






19
Nov
更别致的词向量模型(六):代码、分享与结语
By 苏剑林 | 2017-11-19 | 89331位读者 | 引用
15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 416519位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。
29
Jul
基于GRU和AM-Softmax的句子相似度模型
By 苏剑林 | 2018-07-29 | 318834位读者 | 引用搞计算机视觉的朋友会知道,AM-Softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的
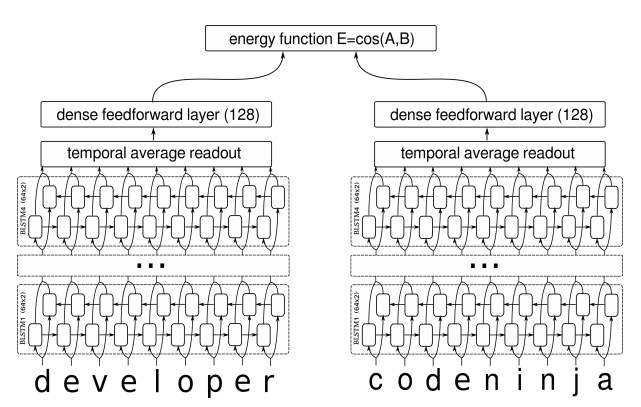
将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。
29
Sep
“让Keras更酷一些!”:层与模型的重用技巧
By 苏剑林 | 2019-09-29 | 94483位读者 | 引用今天我们继续来深挖Keras,再次体验Keras那无与伦比的优雅设计。这一次我们的焦点是“重用”,主要是层与模型的重复使用。
所谓重用,一般就是奔着两个目标去:一是为了共享权重,也就是说要两个层不仅作用一样,还要共享权重,同步更新;二是避免重写代码,比如我们已经搭建好了一个模型,然后我们想拆解这个模型,构建一些子模型等。
基础
事实上,Keras已经为我们考虑好了很多,所以很多情况下,掌握好基本用法,就已经能满足我们很多需求了。
层的重用
层的重用是最简单的,将层初始化好,存起来,然后反复调用即可:
x_in = Input(shape=(784,))
x = x_in
layer = Dense(784, activation='relu') # 初始化一个层,并存起来
x = layer(x) # 第一次调用
x = layer(x) # 再次调用
x = layer(x) # 再次调用
20
Aug
开源一版DGCNN阅读理解问答模型(Keras版)
By 苏剑林 | 2019-08-20 | 67447位读者 | 引用去年写过《基于CNN的阅读理解式问答模型:DGCNN》,介绍了一个纯卷积的简单的问答模型。当时是用Tensorflow实现的,而且没有开源,这几天抽空用Keras复现了一下,决定开源。
模型综述
关于DGCNN的基本介绍,这里不再赘述。本文的模型并不是之前模型的重复实现,而是有所改动,这里只介绍一下被改动的地方。
1、这里放出的模型,线下验证集的分数大概是0.72(之前大约是0.75);
2、本次模型以字为单位,使用笔者之前探索出来的“字词混合Embedding”(之前是以词为单位);
3、本次模型完全去掉了人工特征(之前用了8个人工特征);
4、本次模型去掉了位置Embedding(之前将位置Embedding拼接到输入上);
5、模型架构和训练细节有所微调。
16
Jan
从几何视角来理解模型参数的初始化策略
By 苏剑林 | 2020-01-16 | 86493位读者 | 引用对于复杂模型来说,参数的初始化显得尤为重要。糟糕的初始化,很多时候已经不单是模型效果变差的问题了,还更有可能是模型根本训练不动或者不收敛。在深度学习中常见的自适应初始化策略是Xavier初始化,它是从正态分布$\mathcal{N}\left(0,\frac{2}{fan_{in} + fan_{out}}\right)$中随机采样而构成的初始权重,其中$fan_{in}$是输入的维度而$fan_{out}$是输出的维度。其他初始化策略基本上也类似,只不过假设有所不同,导致最终形式略有差别。
标准的初始化策略的推导是基于概率统计的,大概的思路是假设输入数据的均值为0、方差为1,然后期望输出数据也保持均值为0、方差为1,然后推导出初始变换应该满足的均值和方差条件。这个过程理论上没啥问题,但在笔者看来依然不够直观,而且推导过程的假设有点多。本文则希望能从几何视角来理解模型的初始化方法,给出一个更直观的推导过程。
信手拈来的正交
前者时间笔者写了《n维空间下两个随机向量的夹角分布》,其中的一个推论是
推论1: 高维空间中的任意两个随机向量几乎都是垂直的。
17
Jul
BERT-of-Theseus:基于模块替换的模型压缩方法
By 苏剑林 | 2020-07-17 | 84682位读者 | 引用最近了解到一种称为“BERT-of-Theseus”的BERT模型压缩方法,来自论文《BERT-of-Theseus: Compressing BERT by Progressive Module Replacing》。这是一种以“可替换性”为出发点所构建的模型压缩方案,相比常规的剪枝、蒸馏等手段,它整个流程显得更为优雅、简洁。本文将对该方法做一个简要的介绍,给出一个基于bert4keras的实现,并验证它的有效性。

BERT-of-Theseus,原作配图
模型压缩
首先,我们简要介绍一下模型压缩。不过由于笔者并非专门做模型压缩的,也没有经过特别系统的调研,所以该介绍可能显得不专业,请读者理解。
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 48686位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
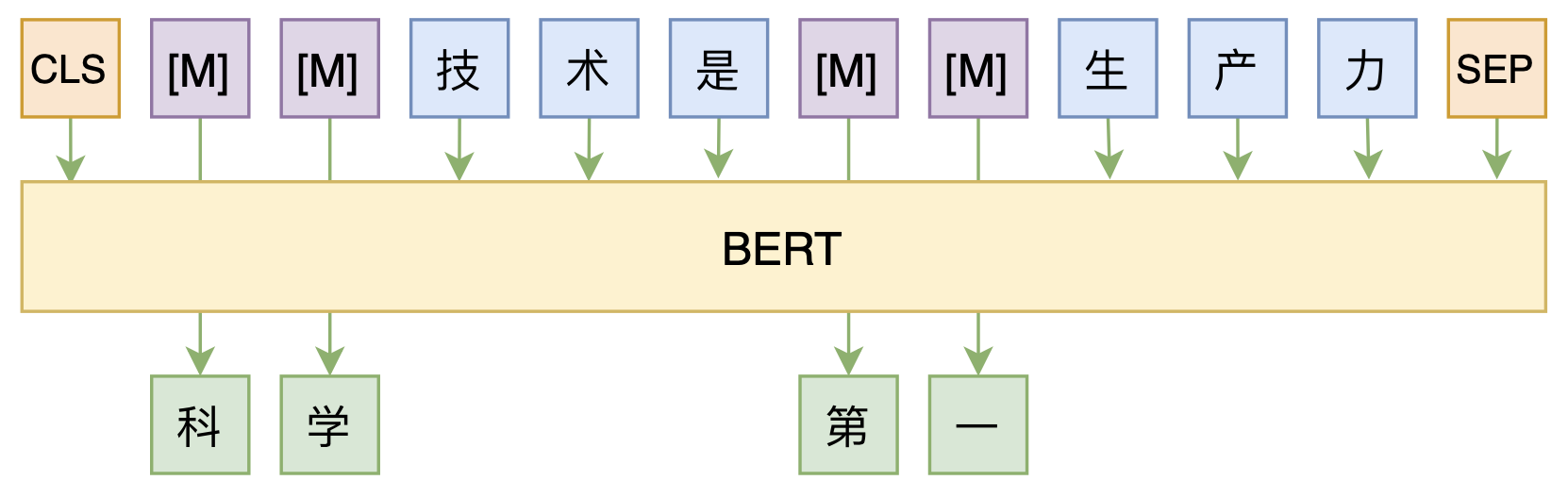
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。

最近评论