






4
Dec
[转载]复杂的机械,简单的原理
By 苏剑林 | 2012-12-04 | 47281位读者 | 引用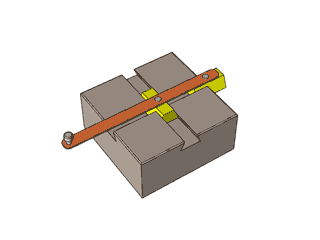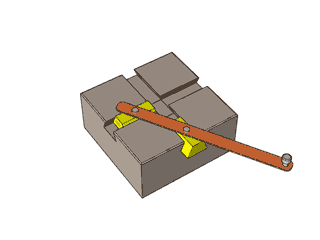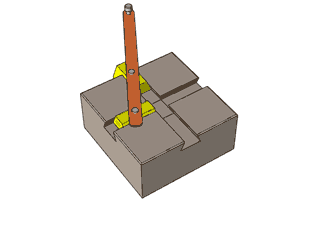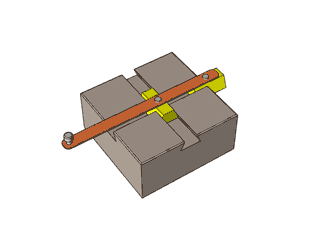
4
Feb
[问题解答]双曲线上的最短距离
By 苏剑林 | 2013-02-04 | 28656位读者 | 引用曾经我会一字不差地看完你的日志,
一点蛋疼的破事都会当成宝贝一样。
和你分享,
跟你在一起,
笑点低的莫名其妙。
你知道我所有的事,
我也收藏着你太多的秘密。
我们可以一直聊到凌晨,
好像从来不缺话题。
可是...
可是...
后来,我们慢慢失去了联系。
等我们发现
时间是贼了,
它早己把我们
说不完的话
偷光了。
偶尔遇见,
也只能尴尬一笑,
寒暄几句,
便再无联络。
你一定以为无情的我把过去都忘记了,
你以为我把你看得不再重要。
那么,你肯定不知道,
我常梦见我们一起仰望过的那片天空呢。
亲爱的老朋友,
和亲爱的曾经心心相印的人。
不联系不是因为你不重要,
而是我好怕,
我不再重要。
17
May
正项级数敛散性最有力的判别法?
By 苏剑林 | 2013-05-17 | 105083位读者 | 引用在学习正项级数的时候,我们的数学分析教材提供了各种判别法,比如积分判别法、比较判别法,并由此衍生出了根植法、比值法等,在最后提供了一个比较精细的“Raabe判别法”。这些方法的精度(强度)各不相同,一般认为“Raabe判别法”的应用范围最广的。但是在我看来,基于p级数的比较判别法已经可以用于所有题目了,它才是最强的方法。
p级数就是我们熟悉的
∞∑n=11np
通过积分判别法可以得到当p>1时该级数收敛,反之发散。虽然我不能证明,但是我觉得以下结论是成立的:
若正项级数∑∞n=1an收敛,则总可以找到一个常数A以及一个大于1的常数p,使每项都有an<Anp。
26
Sep
数学基本技艺(A Mathematical Trivium)
By 苏剑林 | 2013-09-26 | 26209位读者 | 引用这是Arnold给物理系学生出的基础数学题。原文是Arnold于1991年,在Russian Math Surveys 46:1(1991),271-278上发的一篇文章,英文名叫 A mathematical trivium,这篇文章是有个前言的,用两页纸的内容吐槽了1991年的学生数学学得很烂,尤其是物理系的。文后附了100道数学题,号称是物理系学生的数学底线。
这是给物理系出的数学题,所以和一般的数学竞赛题目不同,没太多证明题,主要就是计算和解模型,而且还有不少近似估算的,带有明显的物理风格。虽然作者说这是物理系学生数学的底线,但即使对于数学系的学生来说,这些题目还是有不少难度的。网络也有一些题目的答案,但是都比较零散。在这里与大家分享一下题目。什么时候有时间了,或者刚好碰到类似的研究,我也会把题目做做,与各位分享。希望有兴趣的朋友做了之后也把答案与大家交流呀。

1
13
Mar
一维弹簧的运动(下)
By 苏剑林 | 2014-03-13 | 28931位读者 | 引用在查找量子化有关资料的时候,笔者查找到了一系列名为《漫谈几何量子化》的文章,并进一步查询得知,作者为季候风,原来发表在繁星客栈(顺便提一下,繁星客栈是最早的理论物理论坛之一,现在已经不能发帖了,但是上面很多资料都弥足珍贵),据说这是除正则量子化和路径积分量子化外的第三种量子化方法。网上鲜有几何量子化的资料,更不用说是中文资料了,于是季候风前辈的这一十五篇文章便显得格外有意义了。
然而,虽然不少网站都转载了这系列文章,但是无一例外地,文章中的公式图片已经失效了,后来笔者在百度网盘那找到其中的十四篇pdf格式的(估计是网友在公式图片失效前保存下来的),笔者通过替换公式服务器的方式找回了第十五篇,把第十五篇也补充进去了。(见漫谈几何量子化(原文档).zip)
虽然这样已经面前能够阅读了,但是总感觉美中不足,虽然笔者花了三天时间把文章重新用LATEX录入了,主要是把公式重新录入了,简单地排版了一下。现放出来与大家分享。
30
Jan

最近评论