






24
Mar
基于CNN和VAE的作诗机器人:随机成诗
By 苏剑林 | 2018-03-24 | 122799位读者 | 引用前几日写了一篇VAE的通俗解读,也得到了一些读者的认可。然而,你是否厌倦了每次介绍都只有一个MNIST级别的demo?不要急,这就给大家带来一个更经典的VAE玩具:机器人作诗。
为什么说“更经典”呢?前一篇文章我们说过用VAE生成的图像相比GAN生成的图像会偏模糊,也就是在图像这一“仗”上,VAE是劣势。然而,在文本生成这一块上,VAE却漂亮地胜出了。这是因为GAN希望把判别器(度量)也直接训练出来,然而对于文本来说,这个度量很可能是离散的、不可导的,因此纯GAN就很难训练了。而VAE中没有这个步骤,它是通过重构输入来完成的,这个重构过程对于图像还是文本都可以进行。所以,文本生成这件事情,对于VAE来说它就跟图像生成一样,都是一个基本的、直接的应用;对于(目前的)GAN来说,却是艰难的象征,是它挥之不去的“心病”。
嗯,古有曹植七步作诗,今有VAE随机成诗,让我们开始吧~
模型
对于很多人来说,诗是一个很美妙的玩意,美妙之处在于大多数人都不真正懂得诗,但大家对诗的模样又有一知半解的认识。因此,只要生成的“诗”稍微像模像样一点,我们通常都会认为机器人可以作诗了。因此,所谓作诗机器人,是一个纯粹的玩具了,能作几句诗,也不意味着普通语言的生成能力有多好,也不意味着我们对NLP的理解有多深。
CNN + VAE
就本文的玩具而言,其实是一个比较简单的模型,主要是把一维CNN和VAE结合了起来。因为生成的诗长度是固定的,所以不管是encoder还是decoder,我都只是用了纯CNN来做。模型的结构图大概是:
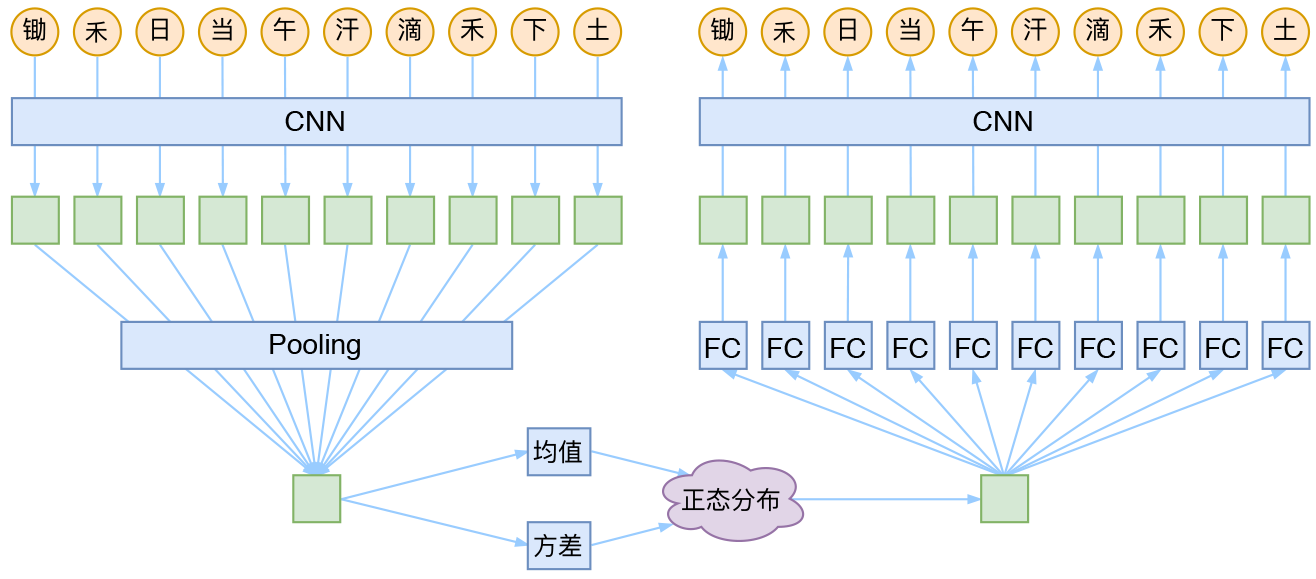
cnn + vae 诗歌生成模型
15
Mar
从最大似然到EM算法:一致的理解方式
By 苏剑林 | 2018-03-15 | 142631位读者 | 引用最近在思考NLP的无监督学习和概率图相关的一些内容,于是重新把一些参数估计方法理了一遍。在深度学习中,参数估计是最基本的步骤之一了,也就是我们所说的模型训练过程。为了训练模型就得有个损失函数,而如果没有系统学习过概率论的读者,能想到的最自然的损失函数估计是平均平方误差,它也就是对应于我们所说的欧式距离。而理论上来讲,概率模型的最佳搭配应该是“交叉熵”函数,它来源于概率论中的最大似然函数。
最大似然
合理的存在
何为最大似然?哲学上有句话叫做“存在就是合理的”,最大似然的意思是“存在就是最合理的”。具体来说,如果事件$X$的概率分布为$p(X)$,如果一次观测中具体观测到的值分别为$X_1,X_2,\dots,X_n$,并假设它们是相互独立,那么
$$\mathcal{P} = \prod_{i=1}^n p(X_i)\tag{1}$$
是最大的。如果$p(X)$是一个带有参数$\theta$的概率分布式$p_{\theta}(X)$,那么我们应当想办法选择$\theta$,使得$\mathcal{L}$最大化,即
$$\theta = \mathop{\text{argmax}}_{\theta} \mathcal{P}(\theta) = \mathop{\text{argmax}}_{\theta}\prod_{i=1}^n p_{\theta}(X_i)\tag{2}$$
31
May
基于最小熵原理的NLP库:nlp zero
By 苏剑林 | 2018-05-31 | 101218位读者 | 引用陆陆续续写了几篇最小熵原理的博客,致力于无监督做NLP的一些基础工作。为了方便大家实验,把文章中涉及到的一些算法封装为一个库,供有需要的读者测试使用。
由于面向的是无监督NLP场景,而且基本都是NLP任务的基础工作,因此命名为nlp zero。
地址
Github: https://github.com/bojone/nlp-zero
Pypi: https://pypi.org/project/nlp-zero/
可以直接通过
pip install nlp-zero==0.1.6进行安装。整个库纯Python实现,没有第三方调用,支持Python2.x和3.x。
21
Sep
细水长flow之f-VAEs:Glow与VAEs的联姻
By 苏剑林 | 2018-09-21 | 132182位读者 | 引用这篇文章是我们前几天挂到arxiv上的论文的中文版。在这篇论文中,我们给出了结合流模型(如前面介绍的Glow)和变分自编码器的一种思路,称之为f-VAEs。理论可以证明f-VAEs是囊括流模型和变分自编码器的更一般的框架,而实验表明相比于原始的Glow模型,f-VAEs收敛更快,并且能在更小的网络规模下达到同样的生成效果。
原文地址:《f-VAEs: Improve VAEs with Conditional Flows》
近来,生成模型得到了广泛关注,其中变分自编码器(VAEs)和流模型是不同于生成对抗网络(GANs)的两种生成模型,它们亦得到了广泛研究。然而它们各有自身的优势和缺点,本文试图将它们结合起来。

由f-VAEs实现的两个真实样本之间的线性插值
基础
设给定数据集的证据分布为$\tilde{p}(x)$,生成模型的基本思路是希望用如下的分布形式来拟合给定数据集分布
$$\begin{equation}q(x)=\int q(z)q(x|z) dz\end{equation}$$
26
Dec
【学习清单】最近比较重要的GAN进展论文
By 苏剑林 | 2018-12-26 | 64518位读者 | 引用这篇文章简单列举一下我认为最近这段时间中比较重要的GAN进展论文,这基本也是我在学习GAN的过程中主要去研究的论文清单。
生成模型之味
GAN是一个大坑,尤其像我这样的业余玩家,一头扎进去很久也很难有什么产出,尤其是各个大公司拼算力搞出来一个个大模型,个人几乎都没法玩了。但我总觉得,真的去碰了生成模型,才觉得自己碰到了真正的机器学习。这一点,不管在图像中还是文本中都是如此。所以,我还是愿意去关注生成模型。
当然,GAN不是生成模型的唯一选择,却是一个非常有趣的选择。在图像中至少有GAN、flow、pixelrnn/pixelcnn这几种选择,但要说潜力,我还是觉得GAN才是最具前景的,不单是因为效果,主要是因为它那对抗的思想。而在文本中,事实上seq2seq机制就是一个概率生成模型了,而pixelrnn这类模型,实际上就是模仿着seq2seq来做的,当然也有用GAN做文本生成的研究(不过基本上都涉及到了强化学习)。也就是说,其实在NLP中,生成模型也有很多成果,哪怕你主要是研究NLP的,也终将碰到生成模型。
好了,话不多说,还是赶紧把清单列一列,供大家参考,也作为自己的备忘。
15
Feb
能量视角下的GAN模型(二):GAN=“分析”+“采样”
By 苏剑林 | 2019-02-15 | 128831位读者 | 引用在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
上一篇文章里,我们给出了一个直白而用力的能量图景,这个图景可以让我们轻松理解GAN的很多内容,换句话说,通俗的解释已经能让我们完成大部分的理解了,并且把最终的结论都已经写了出来。在这篇文章中,我们继续从能量的视角理解GAN,这一次,我们争取把前面简单直白的描述,用相对严密的数学语言推导一遍。
跟第一篇文章一样,对于笔者来说,这个推导过程依然直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》。
原作者的开源实现:https://github.com/ritheshkumar95/energy_based_generative_models
本文的大致内容如下:
1、推导了能量分布下的正负相对抗的更新公式;
2、比较了理论分析与实验采样的区别,而将两者结合便得到了GAN框架;
3、导出了生成器的补充loss,理论上可以防止mode collapse;
4、简单提及了基于能量函数的MCMC采样。
27
Jan
“让Keras更酷一些!”:随意的输出和灵活的归一化
By 苏剑林 | 2019-01-27 | 100803位读者 | 引用继续“让Keras更酷一些!”系列,让Keras来得更有趣些吧~
这次围绕着Keras的loss、metric、权重和进度条进行展开。
可以不要输出
一般我们用Keras定义一个模型,是这样子的:
x_in = Input(shape=(784,))
x = x_in
x = Dense(100, activation='relu')(x)
x = Dense(10, activation='softmax')(x)
model = Model(x_in, x)
model.compile(loss='categorical_crossentropy ',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 112298位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
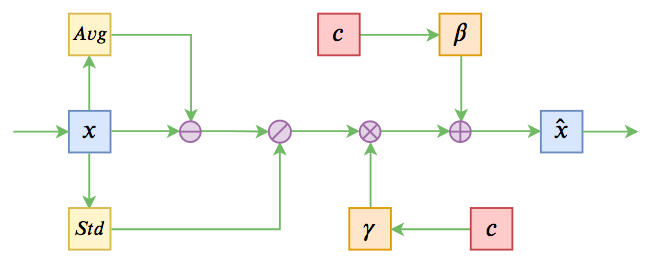
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。

最近评论