






6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 133404位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。

“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。
20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 73864位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
3
Mar
T5 PEGASUS:开源一个中文生成式预训练模型
By 苏剑林 | 2021-03-03 | 194660位读者 | 引用去年在文章《那个屠榜的T5模型,现在可以在中文上玩玩了》中我们介绍了Google的多国语言版T5模型(mT5),并给出了用mT5进行中文文本生成任务的例子。诚然,mT5做中文生成任务也是一个可用的方案,但缺乏完全由中文语料训练出来模型总感觉有点别扭,于是决心要搞一个出来。
经过反复斟酌测试,我们决定以mT5为基础架构和初始权重,先结合中文的特点完善Tokenizer,然后模仿PEGASUS来构建预训练任务,从而训练一版新的T5模型,这就是本文所开源的T5 PEGASUS。

T5 PEGASUS的训练数据示例
5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 110693位读者 | 引用最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
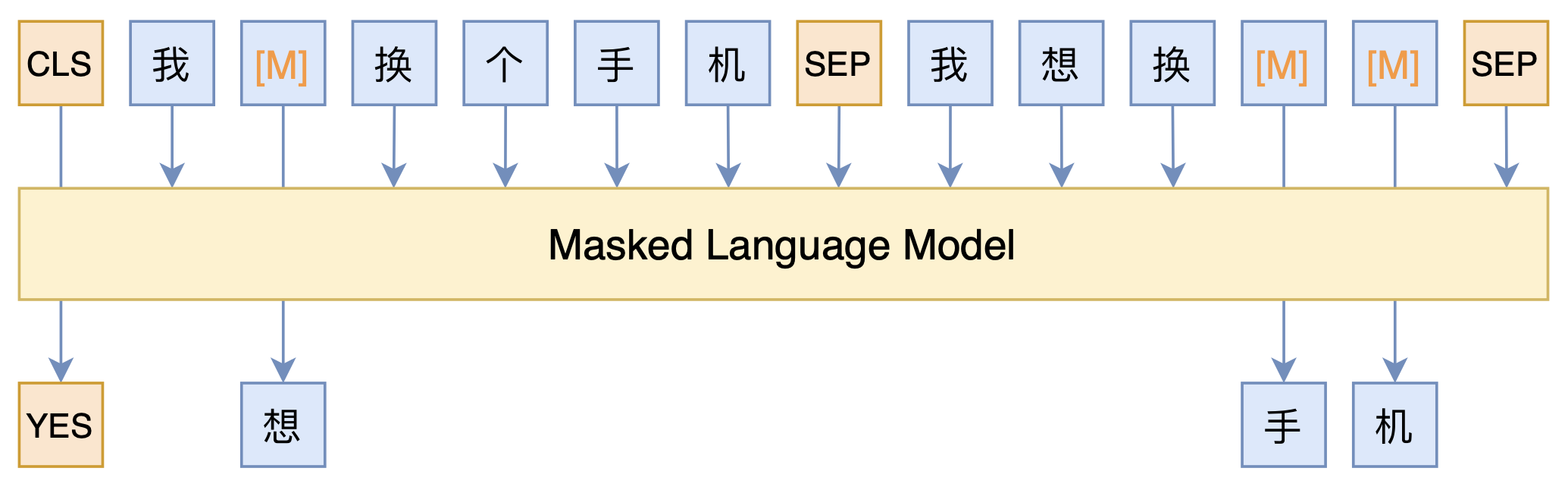
本文模型示意图
3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 151595位读者 | 引用在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
![P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 60416位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。
11
Jun
SimBERTv2来了!融合检索和生成的RoFormer-Sim模型
By 苏剑林 | 2021-06-11 | 112292位读者 | 引用去年我们放出了SimBERT模型,它算是我们开源的比较成功的模型之一,获得了不少读者的认可。简单来说,SimBERT是一个融生成和检索于一体的模型,可以用来作为句向量的一个比较高的baseline,也可以用来实现相似问句的自动生成,可以作为辅助数据扩增工具使用,这一功能是开创性的。
近段时间,我们以RoFormer为基础模型,对SimBERT相关技术进一步整合和优化,最终发布了升级版的RoFormer-Sim模型。
简介
RoFormer-Sim是SimBERT的升级版,我们也可以通俗地称之为“SimBERTv2”,而SimBERT则默认是指旧版。从外部看,除了基础架构换成了RoFormer外,RoFormer-Sim跟SimBERT没什么明显差别,事实上它们主要的区别在于训练的细节上,我们可以用两个公式进行对比:
\begin{array}{c}
\text{SimBERT} = \text{BERT} + \text{UniLM} + \text{对比学习} \\[5pt]
\text{RoFormer-Sim} = \text{RoFormer} + \text{UniLM} + \text{对比学习} + \text{BART} + \text{蒸馏}\\
\end{array}
29
Jun

最近评论