






6
Sep
基于双向LSTM和迁移学习的seq2seq核心实体识别
By 苏剑林 | 2016-09-06 | 160949位读者 | 引用暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下。模型的效果不是最好的,但是胜在“端到端”,迁移性强,估计对大家会有一定的参考价值。
比赛的主题是“核心实体识别”,其实有两个任务:核心识别 + 实体识别。这两个任务虽然有关联,但在传统自然语言处理程序中,一般是将它们分开处理的,而这次需要将两个任务联合在一起。如果只看“核心识别”,那就是传统的关键词抽取任务了,不同的是,传统的纯粹基于统计的思路(如TF-IDF抽取)是行不通的,因为单句中的核心实体可能就只出现一次,这时候统计估计是不可靠的,最好能够从语义的角度来理解。我一开始就是从“核心识别”入手,使用的方法类似QA系统:
1、将句子分词,然后用Word2Vec训练词向量;
2、用卷积神经网络(在这种抽取式问题上,CNN效果往往比RNN要好)卷积一下,得到一个与词向量维度一样的输出;
3、损失函数就是输出向量跟训练样本的核心词向量的cos值。
12
Jan
Self-Orthogonality Module:一个即插即用的核正交化模块
By 苏剑林 | 2020-01-12 | 53245位读者 | 引用前些天刷Arxiv看到新文章《Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters》(下面简称“原论文”),看上去似乎有点意思,于是阅读了一番,读完确实有些收获,在此记录分享一下。
给全连接或者卷积模型的核加上带有正交化倾向的正则项,是不少模型的需求,比如大名鼎鼎的BigGAN就加入了类似的正则项。而这篇论文则引入了一个新的正则项,笔者认为整个分析过程颇为有趣,可以一读。
为什么希望正交?
在开始之前,我们先约定:本文所出现的所有一维向量都代表列向量。那么,现在假设有一个$d$维的输入样本$\boldsymbol{x}\in \mathbb{R}^d$,经过全连接或卷积层时,其核心运算就是:
\begin{equation}\boldsymbol{y}^{\top}=\boldsymbol{x}^{\top}\boldsymbol{W},\quad \boldsymbol{W}\triangleq (\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k)\label{eq:k}\end{equation}
其中$\boldsymbol{W}\in \mathbb{R}^{d\times k}$是一个矩阵,它就被称“核”(全连接核/卷积核),而$\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k\in \mathbb{R}^{d}$是该矩阵的各个列向量。
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 55519位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
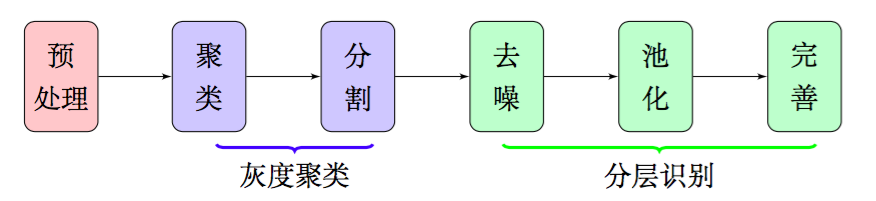
图2:特征提取大概流程
26
Aug
HSIC简介:一个有意思的判断相关性的思路
By 苏剑林 | 2019-08-26 | 99002位读者 | 引用前几天,在机器之心看到这样的一个推送《彻底解决梯度爆炸问题,新方法不用反向传播也能训练ResNet》,当然,媒体的标题党作风我们暂且无视,主要看内容即可。机器之心的这篇文章,介绍的是论文《The HSIC Bottleneck: Deep Learning without Back-Propagation》的成果,里边提出了一种通过HSIC Bottleneck来训练神经网络的算法。
坦白说,这篇论文笔者还没有看明白,因为对笔者来说里边的新概念有点多了。不过论文中的“HSIC”这个概念引起了笔者的兴趣。经过学习,终于基本地理解了这个HSIC的含义和来龙去脉,于是就有了本文,试图给出HSIC的一个尽可能通俗(但可能不严谨)的理解。
背景
HSIC全称“Hilbert-Schmidt independence criterion”,中文可以叫做“希尔伯特-施密特独立性指标”吧,跟互信息一样,它也可以用来衡量两个变量之间的独立性。
4
Jul
线性Attention的探索:Attention必须有个Softmax吗?
By 苏剑林 | 2020-07-04 | 216100位读者 | 引用众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是$\mathcal{O}(n^2)$级别的,$n$是序列长度,所以当$n$比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到$\mathcal{O}(n\log n)$甚至$\mathcal{O}(n)$。
前几天笔者读到了论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》,了解到了线性化Attention(Linear Attention)这个探索点,继而阅读了一些相关文献,有一些不错的收获,最后将自己对线性化Attention的理解汇总在此文中。
Attention
当前最流行的Attention机制当属Scaled-Dot Attention,形式为
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\label{eq:std-att}\end{equation}
这里的$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设$\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}$,一般场景下都有$n > d$甚至$n\gg d$(BERT base里边$d=64$)。
21
Dec
从动力学角度看优化算法(七):SGD ≈ SVM?
By 苏剑林 | 2020-12-21 | 35746位读者 | 引用众所周知,在深度学习之前,机器学习是SVM(Support Vector Machine,支持向量机)的天下,曾经的它可谓红遍机器学习的大江南北,迷倒万千研究人员,直至今日,“手撕SVM”仍然是大厂流行的面试题之一。然而,时过境迁,当深度学习流行起来之后,第一个革的就是SVM的命,现在只有在某些特别追求效率的场景以及大厂的面试题里边,才能看到SVM的踪迹了。
峰回路转的是,最近Arxiv上的一篇论文《Every Model Learned by Gradient Descent Is Approximately a Kernel Machine》做了一个非常“霸气”的宣言:
任何由梯度下降算法学出来的模型,都是可以近似看成是一个SVM!
这结论真不可谓不“霸气”,因为它已经不只是针对深度学习了,而是只要你用梯度下降优化的,都不过是一个SVM(的近似)。笔者看了一下原论文的分析,感觉确实挺有意思也挺合理的,有助于加深我们对很多模型的理解,遂跟大家分享一下。
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 44271位读者 | 引用标准Attention的$\mathcal{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
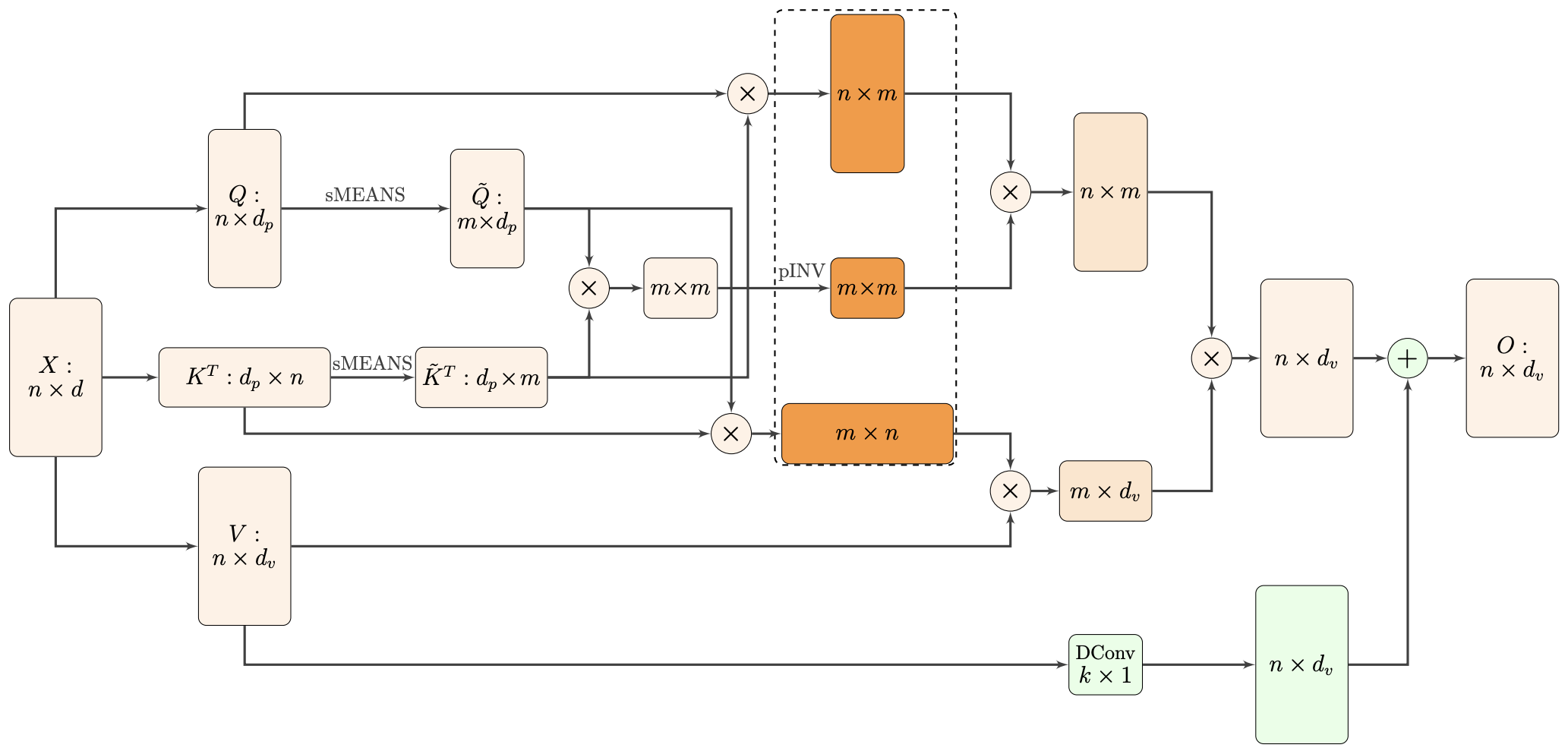
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。
6
Aug
Transformer升级之路:5、作为无限维的线性Attention
By 苏剑林 | 2021-08-06 | 23247位读者 | 引用在《Performer:用随机投影将Attention的复杂度线性化》中我们了解到Google提出的Performer模型,它提出了一种随机投影方案,可以将标准Attention转化为线性Attention,并保持一定的近似。理论上来说,只要投影的维度足够大,那么可以足够近似标准Attention。换句话说,标准Attention可以视作一个无限维的线性Attention。
本文将介绍笔者构思的另外两种将标准Attention转换为无限维线性Attention的思路,不同于Performer的随机投影,笔者构思的这两种方案都是确定性的,并且能比较方便地感知近似程度。
简要介绍
关于标准Attention和线性Attention,这里就不多做介绍了,还不了解的读者可以参考笔者之前的文章《线性Attention的探索:Attention必须有个Softmax吗?》和《Transformer升级之路:3、从Performer到线性Attention》。简单来说,标准Attention的计算方式为
\begin{equation}a_{i,j}=\frac{e^{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_j e^{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}

最近评论