






24
Jun
VQ-VAE的简明介绍:量子化自编码器
By 苏剑林 | 2019-06-24 | 300896位读者 | 引用印象中很早之前就看到过VQ-VAE,当时对它并没有什么兴趣,而最近有两件事情重新引起了我对它的兴趣。一是VQ-VAE-2实现了能够匹配BigGAN的生成效果(来自机器之心的报道);二是我最近看一篇NLP论文《Unsupervised Paraphrasing without Translation》时发现里边也用到了VQ-VAE。这两件事情表明VQ-VAE应该是一个颇为通用和有意思的模型,所以我决定好好读读它。

个人复现的VQ-VAE在CelebA上的重构效果。可以留意到细节保留得还不错,但稍微放大后能留意到仍有一些模糊感。
29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 134687位读者 | 引用在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
6
Jul
你跳绳的时候,想过绳子的形状曲线是怎样的吗?
By 苏剑林 | 2019-07-06 | 47741位读者 | 引用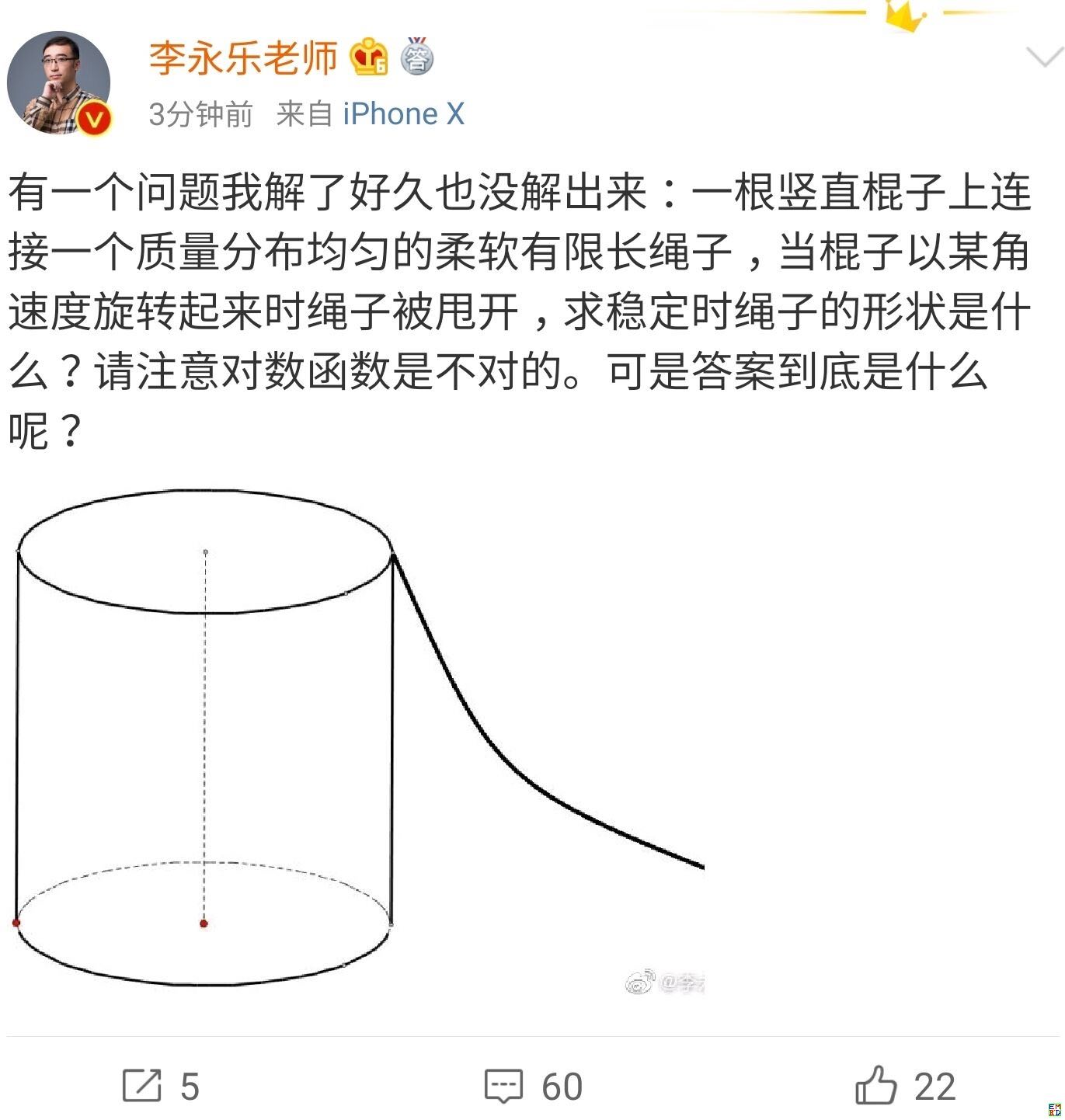
21
Jul
思考:两个椭圆片能粘合成一个立体吗?
By 苏剑林 | 2019-07-21 | 57007位读者 | 引用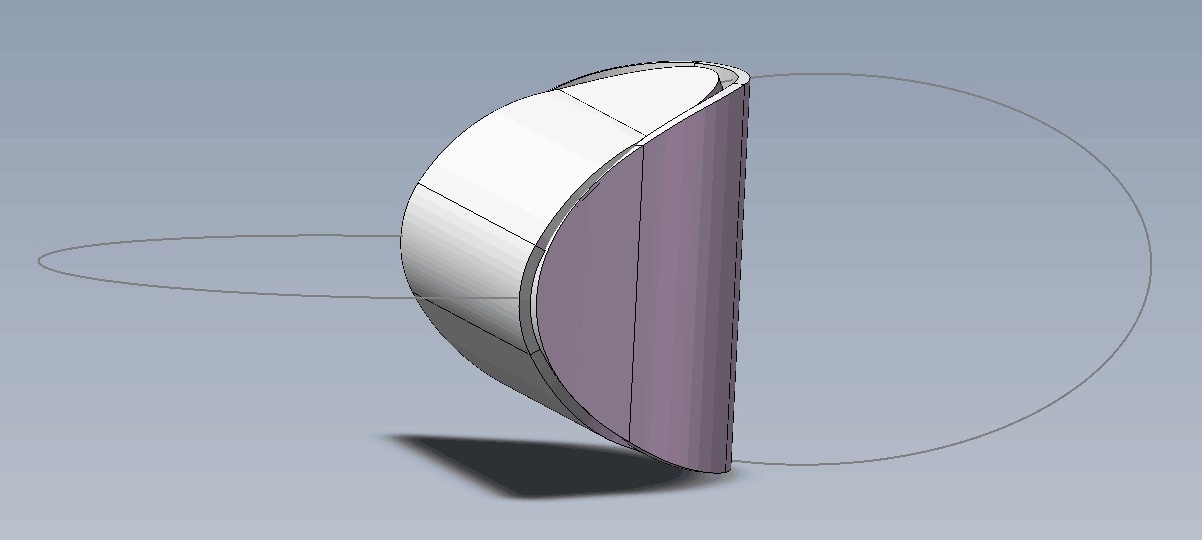
9
Aug
seq2seq之双向解码
By 苏剑林 | 2019-08-09 | 44885位读者 | 引用在文章《玩转Keras之seq2seq自动生成标题》中我们已经基本探讨过seq2seq,并且给出了参考的Keras实现。
本文则将这个seq2seq再往前推一步,引入双向的解码机制,它在一定程度上能提高生成文本的质量(尤其是生成较长文本时)。本文所介绍的双向解码机制参考自《Synchronous Bidirectional Neural Machine Translation》,最后笔者也是用Keras实现的。
背景介绍
研究过seq2seq的读者都知道,常见的seq2seq的解码过程是从左往右逐字(词)生成的,即根据encoder的结果先生成第一个字;然后根据encoder的结果以及已经生成的第一个字,来去生成第二个字;再根据encoder的结果和前两个字,来生成第三个词;依此类推。总的来说,就是在建模如下概率分解
\begin{equation}p(Y|X)=p(y_1|X)p(y_2|X,y_1)p(y_3|X,y_1,y_2)\cdots\label{eq:p}\end{equation}
26
Aug
HSIC简介:一个有意思的判断相关性的思路
By 苏剑林 | 2019-08-26 | 97035位读者 | 引用前几天,在机器之心看到这样的一个推送《彻底解决梯度爆炸问题,新方法不用反向传播也能训练ResNet》,当然,媒体的标题党作风我们暂且无视,主要看内容即可。机器之心的这篇文章,介绍的是论文《The HSIC Bottleneck: Deep Learning without Back-Propagation》的成果,里边提出了一种通过HSIC Bottleneck来训练神经网络的算法。
坦白说,这篇论文笔者还没有看明白,因为对笔者来说里边的新概念有点多了。不过论文中的“HSIC”这个概念引起了笔者的兴趣。经过学习,终于基本地理解了这个HSIC的含义和来龙去脉,于是就有了本文,试图给出HSIC的一个尽可能通俗(但可能不严谨)的理解。
背景
HSIC全称“Hilbert-Schmidt independence criterion”,中文可以叫做“希尔伯特-施密特独立性指标”吧,跟互信息一样,它也可以用来衡量两个变量之间的独立性。
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 81830位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
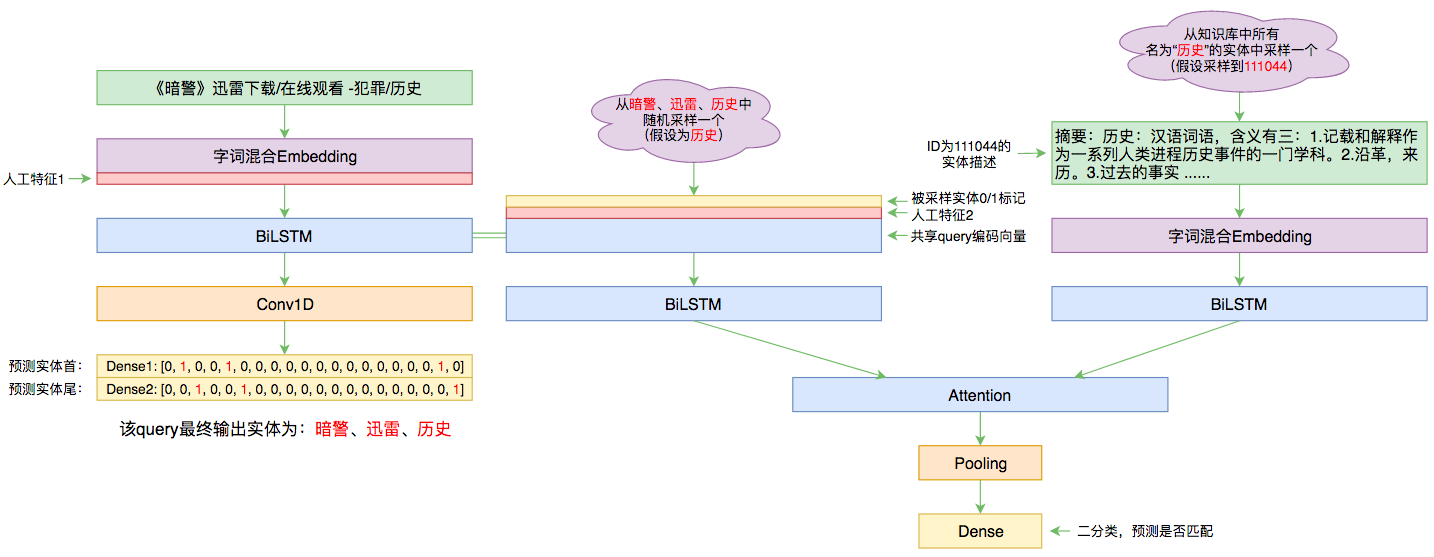
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
13
Nov
n维空间下两个随机向量的夹角分布
By 苏剑林 | 2019-11-13 | 127681位读者 | 引用昨天群里大家讨论到了$n$维向量的一些反直觉现象,其中一个话题是“一般$n$维空间下两个随机向量几乎都是垂直的”,这就跟二维/三维空间的认知有明显出入了。要从理论上认识这个结论,我们可以考虑两个随机向量的夹角$\theta$分布,并算算它的均值方差。
概率密度
首先,我们来推导$\theta$的概率密度函数。呃,其实也不用怎么推导,它是$n$维超球坐标的一个直接结论。
要求两个随机向量之间的夹角分布,很显然,由于各向同性,所以我们只需要考虑单位向量,而同样是因为各向同性,我们只需要固定其中一个向量,考虑另一个向量随机变化。不是一般性,考虑随机向量为
\begin{equation}\boldsymbol{x}=(x_1,x_2,\dots,x_n)\end{equation}
而固定向量为
\begin{equation}\boldsymbol{y}=(1,0,\dots,0)\end{equation}

最近评论