






1
May
GlobalPointer:用统一的方式处理嵌套和非嵌套NER
By 苏剑林 | 2021-05-01 | 225442位读者 | 引用(注:本文的相关内容已整理成论文《Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition》,如需引用可以直接引用英文论文,谢谢。)
本文将介绍一个称为GlobalPointer的设计,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。还有,在理论上,GlobalPointer的设计思想就比CRF更合理;而在实践上,它训练的时候不需要像CRF那样递归计算分母,预测的时候也不需要动态规划,是完全并行的,理想情况下时间复杂度是$\mathscr{O}(1)$!
简单来说,就是更漂亮、更快速、更强大!真有那么好的设计吗?不妨继续看看。
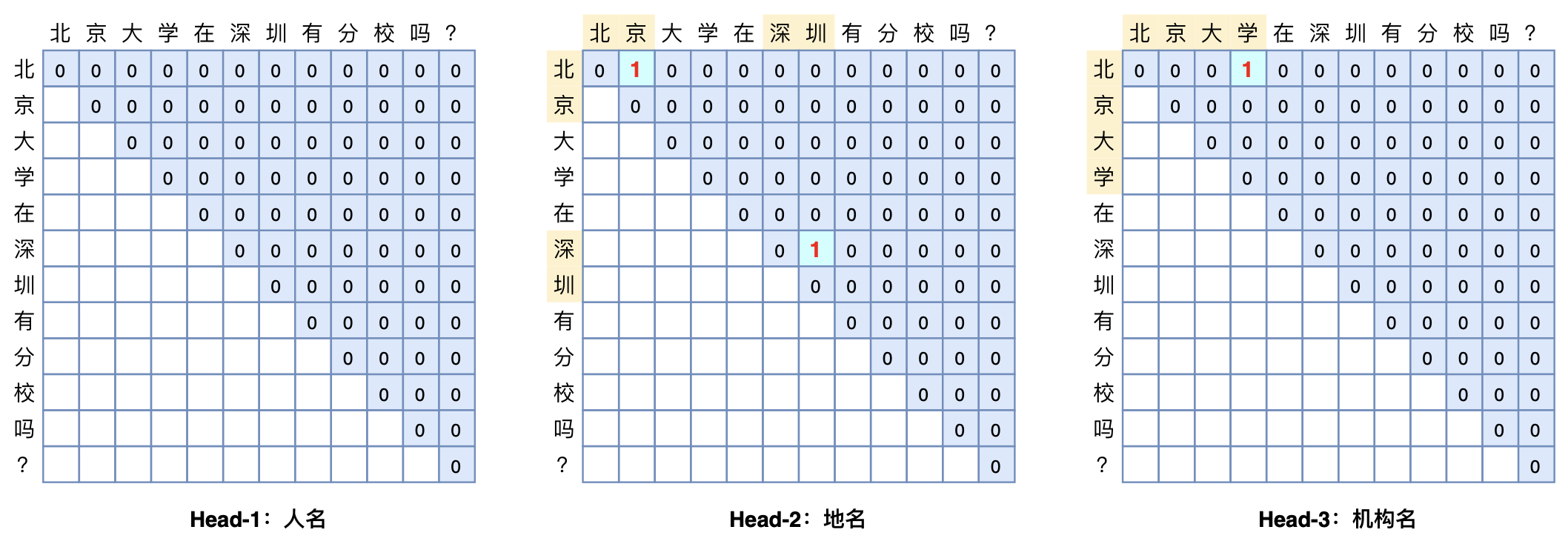
GlobalPointer多头识别嵌套实体示意图
10
Oct
用狄拉克函数来构造非光滑函数的光滑近似
By 苏剑林 | 2021-10-10 | 59688位读者 | 引用在机器学习中,我们经常会碰到不光滑的函数,但我们的优化方法通常是基于梯度的,这意味着光滑的模型可能更利于优化(梯度是连续的),所以就有了寻找非光滑函数的光滑近似的需求。事实上,本博客已经多次讨论过相关主题,比如《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等,但以往的讨论在方法上并没有什么通用性。
不过,笔者从最近的一篇论文《SAU: Smooth activation function using convolution with approximate identities》学习到了一种比较通用的思路:用狄拉克函数来构造光滑近似。通用到什么程度呢?理论上有可数个间断点的函数都可以用它来构造光滑近似!个人感觉还是非常有意思的。
17
Jun
对比学习可以使用梯度累积吗?
By 苏剑林 | 2021-06-17 | 43310位读者 | 引用在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们介绍过“梯度累积”,它是在有限显存下实现大batch_size效果的一种技巧。一般来说,梯度累积适用的是loss是独立同分布的场景,换言之每个样本单独计算loss,然后总loss是所有单个loss的平均或求和。然而,并不是所有任务都满足这个条件的,比如最近比较热门的对比学习,每个样本的loss还跟其他样本有关。
那么,在对比学习场景,我们还可以使用梯度累积来达到大batch_size的效果吗?本文就来分析这个问题。
简介
一般情况下,对比学习的loss可以写为
\begin{equation}\mathcal{L}=-\sum_{i,j=1}^b t_{i,j}\log p_{i,j} = -\sum_{i,j=1}^b t_{i,j}\log \frac{e^{s_{i,j}}}{\sum\limits_j e^{s_{i,j}}}=-\sum_{i,j=1}^b t_{i,j}s_{i,j} + \sum_{i=1}^b \log\sum_{j=1}^b e^{s_{i,j}}\label{eq:loss}\end{equation}
这里的$b$是batch_size;$t_{i,j}$是事先给定的标签,满足$t_{i,j}=t_{j,i}$,它是一个one hot矩阵,每一列只有一个1,其余都为0;而$s_{i,j}$是样本$i$和样本$j$的相似度,满足$s_{i,j}=s_{j,i}$,一般情况下还有个温度参数,这里假设温度参数已经整合到$s_{i,j}$中,从而简化记号。模型参数存在于$s_{i,j}$中,假设为$\theta$。
4
Dec
开局一段扯,数据全靠编?真被一篇“神论文”气到了
By 苏剑林 | 2021-12-04 | 45425位读者 | 引用这篇文章谈一下笔者被昨天出来的一篇“神论文”气到了的经历。
这篇“神论文”是《How not to Lie with a Benchmark: Rearranging NLP Leaderboards》,论文的大致内容是说目前很多排行榜算平均都用算术平均,而它认为几何平均与调和平均更加合理。最关键是它还对GLUE、SuperGLUE等榜单上的模型用几何平均和调和平均重新算了一下排名,结果发现那些超过人类的模型在新的平均方案下都没超过人类了。
看上去是不是觉得挺有意思的?我也觉得挺有意思的,所以打算写一篇博客介绍一下它。结果博客快写完了,然后在对数据的时候,发现里边表格的数据全是乱来的!!!真实的结果完全不支撑它的结论!!!所以,这篇博客就从“表扬大会”变成了“批评大会”...
18
May
当BERT-whitening引入超参数:总有一款适合你
By 苏剑林 | 2022-05-18 | 26812位读者 | 引用在《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者提出了BERT-whitening,验证了一个线性变换就能媲美当时的SOTA方法BERT-flow。此外,BERT-whitening还可以对句向量进行降维,带来更低的内存占用和更快的检索速度。然而,在《无监督语义相似度哪家强?我们做了个比较全面的评测》中我们也发现,whitening操作并非总能带来提升,有些模型本身就很贴合任务(如经过有监督训练的SimBERT),那么额外的whitening操作往往会降低效果。
为了弥补这个不足,本文提出往BERT-whitening中引入了两个超参数,通过调节这两个超参数,我们几乎可以总是获得“降维不掉点”的结果。换句话说,即便是原来加上whitening后效果会下降的任务,如今也有机会在降维的同时获得相近甚至更好的效果了。
方法概要
目前BERT-whitening的流程是:
\begin{equation}\begin{aligned}
\tilde{\boldsymbol{x}}_i =&\, (\boldsymbol{x}_i - \boldsymbol{\mu})\boldsymbol{U}\boldsymbol{\Lambda}^{-1/2} \\
\boldsymbol{\mu} =&\, \frac{1}{N}\sum\limits_{i=1}^N \boldsymbol{x}_i \\
\boldsymbol{\Sigma} =&\, \frac{1}{N}\sum\limits_{i=1}^N (\boldsymbol{x}_i - \boldsymbol{\mu})^{\top}(\boldsymbol{x}_i - \boldsymbol{\mu}) = \boldsymbol{U}\boldsymbol{\Lambda}\boldsymbol{U}^{\top} \,\,(\text{SVD分解})
\end{aligned}\end{equation}
8
Aug
生成扩散模型漫谈(六):一般框架之ODE篇
By 苏剑林 | 2022-08-08 | 62682位读者 | 引用上一篇文章《生成扩散模型漫谈(五):一般框架之SDE篇》中,我们对宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》做了基本的介绍和推导。然而,顾名思义,上一篇文章主要涉及的是原论文中SDE相关的部分,而遗留了被称为“概率流ODE(Probability flow ODE)”的部分内容,所以本文对此做个补充分享。
事实上,遗留的这部分内容在原论文的正文中只占了一小节的篇幅,但我们需要新开一篇文章来介绍它,因为笔者想了很久后发现,该结果的推导还是没办法绕开Fokker-Planck方程,所以我们需要一定的篇幅来介绍Fokker-Planck方程,然后才能请主角ODE登场。
再次反思
我们来大致总结一下上一篇文章的内容:首先,我们通过SDE来定义了一个前向过程(“拆楼”):
\begin{equation}d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\label{eq:sde-forward}\end{equation}
28
Jun
生成扩散模型漫谈(二十):从ReFlow到WGAN-GP
By 苏剑林 | 2023-06-28 | 14217位读者 | 引用上一篇文章《生成扩散模型漫谈(十九):作为扩散ODE的GAN》中,我们介绍了如何将GAN理解为在另一个时间维度上的扩散ODE,简而言之,GAN实际上就是将扩散模型中样本的运动转化为生成器参数的运动!然而,该文章的推导过程依赖于Wasserstein梯度流等相对复杂和独立的内容,没法很好地跟扩散系列前面的文章连接起来,技术上显得有些“断层”。
在笔者看来,《生成扩散模型漫谈(十七):构建ODE的一般步骤(下)》所介绍的ReFlow是理解扩散ODE的最直观方案,既然可以从扩散ODE的角度理解GAN,那么必定存在一个从ReFlow理解GAN的角度。经过一番尝试,笔者成功从ReFlow推出了类似WGAN-GP的结果。
理论回顾
之所以说“ReFlow是理解扩散ODE的最直观方案”,是因为它本身非常灵活,以及非常贴近实验代码——它能够通过ODE建立任意噪声分布到目标数据分布的映射,而且训练目标非常直观,不需要什么“弯弯绕绕”就可以直接跟实验代码对应起来。
14
Aug
Transformer升级之路:13、逆用Leaky ReRoPE
By 苏剑林 | 2023-08-14 | 12540位读者 | 引用上周在《Transformer升级之路:12、无限外推的ReRoPE?》中,笔者提出了ReRoPE和Leaky ReRoPE,诸多实验结果表明,它们能够在几乎不损失训练效果的情况下免微调地扩展LLM的Context长度,并且实现了“longer context, lower loss”的理想特性,此外跟NTK-aware Scaled RoPE不同的是,其中ReRoPE似乎还有表现出了无限的Context处理能力。
总之,ReRoPE看起来相当让人满意,但美中不足的是会增加推理成本,具体表现为第一步推理需要算两次Attention,以及后续每步推理需要重新计算位置编码。本文试图通过在训练中逆用Leaky ReRoPE的方法来解决这个问题。
回顾
让我们不厌其烦地重温一下:RoPE形式上是一种绝对位置编码,但实际达到的效果是相对位置编码,对应的相对位置矩阵是:
\begin{equation}\begin{pmatrix}0 & \\
1 & 0 & \\
2 & 1 & 0 &\\
3 & 2 & 1 & 0 & \\
\ddots & 3 & 2 & 1 & 0 & \\
\ddots & \ddots & 3 & 2 & 1 & 0 & \\
\ddots & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots \\
\tiny{L - 2} & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots \\
\tiny{L - 1} & \tiny{L - 2} & \ddots & \ddots & \ddots & 3 & 2 & 1 & 0 & \\
\end{pmatrix}\label{eq:rope}\end{equation}

最近评论