






14
Oct
【理解黎曼几何】1. 一条几何之路
By 苏剑林 | 2016-10-14 | 80864位读者 | 引用一个月没更新了,这个月花了不少时间在黎曼几何的理解方面,有一些体会,与大家分享。记得当初孟岩写的《理解矩阵》,和笔者所写的《新理解矩阵》,读者反响都挺不错的,这次沿用了这个名称,称之为《理解黎曼几何》。

生活在二维空间的蚂蚁
黎曼几何是研究内蕴几何的几何分支。通俗来讲,就是我们可能生活在弯曲的空间中,比如一只生活在二维球面的蚂蚁,作为生活在弯曲空间中的个体,我们并没有足够多的智慧去把我们的弯曲嵌入到更高维的空间中去研究,就好比蚂蚁只懂得在球面上爬,不能从“三维空间的曲面”这一观点来认识球面,因为球面就是它们的世界。因此,我们就有了内蕴几何,它告诉我们,即便是身处弯曲空间中,我们依旧能够测量长度、面积、体积等,我们依旧能够算微分、积分,甚至我们能够发现我们的空间是弯曲的!也就是说,身处球面的蚂蚁,只要有足够的智慧,它们就能发现曲面是弯曲的——跟哥伦布环球航行那样——它们朝着一个方向走,最终却回到了起点,这就可以断定它们自身所处的空间必然是弯曲的——这个发现不需要用到三维空间的知识。
15
Oct
【理解黎曼几何】3. 测地线
By 苏剑林 | 2016-10-15 | 55700位读者 | 引用测地线
黎曼度量应该是不难理解的,在微分几何的教材中,我们就已经学习过曲面的“第一基本形式”了,事实上两者是同样的东西,只不过看待问题的角度不同,微分几何是把曲面看成是三维空间中的二维子集,而黎曼几何则是从二维曲面本身内蕴地研究几何问题。
几何关心什么问题呢?事实上,几何关心的是与变换无关的“客观实体”(或者说是在变换之下不变的东西),这也是几何的定义。根据Klein提出的《埃尔朗根纲领》,几何就是研究在某种变换(群)下的不变性质的学科。如果把变换局限为刚性变换(平移、旋转、反射),那么就是欧式几何;如果变换为一般的线性变换,那就是仿射几何。而黎曼几何关心的是与一切坐标都无关的客观实体。比如说,我有一个向量,方向和大小都确定了,在直角坐标系是$(1, 1)$,在极坐标系是$(\sqrt{2}, \pi/4)$,虽然两个坐标系下的分量不同,但它们都是指代同一个向量。也就是说向量本身是客观存在的实体,跟所使用的坐标无关。从代数层面看,就是只要能够通过某种坐标变换相互得到的,我们就认为它们是同一个东西。
因此,在学习黎曼几何时,往“客观实体”方向思考,总是有益的。

平面上的测地线
有了度规,可以很自然地引入“测地线”这一实体。狭义来看,它就是两点间的最短线——是平直空间的直线段概念的推广(实际的测地线不一定是最短的,但我们先不纠结细节,而且这不妨碍我们理解它,因为测地线至少是局部最短的)。不难想到,只要两点确定了,那么不管使用什么坐标,两点间的最短线就已经确定了,因此这显然是一个客观实体。有一个简单的类比,就是不管怎么坐标变换,一个函数$f(x)$的图像极值点总是确定的——不管你变还是不变,它就在那儿,不偏不倚。
2
Nov
【理解黎曼几何】8. 处处皆几何 (力学几何化)
By 苏剑林 | 2016-11-02 | 58098位读者 | 引用黎曼几何在广义相对论中的体现和应用,虽然不能说家喻户晓,但想必大部分读者都有所听闻。一谈到黎曼几何在物理学中的应用,估计大家的第一反应就是广义相对论。常见的观点是,广义相对论的发现大大推动了黎曼几何的发展。诚然,这是事实,然而,大多数人不知道的事,哪怕经典的牛顿力学中,也有黎曼几何的身影。
本文要谈及的内容,就是如何将力学几何化,从而使用黎曼几何的概念来描述它们。整个过程事实上是提供了一种框架,它可以将不少其他领域的理论纳入到黎曼几何体系中。
黎曼几何的出发点就是黎曼度量,通过黎曼度量可以通过变分得到测地线。从这个意义上来看,黎曼度量提供了一个变分原理。那反过来,一个变分原理,能不能提供一个黎曼度量呢?众所周知,不少学科的基础原理都可以归结为一个极值原理,而有了极值原理就不难导出变分原理(泛函极值),如物理中就有最小作用量原理、最小势能原理,概率论中有最大熵原理,等等。如果有一个将变分原理导出黎曼度量的方法,那么就可以用几何的方式来描述它。幸运的是,对于二次型的变分原理,是可以做到的。
19
Oct
【理解黎曼几何】6. 曲率的计数与计算(Python)
By 苏剑林 | 2016-10-19 | 53198位读者 | 引用曲率的独立分量
黎曼曲率张量是一个非常重要的张量,当且仅当它全部分量为0时,空间才是平直的。它也出现在爱因斯坦的场方程中。总而言之,只要涉及到黎曼几何,黎曼曲率张量就必然是核心内容。
已经看到,黎曼曲率张量有4个指标,这也意味着它有$n^4$个分量,$n$是空间的维数。那么在2、3、4维空间中,它就有16、81、256个分量了,可见,要计算它,是一件相当痛苦的事情。幸好,这个张量有很多的对称性质,使得独立分量的数目大大减少,我们来分析这一点。
首先我们来导出黎曼曲率张量的一些对称性质,这部分内容是跟经典教科书是一致的。定义
$$R_{\mu\alpha\beta\gamma}=g_{\mu\nu}R^{\nu}_{\alpha\beta\gamma} \tag{50} $$
定义这个量的原因,要谈及逆变张量和协变张量的区别,我们这里主要关心几何观,因此略过对张量的详细分析。这个量被称为完全协变的黎曼曲率张量,有时候也直接叫做黎曼曲率张量,只要不至于混淆,一般不做区分。通过略微冗长的代数运算(在一般的微分几何、黎曼几何或者广义相对论教材中都有),可以得到
$$\begin{aligned}&R_{\mu\alpha\beta\gamma}=-R_{\mu\alpha\gamma\beta}\\
&R_{\mu\alpha\beta\gamma}=-R_{\alpha\mu\beta\gamma}\\
&R_{\mu\alpha\beta\gamma}=R_{\beta\gamma\mu\alpha}\\
&R_{\mu\alpha\beta\gamma}+R_{\mu\beta\gamma\alpha}+R_{\mu\gamma\alpha\beta}=0
\end{aligned} \tag{51} $$
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 212895位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
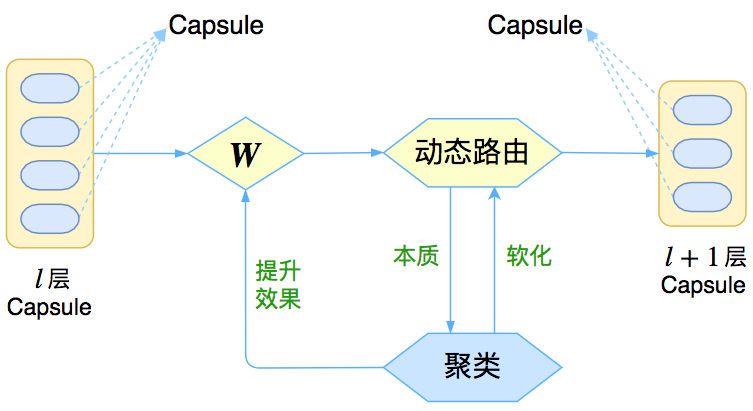
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
15
Mar
从最大似然到EM算法:一致的理解方式
By 苏剑林 | 2018-03-15 | 142857位读者 | 引用最近在思考NLP的无监督学习和概率图相关的一些内容,于是重新把一些参数估计方法理了一遍。在深度学习中,参数估计是最基本的步骤之一了,也就是我们所说的模型训练过程。为了训练模型就得有个损失函数,而如果没有系统学习过概率论的读者,能想到的最自然的损失函数估计是平均平方误差,它也就是对应于我们所说的欧式距离。而理论上来讲,概率模型的最佳搭配应该是“交叉熵”函数,它来源于概率论中的最大似然函数。
最大似然
合理的存在
何为最大似然?哲学上有句话叫做“存在就是合理的”,最大似然的意思是“存在就是最合理的”。具体来说,如果事件$X$的概率分布为$p(X)$,如果一次观测中具体观测到的值分别为$X_1,X_2,\dots,X_n$,并假设它们是相互独立,那么
$$\mathcal{P} = \prod_{i=1}^n p(X_i)\tag{1}$$
是最大的。如果$p(X)$是一个带有参数$\theta$的概率分布式$p_{\theta}(X)$,那么我们应当想办法选择$\theta$,使得$\mathcal{L}$最大化,即
$$\theta = \mathop{\text{argmax}}_{\theta} \mathcal{P}(\theta) = \mathop{\text{argmax}}_{\theta}\prod_{i=1}^n p_{\theta}(X_i)\tag{2}$$
29
Sep
f-GAN简介:GAN模型的生产车间
By 苏剑林 | 2018-09-29 | 150901位读者 | 引用今天介绍一篇比较经典的工作,作者命名为f-GAN,他在文章中给出了通过一般的$f$散度来构造一般的GAN的方案。可以毫不夸张地说,这论文就是一个GAN模型的“生产车间”,它一般化的囊括了很多GAN变种,并且可以启发我们快速地构建新的GAN变种(当然有没有价值是另一回事,但理论上是这样)。
局部变分
整篇文章对$f$散度的处理事实上在机器学习中被称为“局部变分方法”,它是一种非常经典且有用的估算技巧。事实上本文将会花大部分篇幅介绍这种估算技巧在$f$散度中的应用结果。至于GAN,只不过是这个结果的基本应用而已。
f散度
首先我们还是对$f$散度进行基本的介绍。所谓$f$散度,是KL散度的一般化:
$$\begin{equation}\mathcal{D}_f(P\Vert Q) = \int q(x) f\left(\frac{p(x)}{q(x)}\right)dx\label{eq:f-div}\end{equation}$$
注意,按照通用的约定写法,括号内是$p/q$而不是$q/p$,大家不要自然而言地根据KL散度的形式以为是$q/p$。
22
Oct
RSGAN:对抗模型中的“图灵测试”思想
By 苏剑林 | 2018-10-22 | 125456位读者 | 引用这两天无意间发现一个非常有意义的工作,称为“相对GAN”,简称RSGAN,来自文章《The relativistic discriminator: a key element missing from standard GAN》,据说该文章还得到了GAN创始人Goodfellow的点赞。这篇文章提出了用相对的判别器来取代标准GAN原有的判别器,使得生成器的收敛更为迅速,训练更为稳定。
可惜的是,这篇文章仅仅从训练和实验角度对结果进行了论述,并没有进行更深入的分析,以至于不少人觉得这只是GAN训练的一个trick。但是在笔者来看,RSGAN具有更为深刻的含义,甚至可以看成它已经开创了一个新的GAN流派。所以,笔者决定对RSGAN模型及其背后的内涵做一个基本的介绍。不过需要指出的是,除了结果一样之外,本文的介绍过程跟原论文相比几乎没有重合之处。
“图灵测试”思想
SGAN
SGAN就是标准的GAN(Standard GAN)。就算没有做过GAN研究的读者,相信也从各种渠道了解到GAN的大概原理:“造假者”不断地进行造假,试图愚弄“鉴别者”;“鉴别者”不断提高鉴别技术,以分辨出真品和赝品。两者相互竞争,共同进步,直到“鉴别者”无法分辨出真、赝品了,“造假者”就功成身退了。
在建模时,通过交替训练实现这个过程:固定生成器,训练一个判别器(二分类模型),将真实样本输出1,将伪造样本输出0;然后固定判别器,训练生成器让伪造样本尽可能输出1,后面这一步不需要真实样本参与。
问题所在
然而,这个建模过程似乎对判别器的要求过于苛刻了,因为判别器是孤立运作的:训练生成器时,真实样本没有参与,所以判别器必须把关于真实样本的所有属性记住,这样才能指导生成器生成更真实的样本。

最近评论