






10
Jun
漫谈重参数:从正态分布到Gumbel Softmax
By 苏剑林 | 2019-06-10 | 235727位读者 | 引用最近在用VAE处理一些文本问题的时候遇到了对离散形式的后验分布求期望的问题,于是沿着“离散分布 + 重参数”这个思路一直搜索下去,最后搜到了Gumbel Softmax,从对Gumbel Softmax的学习过程中,把重参数的相关内容都捋了一遍,还学到一些梯度估计的新知识,遂记录在此。
文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。
基本概念
重参数(Reparameterization)实际上是处理如下期望形式的目标函数的一种技巧:
\begin{equation}L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\label{eq:base}\end{equation}
这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现($f(z)$对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于$z$的连续性,它对应不同的形式:
\begin{equation}\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\end{equation}
当然,离散情况下我们更喜欢将记号$z$换成$y$或者$c$。
19
Oct
最小熵原理(五):“层层递进”之社区发现与聚类
By 苏剑林 | 2019-10-19 | 156567位读者 | 引用让我们不厌其烦地回顾一下:最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
这篇文章里,我们会介绍一种相当漂亮的聚类算法,它同样也体现了最小熵原理,或者说它可以通过最小熵原理导出来,名为InfoMap,或者MapEquation。事实上InfoMap已经是2007年的成果了,最早的论文是《Maps of random walks on complex networks reveal community structure》,虽然看起来很旧,但我认为它仍是当前最漂亮的聚类算法,因为它不仅告诉了我们“怎么聚类”,更重要的是给了我们一个“为什么要聚类”的优雅的信息论解释,并从这个解释中直接导出了整个聚类过程。
一个复杂有向图网络示意图。图片来自InfoMap最早的论文《Maps of random walks on complex networks reveal community structure》
当然,它的定位并不仅仅局限在聚类上,更准确地说,它是一种图网络上的“社区发现”算法。所谓社区发现(Community Detection),大概意思是给定一个有向/无向图网络,然后找出这个网络上的“抱团”情况,至于详细含义,大家可以自行搜索一下。简单来说,它跟聚类相似,但是比聚类的含义更丰富。(还可以参考《什么是社区发现?》)
24
Jun
VQ-VAE的简明介绍:量子化自编码器
By 苏剑林 | 2019-06-24 | 330298位读者 | 引用印象中很早之前就看到过VQ-VAE,当时对它并没有什么兴趣,而最近有两件事情重新引起了我对它的兴趣。一是VQ-VAE-2实现了能够匹配BigGAN的生成效果(来自机器之心的报道);二是我最近看一篇NLP论文《Unsupervised Paraphrasing without Translation》时发现里边也用到了VQ-VAE。这两件事情表明VQ-VAE应该是一个颇为通用和有意思的模型,所以我决定好好读读它。

个人复现的VQ-VAE在CelebA上的重构效果。可以留意到细节保留得还不错,但稍微放大后能留意到仍有一些模糊感。
26
Aug
HSIC简介:一个有意思的判断相关性的思路
By 苏剑林 | 2019-08-26 | 101790位读者 | 引用前几天,在机器之心看到这样的一个推送《彻底解决梯度爆炸问题,新方法不用反向传播也能训练ResNet》,当然,媒体的标题党作风我们暂且无视,主要看内容即可。机器之心的这篇文章,介绍的是论文《The HSIC Bottleneck: Deep Learning without Back-Propagation》的成果,里边提出了一种通过HSIC Bottleneck来训练神经网络的算法。
坦白说,这篇论文笔者还没有看明白,因为对笔者来说里边的新概念有点多了。不过论文中的“HSIC”这个概念引起了笔者的兴趣。经过学习,终于基本地理解了这个HSIC的含义和来龙去脉,于是就有了本文,试图给出HSIC的一个尽可能通俗(但可能不严谨)的理解。
背景
HSIC全称“Hilbert-Schmidt independence criterion”,中文可以叫做“希尔伯特-施密特独立性指标”吧,跟互信息一样,它也可以用来衡量两个变量之间的独立性。
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 88532位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
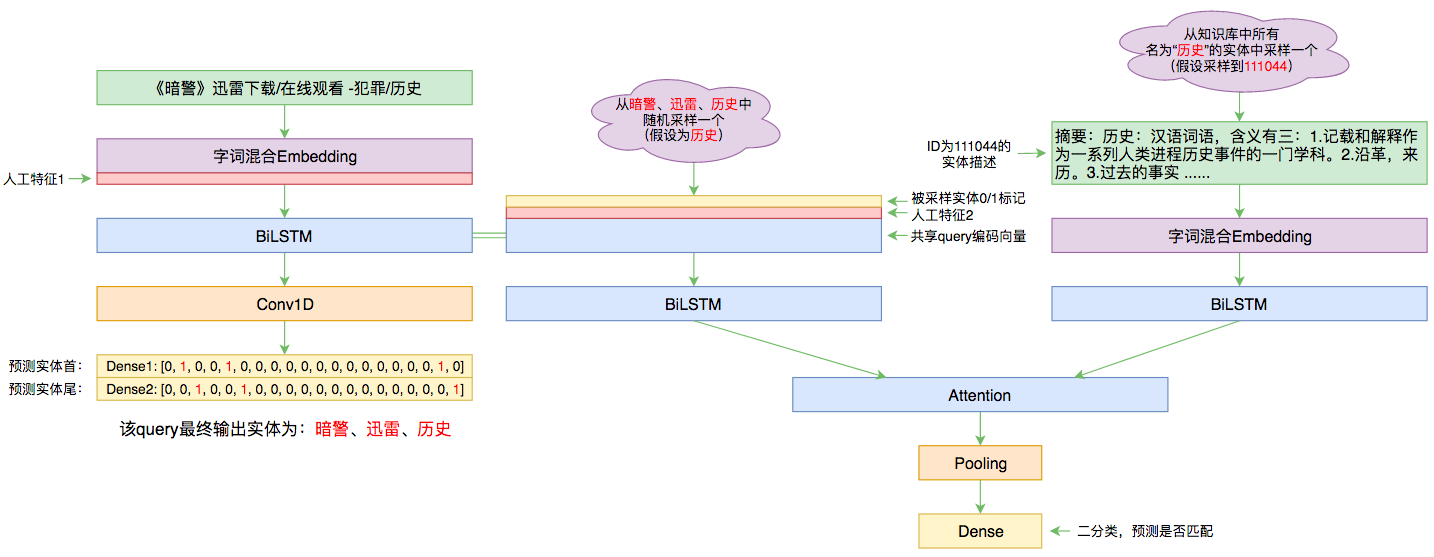
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
31
Oct
从去噪自编码器到生成模型
By 苏剑林 | 2019-10-31 | 112480位读者 | 引用在我看来,几大顶会之中,ICLR的论文通常是最有意思的,因为它们的选题和风格基本上都比较轻松活泼、天马行空,让人有脑洞大开之感。所以,ICLR 2020的投稿论文列表出来之后,我也抽时间粗略过了一下这些论文,确实发现了不少有意思的工作。
其中,我发现了两篇利用去噪自编码器的思想做生成模型的论文,分别是《Learning Generative Models using Denoising Density Estimators》和《Annealed Denoising Score Matching: Learning Energy-Based Models in High-Dimensional Spaces》。由于常规做生成模型的思路我基本都有所了解,所以这种“别具一格”的思路就引起了我的兴趣。细读之下,发现两者的出发点是一致的,但是具体做法又有所不同,最终的落脚点又是一样的,颇有“一题多解”的美妙,遂将这两篇论文放在一起,对比分析一翻。

fashion mnist、CelebA、cifar10上的生成效果
11
Oct
BN究竟起了什么作用?一个闭门造车的分析
By 苏剑林 | 2019-10-11 | 122254位读者 | 引用BN,也就是Batch Normalization,是当前深度学习模型(尤其是视觉相关模型)的一个相当重要的技巧,它能加速训练,甚至有一定的抗过拟合作用,还允许我们用更大的学习率,总的来说颇多好处(前提是你跑得起较大的batch size)。
那BN究竟是怎么起作用呢?早期的解释主要是基于概率分布的,大概意思是将每一层的输入分布都归一化到$\mathcal{N}(0,1)$上,减少了所谓的Internal Covariate Shift,从而稳定乃至加速了训练。这种解释看上去没什么毛病,但细思之下其实有问题的:不管哪一层的输入都不可能严格满足正态分布,从而单纯地将均值方差标准化无法实现标准分布$\mathcal{N}(0,1)$;其次,就算能做到$\mathcal{N}(0,1)$,这种诠释也无法进一步解释其他归一化手段(如Instance Normalization、Layer Normalization)起作用的原因。
在去年的论文《How Does Batch Normalization Help Optimization?》里边,作者明确地提出了上述质疑,否定了原来的一些观点,并提出了自己关于BN的新理解:他们认为BN主要作用是使得整个损失函数的landscape更为平滑,从而使得我们可以更平稳地进行训练。
本博文主要也是分享这篇论文的结论,但论述方法是笔者“闭门造车”地构思的。窃认为原论文的论述过于晦涩了,尤其是数学部分太不好理解,所以本文试图尽可能直观地表达同样观点。
(注:阅读本文之前,请确保你已经清楚知道BN是什么,本文不再重复介绍BN的概念和流程。)
1
Mar
对抗训练浅谈:意义、方法和思考(附Keras实现)
By 苏剑林 | 2020-03-01 | 230613位读者 | 引用当前,说到深度学习中的对抗,一般会有两个含义:一个是生成对抗网络(Generative Adversarial Networks,GAN),代表着一大类先进的生成模型;另一个则是跟对抗攻击、对抗样本相关的领域,它跟GAN相关,但又很不一样,它主要关心的是模型在小扰动下的稳健性。本博客里以前所涉及的对抗话题,都是前一种含义,而今天,我们来聊聊后一种含义中的“对抗训练”。
本文包括如下内容:
1、对抗样本、对抗训练等基本概念的介绍;
2、介绍基于快速梯度上升的对抗训练及其在NLP中的应用;
3、给出了对抗训练的Keras实现(一行代码调用);
4、讨论了对抗训练与梯度惩罚的等价性;
5、基于梯度惩罚,给出了一种对抗训练的直观的几何理解。

最近评论