






18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 371240位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
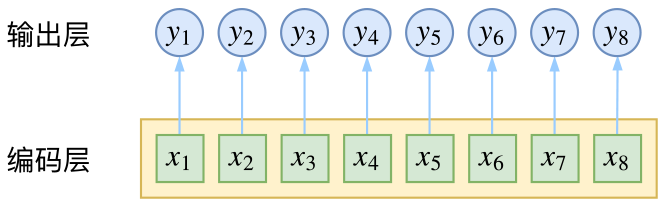
逐帧softmax并没有直接考虑输出的上下文关联
11
Aug
细水长flow之NICE:流模型的基本概念与实现
By 苏剑林 | 2018-08-11 | 322113位读者 | 引用前言:自从在机器之心上看到了glow模型之后(请看《下一个GAN?OpenAI提出可逆生成模型Glow》),我就一直对其念念不忘。现在机器学习模型层出不穷,我也经常关注一些新模型动态,但很少像glow模型那样让我怦然心动,有种“就是它了”的感觉。更意外的是,这个效果看起来如此好的模型,居然是我以前完全没有听说过的。于是我翻来覆去阅读了好几天,越读越觉得有意思,感觉通过它能将我之前的很多想法都关联起来。在此,先来个阶段总结。
背景
本文主要是《NICE: Non-linear Independent Components Estimation》一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。
艰难的分布
众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。

glow模型生成的高清人脸
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 310421位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
15
Feb
能量视角下的GAN模型(二):GAN=“分析”+“采样”
By 苏剑林 | 2019-02-15 | 148539位读者 | 引用在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
上一篇文章里,我们给出了一个直白而用力的能量图景,这个图景可以让我们轻松理解GAN的很多内容,换句话说,通俗的解释已经能让我们完成大部分的理解了,并且把最终的结论都已经写了出来。在这篇文章中,我们继续从能量的视角理解GAN,这一次,我们争取把前面简单直白的描述,用相对严密的数学语言推导一遍。
跟第一篇文章一样,对于笔者来说,这个推导过程依然直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》。
原作者的开源实现:https://github.com/ritheshkumar95/energy_based_generative_models
本文的大致内容如下:
1、推导了能量分布下的正负相对抗的更新公式;
2、比较了理论分析与实验采样的区别,而将两者结合便得到了GAN框架;
3、导出了生成器的补充loss,理论上可以防止mode collapse;
4、简单提及了基于能量函数的MCMC采样。
21
Mar
细水长flow之可逆ResNet:极致的暴力美学
By 苏剑林 | 2019-03-21 | 131355位读者 | 引用今天我们来介绍一个非常“暴力”的模型:可逆ResNet。
为什么一个模型可以可以用“暴力”来形容呢?当然是因为它确实非常暴力:它综合了很多数学技巧,活生生地(在一定约束下)把常规的ResNet模型搞成了可逆的!
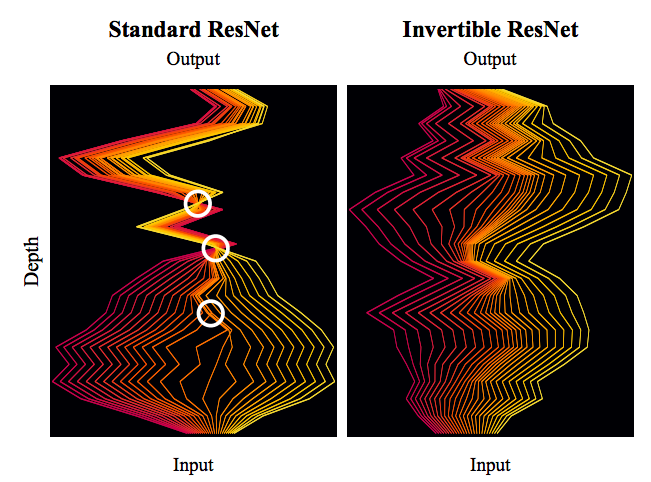
标准ResNet与可逆ResNet对比图。可逆ResNet允许信息无损可逆流动,而标准ResNet在某处则存在“坍缩”现象。
模型出自《Invertible Residual Networks》,之前在机器之心也报导过。在这篇文章中,我们来简单欣赏一下它的原理和内容。
可逆模型的点滴
为什么要研究可逆ResNet模型?它有什么好处?以前没有人研究过吗?
可逆的好处
可逆意味着什么?
意味着它是信息无损的,意味着它或许可以用来做更好的分类网络,意味着可以直接用最大似然来做生成模型,而且得益于ResNet强大的能力,意味着它可能有着比之前的Glow模型更好的表现~总而言之,如果一个模型是可逆的,可逆的成本不高而且拟合能力强,那么它就有很广的用途(分类、密度估计和生成任务,等等)。
23
Jun
从采样看优化:可导优化与不可导优化的统一视角
By 苏剑林 | 2020-06-23 | 65991位读者 | 引用不少读者都应该知道,损失函数与评测指标的不一致性是机器学习的典型现象之一,比如分类问题中损失函数用交叉熵,评测指标则是准确率或者F1,又比如文本生成中损失函数是teacher-forcing形式的交叉熵,评测指标则是BLEU、ROUGE等。理想情况下,当然是评测什么指标,我们就去优化这个指标,然而评测指标通常都是不可导的,而我们多数都是使用基于梯度的优化器,这就要求最小化的目标必须是可导的,这是不一致性的来源。
前些天在arxiv刷到了一篇名为《MLE-guided parameter search for task loss minimization in neural sequence modeling》的论文,顾名思义,它是研究如何直接优化文本生成的评测指标的。经过阅读,笔者发现这篇论文很有价值,事实上它提供了一种优化评测指标的新思路,适用范围并不局限于文本生成中。不仅如此,它甚至还包含了一种理解可导优化与不可导优化的统一视角。
采样视角
首先,我们可以通过采样的视角来重新看待优化问题:设模型当前参数为θ,优化目标为l(θ),我们希望决定下一步的更新量Δθ,为此,我们先构建分布
p(Δθ|θ)=e−[l(θ+Δθ)−l(θ)]/αZ(θ),Z(θ)=∫e−[l(θ+Δθ)−l(θ)]/αd(Δθ)
8
Aug
生成扩散模型漫谈(六):一般框架之ODE篇
By 苏剑林 | 2022-08-08 | 154792位读者 | 引用上一篇文章《生成扩散模型漫谈(五):一般框架之SDE篇》中,我们对宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》做了基本的介绍和推导。然而,顾名思义,上一篇文章主要涉及的是原论文中SDE相关的部分,而遗留了被称为“概率流ODE(Probability flow ODE)”的部分内容,所以本文对此做个补充分享。
事实上,遗留的这部分内容在原论文的正文中只占了一小节的篇幅,但我们需要新开一篇文章来介绍它,因为笔者想了很久后发现,该结果的推导还是没办法绕开Fokker-Planck方程,所以我们需要一定的篇幅来介绍Fokker-Planck方程,然后才能请主角ODE登场。
再次反思
我们来大致总结一下上一篇文章的内容:首先,我们通过SDE来定义了一个前向过程(“拆楼”):
\begin{equation}d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\label{eq:sde-forward}\end{equation}
17
Jan
细水长flow之TARFLOW:流模型满血归来?
By 苏剑林 | 2025-01-17 | 33248位读者 | 引用不知道还有没有读者对这个系列有印象?这个系列取名“细水长flow”,主要介绍flow模型的相关工作,起因是当年(2018年)OpenAI发布了一个新的流模型Glow,在以GAN为主流的当时来说着实让人惊艳了一番。但惊艳归惊艳,事实上在相当长的时间内,Glow及后期的一些改进在生成效果方面都是比不上GAN的,更不用说现在主流的扩散模型了。
不过局面可能要改变了,上个月的论文《Normalizing Flows are Capable Generative Models》提出了新的流模型TARFLOW,它在几乎在所有的生成任务效果上都逼近了当前SOTA,可谓是流模型的“满血”回归。

TARFLOW的生成效果

最近评论