






25
Dec
从loss的硬截断、软化到focal loss
By 苏剑林 | 2017-12-25 | 198402位读者 | 引用前言
今天在QQ群里的讨论中看到了focal loss,经搜索它是Kaiming大神团队在他们的论文《Focal Loss for Dense Object Detection》提出来的损失函数,利用它改善了图像物体检测的效果。不过我很少做图像任务,不怎么关心图像方面的应用。本质上讲,focal loss就是一个解决分类问题中类别不平衡、分类难度差异的一个loss,总之这个工作一片好评就是了。大家还可以看知乎的讨论:
《如何评价kaiming的Focal Loss for Dense Object Detection?》
看到这个loss,开始感觉很神奇,感觉大有用途。因为在NLP中,也存在大量的类别不平衡的任务。最经典的就是序列标注任务中类别是严重不平衡的,比如在命名实体识别中,显然一句话里边实体是比非实体要少得多,这就是一个类别严重不平衡的情况。我尝试把它用在我的基于序列标注的问答模型中,也有微小提升。嗯,这的确是一个好loss。
接着我再仔细对比了一下,我发现这个loss跟我昨晚构思的一个loss具有异曲同工之理!这就促使我写这篇博文了。我将从我自己的思考角度出发,来分析这个问题,最后得到focal loss,也给出我昨晚得到的类似的loss。
28
Oct
朋友们,来瓶汽水吧!有趣的换汽水问题
By 苏剑林 | 2015-10-28 | 33679位读者 | 引用————怀念我曾经参加过的小学数学竞赛。
从一道小学竞赛题谈起
笔者小学五年级时参加了第一次数学竞赛,叫“育苗杯”,大多数题目都记不清楚了,唯一记得很清楚的是如下这道题目(不完全相同,意思类似):
假设汽水一块钱一瓶,而且4个空瓶子可以换一瓶汽水喝。如果我有30块钱,我最多可以喝到多少瓶汽水?

来瓶汽水吧
当然,这道题并不困难,30块钱能买30瓶汽水,然后留下30个空瓶子,这30个空瓶子可以换来7瓶汽水,剩下2个空瓶子;喝完汽水后,剩下9个空瓶子,可以换来2瓶汽水,剩下1个空瓶子;喝完汽水后,剩下3个空瓶子。算算看,这时候我们已经喝了30+7+2=39瓶汽水了。(不考虑撑着啊,也可以分给别人喝^_^)整个过程如下表:
$$\begin{array}{c|cccc}
\hline
\text{空瓶子数} & 30 & 2+7 & 1+2 & ? \\
\hline
\text{已喝汽水数} & 30 & 7 & 2 & ? \\
\hline \end{array}$$
13
Nov
ARXIV数学论文分布:偏微分方程最热门!
By 苏剑林 | 2015-11-13 | 31992位读者 | 引用笔者成功地保研到了中山大学的基础数学专业,这个专业自然是比较理论性的,虽然如此,我还会保持着我对数据分析、计算机等方面的兴趣。这几天兴致来了,想做一下结合我的专业跟数据挖掘相结合的研究,所以就爬取了ARXIV上面近五年(2010年到2014年)的数学论文(包含的数据有:标题、分类、年份、月份),想对这几年来数学的“行情”做一下简单的分析。个人认为,ARVIX作为目前全球最大的论文预印本的电子数据库,对它的数据进行分析,所得到的结论是能够具有一定的代表性的。
当然,本文只是用来练手爬虫和基本数据分析的文章,并没有挖掘出特别有价值的信息。文末附录了笔者爬取到的数据,供有兴趣的读者进一步分析研究。
整体情况
这五年来,ARXIV的数学论文总数为135009篇,平均每年27000篇,或者每天74篇。
18
Nov
《量子力学与路径积分》习题解答V0.3
By 苏剑林 | 2015-11-18 | 18525位读者 | 引用新的《量子力学与路径积分》习题解答又放出来啦。与前两个版本不同的是,前两次更新,每次基本上完成了两章的习题,而这一次,只是增加了第6章的22道习题(第6章共有29道)。原因很多,各种忙就不说啦,主要是第6章开始,各种题目开始复杂起来,计算量也增大,虽然笔者是数学系的,可是还是前进得艰难。还有,第4、5两章加起来也只是25道习题,第6章却有29题,因此,本次更新的工作量,远远大于前两次更新的工作量。
为什么只有22题?当然是没有做完啦。为什么没有做完就更新啦?因为笔者觉得右面的题目,跟第7章的联系更为密切,因此,怕读者等不及,所以剩下的题目,跟第7章一起再发吧。
此外,我是看着中文版来做题的,中文版的翻译质量还不错,但是细微之处却有些不妥当,所以笔者要来回参考中英文版,颇累。读者可以发现,这一版中,“勘误”增加了不少。
3
Aug
运动相机测试:家乡的星空
By 苏剑林 | 2016-08-03 | 38813位读者 | 引用记得很早之前就想尝试一下拍星空,无奈一直都没有设备。以前只知道单反可以拍星空,因此,一直以来的想法就是有钱了就去买台单反。因为各种原因一拖再拖,最后慢慢觉得,对于我这种三分钟热度的人来说,单反的意义还真的不是很大。
这两年,在小米的鼓吹下,小蚁运动相机在国内算是慢慢掀起了一股运动相机潮。这种相机的特点是小巧、灵活,价格也不贵(相比单反)。灵活不仅仅是说它便于携带,而且还是功能上的灵活,比如一代小蚁还支持编程拍摄!(写程序控制快门、ISO、拍摄间隔,并实现定时拍摄等)这样当然很快就吸引了我,在小蚁2代众筹之时,我也咬咬牙,入了一台。
前两天回到家,刚好晴夜,马上就试了一下拍星空的效果。下面是在我家楼顶拍的,用ISO400曝光30秒的效果:

家乡的星空
最近一直在考虑一些自然语言处理问题和一些非线性分析问题,无暇总结发文,在此表示抱歉。本文要说的是对于一阶非线性差分方程(当然高阶也可以类似地做)的一种摄动格式,理论上来说,本方法可以得到任意一阶非线性差分方程的显式渐近解。
非线性差分方程
对于一般的一阶非线性差分方程
$$\begin{equation}\label{chafenfangcheng}x_{n+1}-x_n = f(x_n)\end{equation}$$
通常来说,差分方程很少有解析解,因此要通过渐近分析等手段来分析非线性差分方程的性质。很多时候,我们首先会考虑将差分替换为求导,得到微分方程
$$\begin{equation}\label{weifenfangcheng}\frac{dx}{dn}=f(x)\end{equation}$$
作为差分方程$\eqref{chafenfangcheng}$的近似。其中的原因,除了微分方程有比较简单的显式解之外,另一重要原因是微分方程$\eqref{weifenfangcheng}$近似保留了差分方程$\eqref{chafenfangcheng}$的一些比较重要的性质,如渐近性。例如,考虑离散的阻滞增长模型:
$$\begin{equation}\label{zuzhizengzhang}x_{n+1}=(1+\alpha)x_n -\beta x_n^2\end{equation}$$
对应的微分方程为(差分替换为求导):
$$\begin{equation}\frac{dx}{dn}=\alpha x -\beta x^2\end{equation}$$
此方程解得
$$\begin{equation}x_n = \frac{\alpha}{\beta+c e^{-\alpha n}}\end{equation}$$
其中$c$是任意常数。上述结果已经大概给出了原差分方程$\eqref{zuzhizengzhang}$的解的变化趋势,并且成功给出了最终的渐近极限$x_n \to \frac{\alpha}{\beta}$。下图是当$\alpha=\beta=1$且$c=1$(即$x_0=\frac{1}{2}$)时,微分方程的解与差分方程的解的值比较。
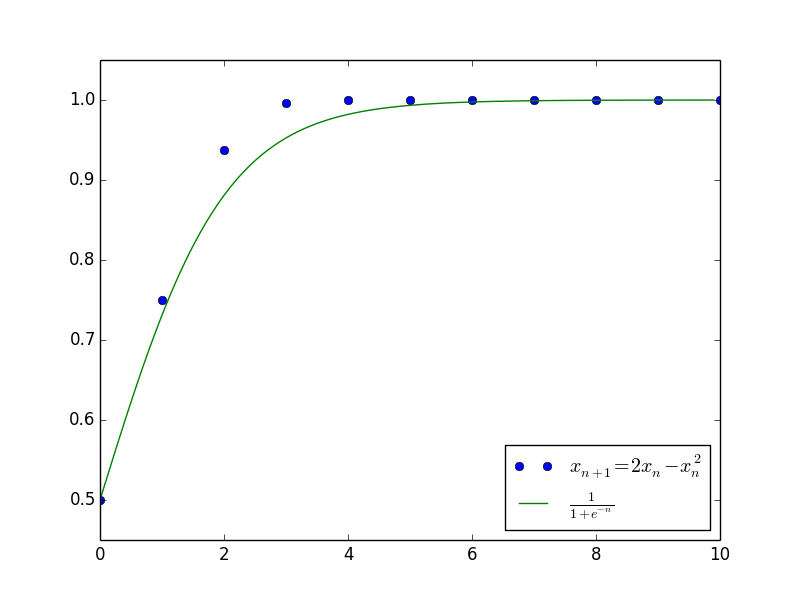
差分方程的摄动法1
现在的问题是,既然微分方程的解可以作为一个形态良好的近似解了,那么是否可以在微分方程的解的基础上,进一步加入修正项提高精度?
1
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(一)
By 苏剑林 | 2015-12-01 | 83723位读者 | 引用熵的概念
作为一名物理爱好者,我一直对统计力学中“熵”这个概念感到神秘和好奇。因此,当我接触数据科学的时候,我也对最大熵模型产生了浓厚的兴趣。
熵是什么?在通俗的介绍中,熵一般有两种解释:(1)熵是不确定性的度量;(2)熵是信息的度量。看上去说的不是一回事,其实它们说的就是同一个意思。首先,熵是不确定性的度量,它衡量着我们对某个事物的“无知程度”。熵为什么又是信息的度量呢?既然熵代表了我们对事物的无知,那么当我们从“无知”到“完全认识”这个过程中,就会获得一定的信息量,我们开始越无知,那么到达“完全认识”时,获得的信息量就越大,因此,作为不确定性的度量的熵,也可以看作是信息的度量,说准确点,是我们能从中获得的最大的信息量。
6
Dec


最近评论