






20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 66884位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 19348位读者 | 引用
25
Apr
注意力和Softmax的两点有趣发现:鲁棒性和信息量
By 苏剑林 | 2023-04-25 | 29149位读者 | 引用最近几周笔者一直都在思考注意力机制的相关性质,在这个过程中对注意力及Softmax有了更深刻的理解。在这篇文章中,笔者简单分享其中的两点:
1、Softmax注意力天然能够抵御一定的噪声扰动;
2、从信息熵角度也可以对初始化问题形成直观理解。
鲁棒性
基于Softmax归一化的注意力机制,可以写为
\begin{equation}o = \frac{\sum\limits_{i=1}^n e^{s_i} v_i}{\sum\limits_{i=1}^n e^{s_i}}\end{equation}
有一天笔者突然想到一个问题:如果往$s_i$中加入独立同分布的噪声会怎样?
13
Nov
【生活杂记】炒锅的尽头是铁锅
By 苏剑林 | 2023-11-13 | 54391位读者 | 引用
铁锅(网络图)
很多会下厨的同学估计都纠结过一件事情,那就是炒锅的选择。
对于炒锅的纠结,归根结底是不粘与方便的权衡。最简单的不粘锅自然是带涂层的不粘锅,如果家里的热源只有电磁炉,并且炒菜习惯比较温和,那么涂层不粘锅往往是最佳选择了。不过,一旦有了明火的燃气灶,又或者是比较喜欢爆炒,那么涂层锅可能就不是那么适合了,毕竟温度过高涂层总有脱落的风险,此时一般就考虑无涂层不粘锅。
无涂层不粘锅也有五花八门的选择,比如朴素的铁锅、带蜂窝纹的不锈钢锅、有钛锅、纯钛锅等等,价格大体上也单调递增。不过用到最后,我觉得大部分人都会回归到朴素的铁锅。
17
Jul
【生活杂记】用电饭锅来煮米汤
By 苏剑林 | 2024-07-17 | 14267位读者 | 引用
12
Aug
“Cool Papers + 站内搜索”的一些新尝试
By 苏剑林 | 2024-08-12 | 15116位读者 | 引用在《Cool Papers更新:简单搭建了一个站内检索系统》这篇文章中,我们介绍了Cool Papers新增的站内搜索系统。搜索系统的目的,自然希望能够帮助用户快速找到他们需要的论文。然而,如何高效地检索到对自己有价值的结果,并不是一件简单的事情,这里边往往需要一些技巧,比如精准提炼关键词。
这时候算法的价值就体现出来了,有些步骤人工来做会比较繁琐,但用算法来却很简单。所以接下来,我们将介绍几点通过算法来提高Cool Papers的搜索和筛选论文效率的新尝试。
相关论文
站内搜索背后的技术是全文检索引擎(Full-text Search Engine),简单来说,这就是一个基于关键词匹配的搜索算法,其相似度指标是BM25。
26
Sep
利用“熄火保护 + 通断器”实现燃气灶智能关火
By 苏剑林 | 2024-09-26 | 13750位读者 | 引用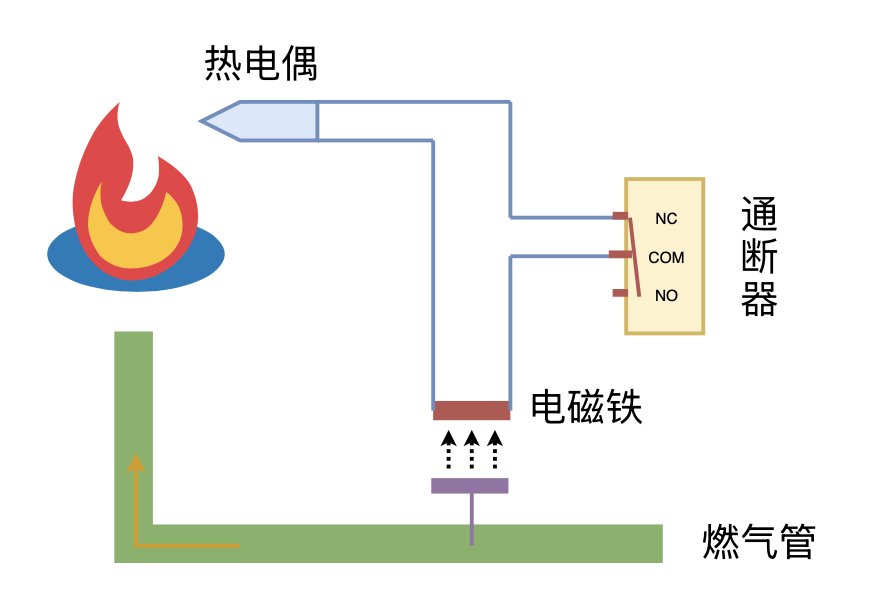
16
Aug


最近评论