






6
Jan
《Attention is All You Need》浅读(简介+代码)
By 苏剑林 | 2018-01-06 | 872958位读者 | 引用2017年中,有两篇类似同时也是笔者非常欣赏的论文,分别是FaceBook的《Convolutional Sequence to Sequence Learning》和Google的《Attention is All You Need》,它们都算是Seq2Seq上的创新,本质上来说,都是抛弃了RNN结构来做Seq2Seq任务。
这篇博文中,笔者对《Attention is All You Need》做一点简单的分析。当然,这两篇论文本身就比较火,因此网上已经有很多解读了(不过很多解读都是直接翻译论文的,鲜有自己的理解),因此这里尽可能多自己的文字,尽量不重复网上各位大佬已经说过的内容。
序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_t)$,其中$\boldsymbol{x}_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$\boldsymbol{X}\in \mathbb{R}^{n\times d}$。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
\begin{equation}\boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t)\end{equation}
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
14
Jan
基于CNN和序列标注的对联机器人
By 苏剑林 | 2019-01-14 | 43395位读者 | 引用缘起
前几天在量子位公众号上看到了《这个脑洞清奇的对联AI,大家都玩疯了》一文,觉得挺有意思,难得的是作者还整理并公开了数据集,所以决定自己尝试一下。
动手
“对对联”,我们可以看成是一个句子生成任务,可以用seq2seq完成,跟笔者之前写的《玩转Keras之seq2seq自动生成标题》一样,稍微修改一下输入即可。上面提到的文章所用的方法也是seq2seq,可见这算是标准做法了。
3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 406555位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
24
Feb
CRF用过了,不妨再了解下更快的MEMM?
By 苏剑林 | 2020-02-24 | 48224位读者 | 引用HMM、MEMM、CRF被称为是三大经典概率图模型,在深度学习之前的机器学习时代,它们被广泛用于各种序列标注相关的任务中。一个有趣的现象是,到了深度学习时代,HMM和MEMM似乎都“没落”了,舞台上就只留下CRF。相信做NLP的读者朋友们就算没亲自做过也会听说过BiLSTM+CRF做中文分词、命名实体识别等任务,却几乎没有听说过BiLSTM+HMM、BiLSTM+MEMM的,这是为什么呢?
今天就让我们来学习一番MEMM,并且通过与CRF的对比,来让我们更深刻地理解概率图模型的思想与设计。
模型推导
MEMM全称Maximum Entropy Markov Model,中文名可译为“最大熵马尔可夫模型”。不得不说,这个名字可能会吓退80%的初学者:最大熵还没搞懂,马尔可夫也不认识,这两个合起来怕不是天书?而事实上,不管是MEMM还是CRF,它们的模型都远比它们的名字来得简单,它们的概念和设计都非常朴素自然,并不难理解。
1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 305300位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathcal{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
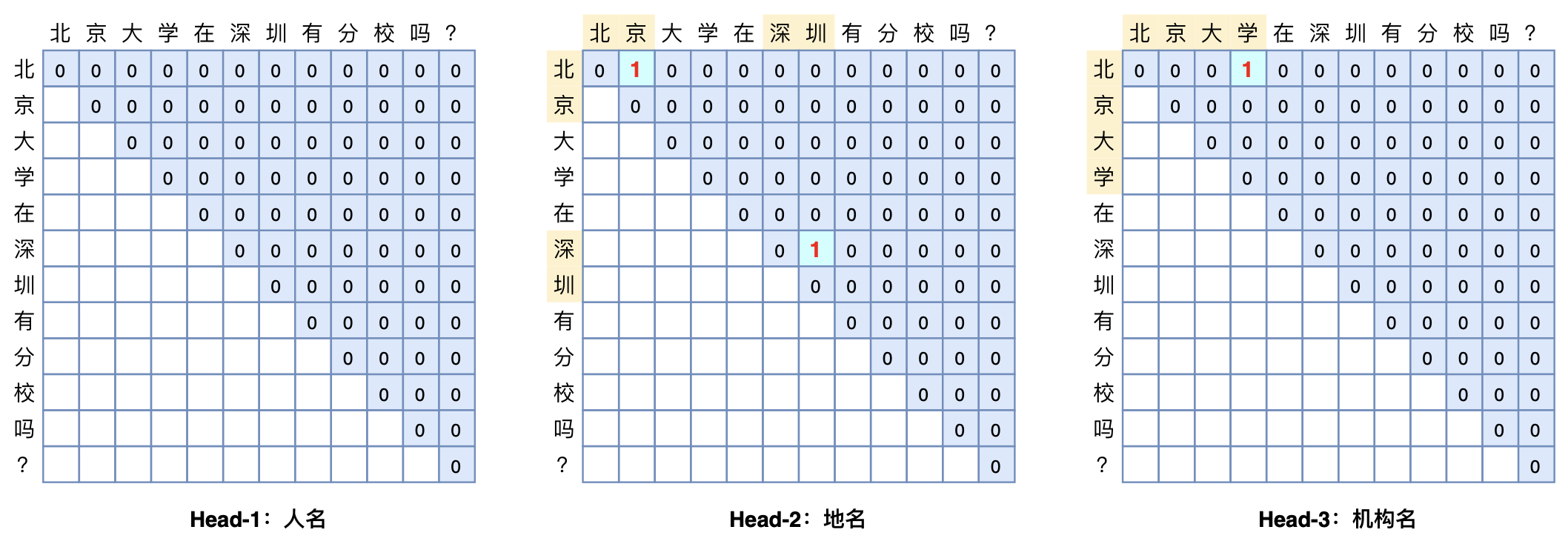
GlobalPointer多头识别嵌套实体示意图
31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 75968位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 76538位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
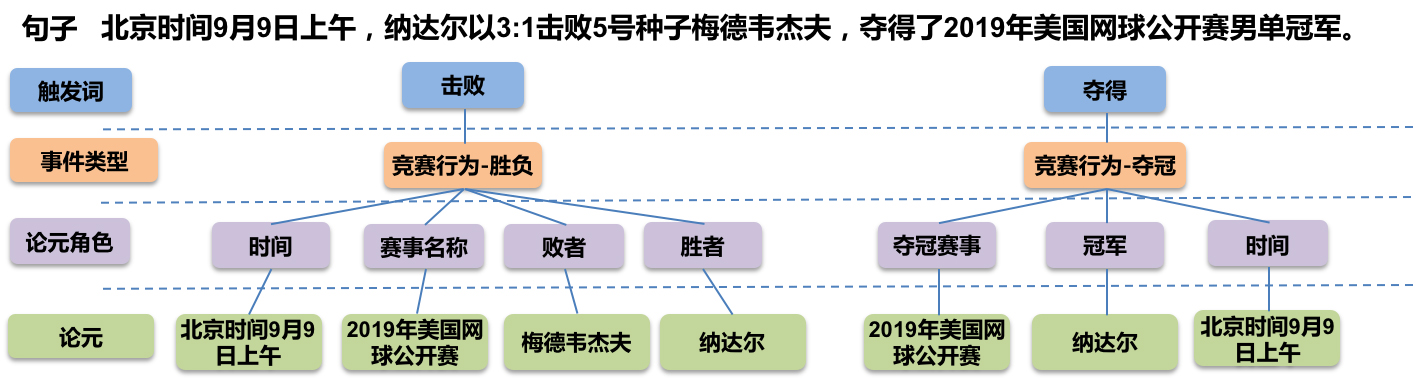
标准的事件抽取样本(图片来自百度DuEE的GitHub)
30
Jan
GPLinker:基于GlobalPointer的实体关系联合抽取
By 苏剑林 | 2022-01-30 | 118052位读者 | 引用在将近三年前的百度“2019语言与智能技术竞赛”(下称LIC2019)中,笔者提出了一个新的关系抽取模型(参考《基于DGCNN和概率图的轻量级信息抽取模型》),后被进一步发表和命名为“CasRel”,算是当时关系抽取的SOTA。然而,CasRel提出时笔者其实也是首次接触该领域,所以现在看来CasRel仍有诸多不完善之处,笔者后面也有想过要进一步完善它,但也没想到特别好的设计。
后来,笔者提出了GlobalPointer以及近日的Efficient GlobalPointer,感觉有足够的“材料”来构建新的关系抽取模型了。于是笔者从概率图思想出发,参考了CasRel之后的一些SOTA设计,最终得到了一版类似TPLinker的模型。
基础思路
关系抽取乍看之下是三元组$(s,p,o)$(即subject, predicate, object)的抽取,但落到具体实现上,它实际是“五元组”$(s_h,s_t,p,o_h,o_t)$的抽取,其中$s_h,s_t$分别是$s$的首、尾位置,而$o_h,o_t$则分别是$o$的首、尾位置。

最近评论