






18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 1373229位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量$Z$生成目标数据$X$的模型,但是实现上有所不同。更准确地讲,它们是假设了$Z$服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型$X=g(Z)$,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
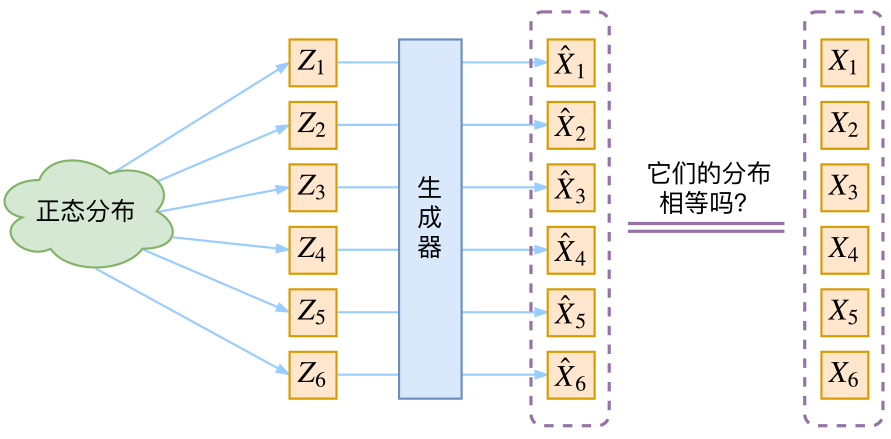
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
15
Mar
从最大似然到EM算法:一致的理解方式
By 苏剑林 | 2018-03-15 | 217884位读者 | 引用最近在思考NLP的无监督学习和概率图相关的一些内容,于是重新把一些参数估计方法理了一遍。在深度学习中,参数估计是最基本的步骤之一了,也就是我们所说的模型训练过程。为了训练模型就得有个损失函数,而如果没有系统学习过概率论的读者,能想到的最自然的损失函数估计是平均平方误差,它也就是对应于我们所说的欧式距离。而理论上来讲,概率模型的最佳搭配应该是“交叉熵”函数,它来源于概率论中的最大似然函数。
最大似然
合理的存在
何为最大似然?哲学上有句话叫做“存在就是合理的”,最大似然的意思是“存在就是最合理的”。具体来说,如果事件$X$的概率分布为$p(X)$,如果一次观测中具体观测到的值分别为$X_1,X_2,\dots,X_n$,并假设它们是相互独立,那么
$$\mathcal{P} = \prod_{i=1}^n p(X_i)\tag{1}$$
是最大的。如果$p(X)$是一个带有参数$\theta$的概率分布式$p_{\theta}(X)$,那么我们应当想办法选择$\theta$,使得$\mathcal{L}$最大化,即
$$\theta = \mathop{\text{argmax}}_{\theta} \mathcal{P}(\theta) = \mathop{\text{argmax}}_{\theta}\prod_{i=1}^n p_{\theta}(X_i)\tag{2}$$
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 268723位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
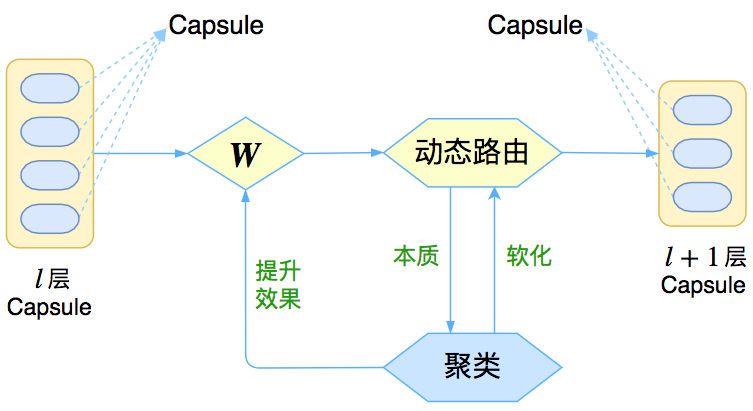
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
12
Feb
再来一顿贺岁宴:从K-Means到Capsule
By 苏剑林 | 2018-02-12 | 277940位读者 | 引用在本文中,我们再次对Capsule进行一次分析。
整体上来看,Capsule算法的细节不是很复杂,对照着它的流程把Capsule用框架实现它基本是没问题的。所以,困难的问题是理解Capsule究竟做了什么,以及为什么要这样做,尤其是Dynamic Routing那几步。
为什么我要反复对Capsule进行分析?这并非单纯的“炒冷饭”,而是为了得到对Capsule原理的理解。众所周知,Capsule给人的感觉就是“有太多人为约定的内容”,没有一种“虽然我不懂,但我相信应该就是这样”的直观感受。我希望尽可能将Capsule的来龙去脉思考清楚,使我们能觉得Capsule是一个自然、流畅的模型,甚至对它举一反三。
在《揭开迷雾,来一顿美味的Capsule盛宴》中,笔者先分析了动态路由的结果,然后指出输出是输入的某种聚类,这个“从结果到原因”的过程多多少少有些望文生义的猜测成分;这次则反过来,直接确认输出是输入的聚类,然后反推动态路由应该是怎样的,其中含糊的成分大大减少。两篇文章之间有一定的互补作用。
30
Jan
【分享】千万级百度知道语料
By 苏剑林 | 2018-01-30 | 102311位读者 | 引用发布
2018年01月30日
数目
共1千万条
格式
[
{
"url": "http://zhidao.baidu.com/question/565618371557484884.html",
"question": "学文员有哪些专科学校",
"tags": [
"学校",
"专科",
"院校信息"
]
},
{
"url": "http://zhidao.baidu.com/question/2079794100345438428.html",
"question": "网赌和澳门赌有区别吗",
"tags": [
"网络",
"澳门",
"赌博"
]
}
]
29
Jan
网站更新记录(2018年01月)
By 苏剑林 | 2018-01-29 | 36541位读者 | 引用也许读者会发现,这几天访问科学空间可能出现不稳定的情况,原因是我这几天都在对网站进行调整。
这次的调整幅度很大,不过从外表上可能很难发现,特此记录留念一下。主要的更新内容包括:
1、主题的优化:本博客用的geekg主题其实比较老了,去年花钱请人对它进行了第一次大升级,加入了响应式设计,这几天主要解决该主题的一些历史遗留问题,包括图片显示、边距、排版等细微调整;
2、内部的优化:大幅度减少了插件的使用,把一些基本的功能(如网站目录、归档页)等都内嵌到主题中,减少了对插件的依赖,也提升了可用性;
3、文章的优化:其实这也是个历史遗留问题,主要是早期写文章的时候比较随意,html代码、公式的LaTeX代码等都不规范,因此早期的文章显示效果可能比较糟糕,于是我就做了一件很疯狂的事情——把800多篇文章都过一遍!经过了两天多的时间,基本上修复了早期文章的大部分问题;
4、域名的优化:网站全面使用https!网站放在阿里云上面,可是阿里云有一套自以为是的监管系统,无故屏蔽我的一些页面。为了应对阿里云的恶意屏蔽,只好转向https,当然,这不会对读者平时访问造成影响,因为跳转https是自动的。目前两个域名spaces.ac.cn和kexue.fm都会自动跳转到https。
28
Jan
【理科生读小说】来谈谈“四两拨千斤”
By 苏剑林 | 2018-01-28 | 45261位读者 | 引用多彩金庸
在金庸笔下(其实很多武侠小说都如此),武功可以分三种:第一种是实打实的猛,如洪七公的降龙十八掌、金轮法王的龙象般若功等,它们的特点是主要特点是刚猛,比如
乔峰的降龙二十八掌是丐帮前任帮主汪剑通所传,但乔峰生俱异禀,于武功上得天独厚,他这降龙二十八掌摧枯拉朽,无坚不破,较之汪帮主尤有胜过。乔峰见对方双掌齐推,自己如以单掌相抵,倘若拼成平手,自己似乎稍占上风,不免有失恭敬,于是也双掌齐出。他左右双掌中所使掌力,也仍都是外三内七,将大部分掌力留劲不发。
——出自《天龙八部》世纪新修版
第二种是以虚招为主,也就是说你不能比对手猛,你骗倒对手也行,比如桃花岛的落英神剑掌:
这套掌法是黄药师观赏桃花岛中桃花落英缤纷而创制,出招变化多端,还讲究姿势之美。她双臂挥动,四方八面都是掌影,或五虚一实,或八虚一实,直似桃林中狂风忽起、万花齐落,妙在手足飘逸,宛若翩翩起舞,但她一来功力尚浅,二来心存顾惜,未能出掌凌厉如剑。郭靖眼花缭乱,哪里还守得住门户,不提防啪啪啪啪,左肩右肩、前胸后背,接连中了四掌,黄蓉全未使力,郭靖自也不觉疼痛。
——出自《射雕英雄传》世纪新修版
第三种是以巧招为主,它不求一味刚猛,也不一味虚虚实实,而且讲究用力恰到好处,起到“以柔克刚”、“四两拨千斤”之效。显然,这种武功的代表作是太极,另外打狗棒法、乾坤大挪移、还有全真教和古墓派的武功也暗含了这个道理,比如:
23
Jan
揭开迷雾,来一顿美味的Capsule盛宴
By 苏剑林 | 2018-01-23 | 544152位读者 | 引用
Geoffrey Hinton在谷歌多伦多办公室
由深度学习先驱Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,无疑是去年深度学习界最热点的消息之一。得益于各种媒体的各种吹捧,Capsule被冠以了各种神秘的色彩,诸如“抛弃了梯度下降”、“推倒深度学习重来”等字眼层出不穷,但也有人觉得Capsule不外乎是一个新的炒作概念。
本文试图揭开让人迷惘的云雾,领悟Capsule背后的原理和魅力,品尝这一顿Capsule盛宴。同时,笔者补做了一个自己设计的实验,这个实验能比原论文的实验更有力说明Capsule的确产生效果了。
菜谱一览:
1、Capsule是什么?
2、Capsule为什么要这样做?
3、Capsule真的好吗?
4、我觉得Capsule怎样?
5、若干小菜。

最近评论