$
16
Nov
为什么勒贝格积分比黎曼积分强?
By 苏剑林 | 2016-11-16 | 118403位读者 | 引用学过实变函数的朋友,总会知道有个叫勒贝格积分的东西,号称是黎曼积分的改进版。虽然“实变函数学十遍,泛函分析心泛寒”,在学习实变函数的时候,我们通常都是云里雾里的,不过到最后,在老师的“灌溉”之下,也就耳濡目染了知道了一些结论,比如“黎曼可积的函数(在有限区间),也是勒贝格可积的”,说白了,就是“勒贝格积分比黎曼积分强”。那么,问题来了,究竟强在哪儿?为什么会强?

黎曼

勒贝格
这个问题,笔者在学习实变函数的时候并没有弄懂,后来也一直搁着,直到最近认真看了《重温微积分》之后,才有了些感觉。顺便说,齐民友老师的《重温微积分》真的很赞,值得一看。
本是同根生,相煎何太急?
6
Mar
【中文分词系列】 7. 深度学习分词?只需一个词典!
By 苏剑林 | 2017-03-06 | 118485位读者 | 引用这个系列慢慢写到第7篇,基本上也把分词的各种模型理清楚了,除了一些细微的调整(比如最后的分类器换成CRF)外,剩下的就看怎么玩了。基本上来说,要速度,就用基于词典的分词,要较好地解决组合歧义何和新词识别,则用复杂模型,比如之前介绍的LSTM、FCN都可以。但问题是,用深度学习训练分词器,需要标注语料,这费时费力,仅有的公开的几个标注语料,又不可能赶得上时效,比如,几乎没有哪几个公开的分词系统能够正确切分出“扫描二维码,关注微信号”来。
本文就是做了这样的一个实验,仅用一个词典,就完成了一个深度学习分词器的训练,居然效果还不错!这种方案可以称得上是半监督的,甚至是无监督的。
7
Jul
从SamplePairing到mixup:神奇的正则项
By 苏剑林 | 2018-07-07 | 81173位读者 | 引用SamplePairing和mixup是两种一脉相承的图像数据扩增手段,它们看起来很不合理,而操作则非常简单,但结果却非常漂亮:在多个图像分类任务中都表明它们能提高最终分类模型的精度。
某些读者会困惑于一个问题:为什么如此不合理的数据扩增手段,能得到如此好的效果?而本文则要表明,它们看起来是一种数据扩增方法,事实上它们是对模型的一种正则化方案。正如周星驰的电影《国产凌凌漆》的一句经典台词:
表面上看这是一个吹风机,其实它是一个刮胡刀。
数据扩增
让我们从数据扩增说起。数据扩增是指我们在对原始数据做一些简单的变换后,它们对应的类别往往不会变化,所以我们可以在原来数据的基础上,“造”出更多的数据来。比如一幅小狗的照片,将它水平翻转、轻微的旋转、裁剪、平移等操作后,我们认为它的类别没有变化,它还是原来的那只狗。这样一来,从一个样本我们可以衍生出好几个样本,从而增加了训练样本量。

狗

旋转的狗
几年前,笔者曾经以自己对矩阵的粗浅理解写了一个“理解矩阵”系列,其中有一篇《为什么只有方阵有行列式?》讨论了非方阵的行列式问题,里边给出了“非方针的行列式不好看”和“方阵的行列式就够了”的观点。本文来再次思考这个问题。
首先回顾方阵的行列式,其实行列式最重要的价值在于它的几何意义:
n维方阵的行列式的绝对值,等于它的各个行(或列)向量所张成的n维立体的超体积。
这个几何意义是行列式的一切重要性的源头,相关的讨论可以参考《行列式的点滴》,它也是我们讨论非方阵行列式的基础。
分析
对于方阵$\boldsymbol{A}_{n\times n}$来说,可以将它看成$n$个行向量的组合,也可以看成$n$个列向量的组合,不管是哪一种,行列式的绝对值都等于这$n$个向量所张成的$n$维立体的超体积。换句话说,对于方阵来说,行、列向量的区分不改变行列式。
对于非方阵$\boldsymbol{B}_{n \times k}$就不一样了,不失一般性,假设$n > k$。我们可以将它看成$n$个$k$维行向量的组合,也可以看成$k$个$n$维列向量的组合。非方针的行列式,应该也具有同样含义,即它们所张成的立体的超体积。
我们来看第一种情况,如果看成$n$个$k$维行向量,那么就得视为这$n$个向量张成的$n$维体的超体积了,但是要注意$n > k$,因此这$n$个向量必然线性相关,因此它们根本就张不成一个$n$维体,也许是一个$n-1$维体甚至更低,这样一来,它的$n$维体的超体积自然为0。
但是第二种情况就没有那么平凡了。如果看成$k$个$n$维列向量,那么这$k$个向量虽然是$n$维的,但它们张成的是一个$k$维体,这$k$维体的超体积未必为0。我们就以这个非平凡的体积作为非方阵行列式的定义好了。
25
Nov
6个派生优化器的简单介绍及其实现
By 苏剑林 | 2019-11-25 | 53140位读者 | 引用优化器可能是深度学习最“玄学”的一个模块之一了:有时候换一个优化器就能带来明显的提升,有时候别人说提升很多的优化器用到自己的任务上却一丁点用都没有,理论性质好的优化器不一定工作得很好,纯粹拍脑袋而来的优化器也未必就差了。但不管怎样,优化器终究也为热爱“深度炼丹”的同学提供了多一个选择。
近几年来,关于优化器的工作似乎也在慢慢增多,很多论文都提出了对常用优化器(尤其是Adam)的大大小小的改进。本文就汇总一些优化器工作或技巧,并统一给出了代码实现,供读者有需调用。
基本形式
所谓“派生”,就是指相关的技巧都是建立在已有的优化器上的,任意一个已有的优化器都可以用上这些技巧,从而变成一个新的优化器。
已有的优化器的基本形式为:
\begin{equation}\begin{aligned}\boldsymbol{g}_t =&\, \nabla_{\boldsymbol{\theta}} L\\
\boldsymbol{h}_t =&\, f(\boldsymbol{g}_{\leq t})\\
\boldsymbol{\theta}_{t+1} =&\, \boldsymbol{\theta}_t - \gamma \boldsymbol{h}_t
\end{aligned}\end{equation}
其中$\boldsymbol{g}_t$即梯度,而$\boldsymbol{g}_{\leq t}$指的是截止到当前步的所有梯度信息,它们经过某种运算$f$(比如累积动量、累积二阶矩校正学习率等)后得到$\boldsymbol{h}_t$,然后由$\boldsymbol{h}_t$来更新参数,这里的$\gamma$就是指学习率。

最近评论