






19
Nov
更别致的词向量模型(一):simpler glove
By 苏剑林 | 2017-11-19 | 42103位读者 | 引用如果问我哪个是最方便、最好用的词向量模型,我觉得应该是word2vec,但如果问我哪个是最漂亮的词向量模型,我不知道,我觉得各个模型总有一些不足的地方。且不说试验效果好不好(这不过是评测指标的问题),就单看理论也没有一个模型称得上漂亮的。
本文讨论了一些大家比较关心的词向量的问题,很多结论基本上都是实验发现的,缺乏合理的解释,包括:
如果去构造一个词向量模型?
为什么用余弦值来做近义词搜索?向量的内积又是什么含义?
词向量的模长有什么特殊的含义?
为什么词向量具有词类比性质?(国王-男人+女人=女王)
得到词向量后怎么构建句向量?词向量求和作为简单的句向量的依据是什么?
这些讨论既有其针对性,也有它的一般性,有些解释也许可以直接迁移到对glove模型和skip gram模型的词向量性质的诠释中,读者可以自行尝试。
围绕着这些问题的讨论,本文提出了一个新的类似glove的词向量模型,这里称之为simpler glove,并基于斯坦福的glove源码进行修改,给出了本文的实现,具体代码在Github上。
19
Nov
更别致的词向量模型(二):对语言进行建模
By 苏剑林 | 2017-11-19 | 53649位读者 | 引用从条件概率到互信息
目前,词向量模型的原理基本都是词的上下文的分布可以揭示这个词的语义,就好比“看看你跟什么样的人交往,就知道你是什么样的人”,所以词向量模型的核心就是对上下文的关系进行建模。除了glove之外,几乎所有词向量模型都是在对条件概率$P(w|context)$进行建模,比如Word2Vec的skip gram模型就是对条件概率$P(w_2|w_1)$进行建模。但这个量其实是有些缺点的,首先它是不对称的,即$P(w_2|w_1)$不一定等于$P(w_1|w_2)$,这样我们在建模的时候,就要把上下文向量和目标向量区分开,它们不能在同一向量空间中;其次,它是有界的、归一化的量,这就意味着我们必须使用softmax等方法将它压缩归一,这造成了优化上的困难。
事实上,在NLP的世界里,有一个更加对称的量比单纯的$P(w_2|w_1)$更为重要,那就是
\[\frac{P(w_1,w_2)}{P(w_1)P(w_2)}=\frac{P(w_2|w_1)}{P(w_2)}\tag{1}\]
这个量的大概意思是“两个词真实碰面的概率是它们随机相遇的概率的多少倍”,如果它远远大于1,那么表明它们倾向于共同出现而不是随机组合的,当然如果它远远小于1,那就意味着它们俩是刻意回避对方的。这个量在NLP界是举足轻重的,我们暂且称它为“相关度“,当然,它的对数值更加出名,大名为点互信息(Pointwise Mutual Information,PMI):
\[\text{PMI}(w_1,w_2)=\log \frac{P(w_1,w_2)}{P(w_1)P(w_2)}\tag{2}\]
有了上面的理论基础,我们认为,如果能直接对相关度进行建模,会比直接对条件概率$P(w_2|w_1)$建模更加合理,所以本文就围绕这个角度进行展开。在此之前,我们先进一步展示一下互信息本身的美妙性质。
19
Nov
更别致的词向量模型(五):有趣的结果
By 苏剑林 | 2017-11-19 | 86935位读者 | 引用最后,我们来看一下词向量模型$(15)$会有什么好的性质,或者说,如此煞费苦心去构造一个新的词向量模型,会得到什么回报呢?
模长的含义
似乎所有的词向量模型中,都很少会关心词向量的模长。有趣的是,我们上述词向量模型得到的词向量,其模长还能在一定程度上代表着词的重要程度。我们可以从两个角度理解这个事实。
在一个窗口内的上下文,中心词重复出现概率其实是不大的,是一个比较随机的事件,因此可以粗略地认为
\[P(w,w) \sim P(w)\tag{24}\]
所以根据我们的模型,就有
\[e^{\langle\boldsymbol{v}_{w},\boldsymbol{v}_{w}\rangle} =\frac{P(w,w)}{P(w)P(w)}\sim \frac{1}{P(w)}\tag{25}\]
所以
\[\Vert\boldsymbol{v}_{w}\Vert^2 \sim -\log P(w)\tag{26}\]
可见,词语越高频(越有可能就是停用词、虚词等),对应的词向量模长就越小,这就表明了这种词向量的模长确实可以代表词的重要性。事实上,$-\log P(w)$这个量类似IDF,有个专门的名称叫ICF,请参考论文《TF-ICF: A New Term Weighting Scheme for Clustering Dynamic Data Streams》。
19
Nov
更别致的词向量模型(三):描述相关的模型
By 苏剑林 | 2017-11-19 | 117296位读者 | 引用几何词向量
上述“月老”之云虽说只是幻想,但所面临的问题却是真实的。按照传统NLP的手段,我们可以统计任意两个词的共现频率以及每个词自身的频率,然后去算它们的相关度,从而得到一个“相关度矩阵”。然而正如前面所说,这个共现矩阵太庞大了,必须压缩降维,同时还要做数据平滑,给未出现的词对的相关度赋予一个合理的估值。
在已有的机器学习方案中,我们已经有一些对庞大的矩阵降维的经验了,比如SVD和pLSA,SVD是对任意矩阵的降维,而pLSA是对转移概率矩阵$P(j|i)$的降维,两者的思想是类似的,都是将一个大矩阵$\boldsymbol{A}$分解为两个小矩阵的乘积$\boldsymbol{A}\approx\boldsymbol{B}\boldsymbol{C}$,其中$\boldsymbol{B}$的行数等于$\boldsymbol{A}$的行数,$\boldsymbol{C}$的列数等于$\boldsymbol{A}$的列数,而它们本身的大小则远小于$\boldsymbol{A}$的大小。如果对$\boldsymbol{B},\boldsymbol{C}$不做约束,那么就是SVD;如果对$\boldsymbol{B},\boldsymbol{C}$做正定归一化约束,那就是pLSA。
但是如果是相关度矩阵,那么情况不大一样,它是正定的但不是归一的,我们需要为它设计一个新的压缩方案。借鉴矩阵分解的经验,我们可以设想把所有的词都放在$n$维空间中,也就是用$n$维空间中的一个向量来表示,并假设它们的相关度就是内积的某个函数(为什么是内积?因为矩阵乘法本身就是不断地做内积):
\[\frac{P(w_i,w_j)}{P(w_i)P(w_j)}=f\big(\langle \boldsymbol{v}_i, \boldsymbol{v}_j\rangle\big)\tag{8}\]
其中加粗的$\boldsymbol{v}_i, \boldsymbol{v}_j$表示词$w_i,w_j$对应的词向量。从几何的角度看,我们就是把词语放置到了$n$维空间中,用空间中的点来表示一个词。
因为几何给我们的感觉是直观的,而语义给我们的感觉是复杂的,因此,理想情况下我们希望能够通过几何关系来反映语义关系。下面我们就根据我们所希望的几何特性,来确定待定的函数$f$。事实上,glove词向量的那篇论文中做过类似的事情,很有启发性,但glove的推导实在是不怎么好看。请留意,这里的观点是新颖的——从我们希望的性质,来确定我们的模型,而不是反过来有了模型再推导性质。
机场-飞机+火车=火车站
19
Nov
更别致的词向量模型(四):模型的求解
By 苏剑林 | 2017-11-19 | 51744位读者 | 引用损失函数
现在,我们来定义loss,以便把各个词向量求解出来。用$\tilde{P}$表示$P$的频率估计值,那么我们可以直接以下式为loss
\[\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{v}_j\rangle-\log\frac{\tilde{P}(w_i,w_j)}{\tilde{P}(w_i)\tilde{P}(w_j)}\right)^2\tag{16}\]
相比之下,无论在参数量还是模型形式上,这个做法都比glove要简单,因此称之为simpler glove。glove模型是
\[\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{\hat{v}}_j\rangle+b_i+\hat{b}_j-\log X_{ij}\right)^2\tag{17}\]
在glove模型中,对中心词向量和上下文向量做了区分,然后最后模型建议输出的是两套词向量的求和,据说这效果会更好,这是一个比较勉强的trick,但也不是什么毛病。
\[\begin{aligned}&\sum_{w_i,w_j}\left(\langle \boldsymbol{v}_i, \boldsymbol{\hat{v}}_j\rangle+b_i+\hat{b}_j-\log \tilde{P}(w_i,w_j)\right)^2\\
=&\sum_{w_i,w_j}\left[\langle \boldsymbol{v}_i+\boldsymbol{c}, \boldsymbol{\hat{v}}_j+\boldsymbol{c}\rangle+\Big(b_i-\langle \boldsymbol{v}_i, \boldsymbol{c}\rangle - \frac{|\boldsymbol{c}|^2}{2}\Big)\right.\\
&\qquad\qquad\qquad\qquad\left.+\Big(\hat{b}_j-\langle \boldsymbol{\hat{v}}_j, \boldsymbol{c}\rangle - \frac{|\boldsymbol{c}|^2}{2}\Big)-\log X_{ij}\right]^2\end{aligned}\tag{18}\]
这就是说,如果你有了一组解,那么你将所有词向量加上任意一个常数向量后,它还是一组解!这个问题就严重了,我们无法预估得到的是哪组解,一旦加上的是一个非常大的常向量,那么各种度量都没意义了(比如任意两个词的cos值都接近1)。事实上,对glove生成的词向量进行验算就可以发现,glove生成的词向量,停用词的模长远大于一般词的模长,也就是说一堆词放在一起时,停用词的作用还明显些,这显然是不利用后续模型的优化的。(虽然从目前的关于glove的实验结果来看,是我强迫症了一些。)
互信息估算
19
Nov
更别致的词向量模型(六):代码、分享与结语
By 苏剑林 | 2017-11-19 | 92583位读者 | 引用
2
May
基于Conv1D的光谱分类模型(一维序列分类)
By 苏剑林 | 2018-05-02 | 116784位读者 | 引用前段时间天池出了个天文数据挖掘竞赛——LAMOST光谱分类(将对应的光谱识别为4类中的一类),虽然没有奖金,但还是觉得挺有意思,所以就报名参加了。做了一段时间,成绩自我感觉还可以,然而最后我却忘记了(或者说根本就没留意到)初赛最后两天还有一步是提交新的测试集结果,然后就没有然后了,留下了一个未竟的模型,可谓“出师未捷身先死”,还是被自己弄死的~

天文数据挖掘大赛——天体光谱智能分类
后来跟其他参赛选手讨论了一下,发现其实我的这个模型还是不错的。当时我记得初赛第一名的成绩是0.83+,而我当时的成绩是0.82+,排名大概是第4、5左右,而且据说很多分数在0.8+的队伍都已经使用了融合模型,而我这0.82+的成绩仅仅是单模型的结果~在平时的群聊中发现也有不少朋友在做一维序列分类模型,而光谱分类本质上也就是一个一维的序列分类,所以分享一下模型,估计对相关朋友会有一定的参考价值。
模型
事实上也不是什么特别的模型,就是普通的一维卷积加残差,对于熟悉图像处理的朋友,这实在是再普通不过的结构了。
29
Jul
基于GRU和AM-Softmax的句子相似度模型
By 苏剑林 | 2018-07-29 | 331778位读者 | 引用搞计算机视觉的朋友会知道,AM-Softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的
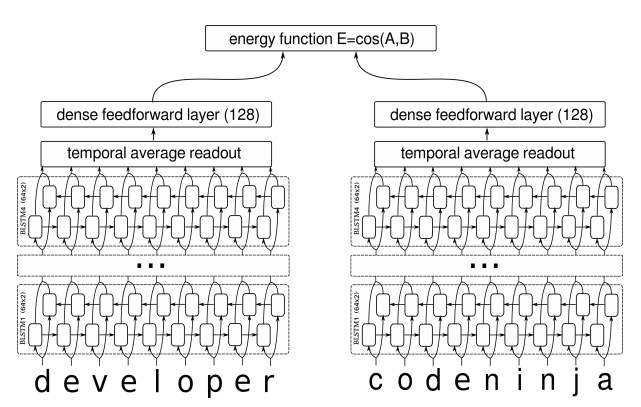
将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。

最近评论