






7
May
Cool Papers更新:简单搭建了一个站内检索系统
By 苏剑林 | 2024-05-07 | 50349位读者 | 引用自从《更便捷的Cool Papers打开方式:Chrome重定向扩展》之后,Cool Papers有两次比较大的变化,一次是引入了venue分支,逐步收录了一些会议历年的论文集,如ICLR、ICML等,这部分是动态人工扩充的,欢迎有心仪的会议的读者提更多需求;另一次就是本文的主题,前天新增加的站内检索功能。
本文将简单介绍一下新增功能,并对搭建站内检索系统的过程做个基本总结。
简介
在Cool Papers的首页,我们看到搜索入口:

Cool Papers(2024.05.07)
18
Mar
时空之章:将Attention视为平方复杂度的RNN
By 苏剑林 | 2024-03-18 | 54693位读者 | 引用近年来,RNN由于其线性的训练和推理效率,重新吸引了不少研究人员和用户的兴趣,隐约有“文艺复兴”之势,其代表作有RWKV、RetNet、Mamba等。当将RNN用于语言模型时,其典型特点就是每步生成都是常数的空间复杂度和时间复杂度,从整个序列看来就是常数的空间复杂度和线性的时间复杂度。当然,任何事情都有两面性,相比于Attention动态增长的KV Cache,RNN的常数空间复杂度通常也让人怀疑记忆容量有限,在Long Context上的效果很难比得上Attention。
在这篇文章中,我们表明Causal Attention可以重写成RNN的形式,并且它的每一步生成理论上也能够以O(1)的空间复杂度进行(代价是时间复杂度非常高,远超平方级)。这表明Attention的优势(如果有的话)是靠计算堆出来的,而不是直觉上的堆内存,它跟RNN一样本质上都是常数量级的记忆容量(记忆瓶颈)。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 29998位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
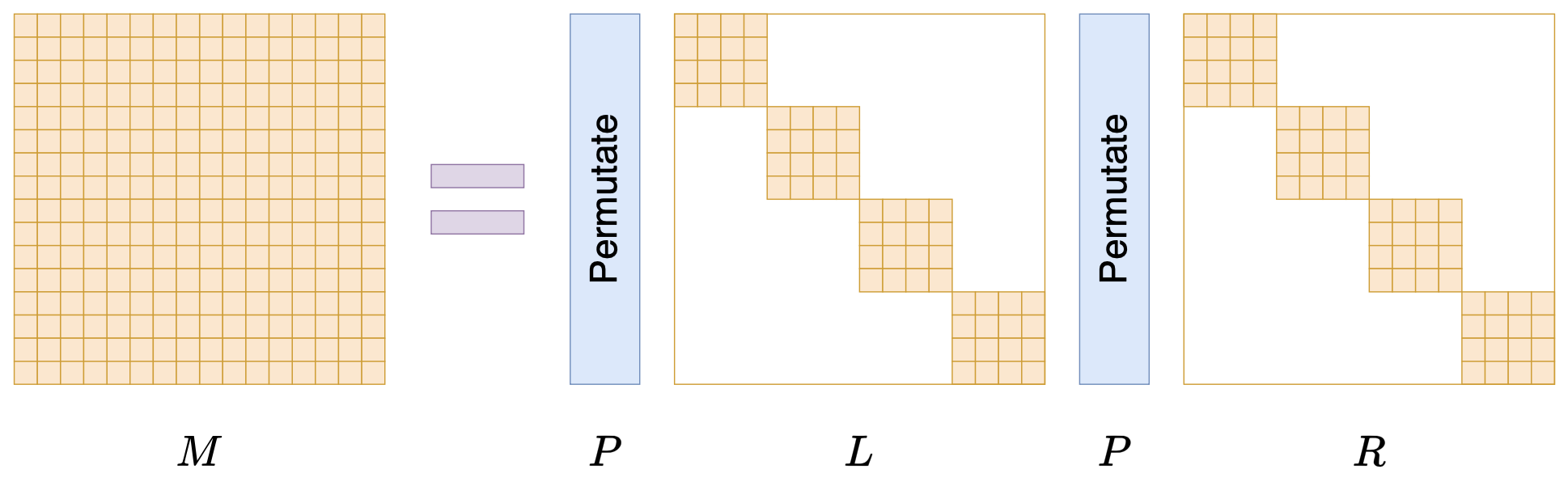
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
6
Aug
通向最优分布之路:概率空间的最小化
By 苏剑林 | 2024-08-06 | 23267位读者 | 引用当要求函数的最小值时,我们通常会先求导函数然后寻找其零点,比较幸运的情况下,这些零点之一正好是原函数的最小值点。如果是向量函数,则将导数改为梯度并求其零点。当梯度零点不易求得时,我们可以使用梯度下降来逐渐逼近最小值点。
以上这些都是无约束优化的基础结果,相信不少读者都有所了解。然而,本文的主题是概率空间中的优化,即目标函数的输入是一个概率分布,这类目标的优化更为复杂,因为它的搜索空间不再是无约束的,如果我们依旧去求解梯度零点或者执行梯度下降,所得结果未必能保证是一个概率分布。因此,我们需要寻找一种新的分析和计算方法,以确保优化结果能够符合概率分布的特性。
对此,笔者一直以来也感到颇为头疼,所以近来决定”痛定思痛“,针对概率分布的优化问题系统学习了一番,最后将学习所得整理在此,供大家参考。
29
Jul
对齐全量微调!这是我看过最精彩的LoRA改进(二)
By 苏剑林 | 2024-07-29 | 30120位读者 | 引用前两周笔者写了《对齐全量微调!这是我看过最精彩的LoRA(一)》(当时还没有编号“一”),里边介绍了一个名为“LoRA-GA”的LoRA变体,它通过梯度SVD来改进LoRA的初始化,从而实现LoRA与全量微调的对齐。当然,从理论上来讲,这样做也只能尽量对齐第一步更新后的W1,所以当时就有读者提出了“后面的W2,W3,⋯不管了吗?”的疑问,当时笔者也没想太深入,就单纯觉得对齐了第一步后,后面的优化也会严格一条较优的轨迹走。
有趣的是,LoRA-GA才出来没多久,arXiv上就新出了《LoRA-Pro: Are Low-Rank Adapters Properly Optimized?》,其所提的LoRA-Pro正好能回答这个问题!LoRA-Pro同样是想着对齐全量微调,但它对齐的是每一步梯度,从而对齐整条优化轨迹,这正好是跟LoRA-GA互补的改进点。
对齐全量
本文接着上一篇文章的记号和内容进行讲述,所以这里仅对上一节的内容做一个简单回顾,不再详细重复介绍。LoRA的参数化方式是
W=(W0−A0B0)+AB
12
Aug
“Cool Papers + 站内搜索”的一些新尝试
By 苏剑林 | 2024-08-12 | 18190位读者 | 引用在《Cool Papers更新:简单搭建了一个站内检索系统》这篇文章中,我们介绍了Cool Papers新增的站内搜索系统。搜索系统的目的,自然希望能够帮助用户快速找到他们需要的论文。然而,如何高效地检索到对自己有价值的结果,并不是一件简单的事情,这里边往往需要一些技巧,比如精准提炼关键词。
这时候算法的价值就体现出来了,有些步骤人工来做会比较繁琐,但用算法来却很简单。所以接下来,我们将介绍几点通过算法来提高Cool Papers的搜索和筛选论文效率的新尝试。
相关论文
站内搜索背后的技术是全文检索引擎(Full-text Search Engine),简单来说,这就是一个基于关键词匹配的搜索算法,其相似度指标是BM25。
11
Oct
低秩近似之路(三):CR
By 苏剑林 | 2024-10-11 | 21265位读者 | 引用在《低秩近似之路(二):SVD》中,我们证明了SVD可以给出任意矩阵的最优低秩近似。那里的最优近似是无约束的,也就是说SVD给出的结果只管误差上的最小,不在乎矩阵的具体结构,而在很多应用场景中,出于可解释性或者非线性处理等需求,我们往往希望得到具有某些特殊结构的近似分解。
因此,从这篇文章开始,我们将探究一些具有特定结构的低秩近似,而本文将聚焦于其中的CR近似(Column-Row Approximation),它提供了加速矩阵乘法运算的一种简单方案。
问题背景
矩阵的最优r秩近似的一般提法是
argminrank(˜M)≤r‖˜M−M‖2F
12
Jan
低秩近似之路(五):CUR
By 苏剑林 | 2025-01-12 | 16180位读者 | 引用再次回到低秩近似之路上。在《低秩近似之路(四):ID》中,我们介绍了“插值分解(Interpolative Decomposition,ID)”,这是为矩阵M∈Rn×m寻找CZ形式的近似的过程,其中C∈Rn×r是矩阵M的若干列,而Z∈Rr×m是任意矩阵。
这篇文章我们将介绍CUR分解,它跟插值分解的思想一脉相承,都是以原始矩阵的行、列为“骨架”来构建原始矩阵的近似,跟ID只用行或列之一不同,CUR分解同时用到了行和列。
基本定义
其实这不是本站第一次出现CUR分解了。早在《Nyströmformer:基于矩阵分解的线性化Attention方案》我们就介绍过矩阵的Nyström近似,它实际上就是CUR分解,后来在《利用CUR分解加速交互式相似度模型的检索》还介绍了CUR分解在降低交互式相似度模型的检索复杂度的应用。

最近评论