






8
Mar
Transformer升级之路:1、Sinusoidal位置编码追根溯源
By 苏剑林 | 2021-03-08 | 268075位读者 |最近笔者做了一些理解和改进Transformer的尝试,得到了一些似乎还有价值的经验和结论,遂开一个专题总结一下,命名为“Transformer升级之路”,既代表理解上的深入,也代表结果上的改进。
作为该专题的第一篇文章,笔者将会介绍自己对Google在《Attention is All You Need》中提出来的Sinusoidal位置编码
\begin{equation}\left\{\begin{aligned}&\boldsymbol{p}_{k,2i}=\sin\Big(k/10000^{2i/d}\Big)\\
&\boldsymbol{p}_{k, 2i+1}=\cos\Big(k/10000^{2i/d}\Big)
\end{aligned}\right.\label{eq:sin}\end{equation}
的新理解,其中$\boldsymbol{p}_{k,2i},\boldsymbol{p}_{k,2i+1}$分别是位置$k$的编码向量的第$2i,2i+1$个分量,$d$是向量维度。
作为位置编码的一个显式解,Google在原论文中对它的描述却寥寥无几,只是简单提及了它可以表达相对位置信息,后来知乎等平台上也出现了一些解读,它的一些特点也逐步为大家所知,但总体而言比较零散。特别是对于“它是怎么想出来的”、“非得要这个形式不可吗”等原理性问题,还没有比较好的答案。
因此,本文主要围绕这些问题展开思考,可能在思考过程中读者会有跟笔者一样的感觉,即越思考越觉得这个设计之精妙漂亮,让人叹服~
泰勒展开 #
假设我们的模型为$f(\cdots,\boldsymbol{x}_m,\cdots,\boldsymbol{x}_n,\cdots)$,其中标记出来的$\boldsymbol{x}_m,\boldsymbol{x}_n$分别表示第$m,n$个输入,不失一般性,设$f$是标量函数。对于不带Attention Mask的纯Attention模型,它是全对称的,即对于任意的$m,n$,都有
\begin{equation}f(\cdots,\boldsymbol{x}_m,\cdots,\boldsymbol{x}_n,\cdots)=f(\cdots,\boldsymbol{x}_n,\cdots,\boldsymbol{x}_m,\cdots)\end{equation}
这就是我们说Transformer无法识别位置的原因——全对称性,简单来说就是函数天然满足恒等式$f(x,y)=f(y,x)$,以至于我们无法从结果上区分输入是$[x,y]$还是$[y,x]$。
因此,我们要做的事情,就是要打破这种对称性,比如在每个位置上都加上一个不同的编码向量:
\begin{equation}\tilde{f}(\cdots,\boldsymbol{x}_m,\cdots,\boldsymbol{x}_n,\cdots)=f(\cdots,\boldsymbol{x}_m + \boldsymbol{p}_m,\cdots,\boldsymbol{x}_n + \boldsymbol{p}_n,\cdots)\end{equation}
一般来说,只要每个位置的编码向量不同,那么这种全对称性就被打破了,即可以用$\tilde{f}$代替$f$来处理有序的输入。但现在我们希望能进一步分析位置编码的性质,甚至得到一个显式解,那么就不能止步于此。
为了简化问题,我们先只考虑$m,n$这两个位置上的位置编码,将它视为扰动项,泰勒展开到二阶:
\begin{equation}\tilde{f}\approx f + \boldsymbol{p}_m^{\top} \frac{\partial f}{\partial \boldsymbol{x}_m} + \boldsymbol{p}_n^{\top} \frac{\partial f}{\partial \boldsymbol{x}_n} + \frac{1}{2}\boldsymbol{p}_m^{\top} \frac{\partial^2 f}{\partial \boldsymbol{x}_m^2}\boldsymbol{p}_m + \frac{1}{2}\boldsymbol{p}_n^{\top} \frac{\partial^2 f}{\partial \boldsymbol{x}_n^2}\boldsymbol{p}_n + \underbrace{\boldsymbol{p}_m^{\top} \frac{\partial^2 f}{\partial \boldsymbol{x}_m \partial \boldsymbol{x}_n}\boldsymbol{p}_n}_{\boldsymbol{p}_m^{\top} \boldsymbol{\mathcal{H}} \boldsymbol{p}_n}\end{equation}
可以看到,第1项跟位置无关,第2到5项都只依赖于单一位置,所以它们是纯粹的绝对位置信息,第6项是第一个同时包含$\boldsymbol{p}_m,\boldsymbol{p}_n$的交互项,我们将它记为$\boldsymbol{p}_m^{\top} \boldsymbol{\mathcal{H}} \boldsymbol{p}_n$,希望它能表达一定的相对位置信息。
(此处的泰勒展开参考了知乎问题《BERT为何使用学习的position embedding而非正弦position encoding?》上的纳米酱的回复。)
相对位置 #
我们先从简单的例子入手,假设$\boldsymbol{\mathcal{H}}=\boldsymbol{I}$是单位矩阵,此时$\boldsymbol{p}_m^{\top} \boldsymbol{\mathcal{H}} \boldsymbol{p}_n = \boldsymbol{p}_m^{\top} \boldsymbol{p}_n = \langle\boldsymbol{p}_m, \boldsymbol{p}_n\rangle$是两个位置编码的内积,我们希望在这个简单的例子中该项表达的是相对位置信息,即存在某个函数$g$使得
\begin{equation}\langle\boldsymbol{p}_m, \boldsymbol{p}_n\rangle = g(m-n)\label{eq:r1}\end{equation}
这里的$\boldsymbol{p}_m, \boldsymbol{p}_n$是$d$维向量,这里我们从最简单$d=2$入手。
对于2维向量,我们借助复数来推导,即将向量$[x,y]$视为复数$x + y\text{i}$,根据复数乘法的运算法则,我们不难得到:
\begin{equation}\langle\boldsymbol{p}_m, \boldsymbol{p}_n\rangle = \text{Re}[\boldsymbol{p}_m \boldsymbol{p}_n^*]\end{equation}
其中$\boldsymbol{p}_n^*$是$\boldsymbol{p}_n$的共轭复数,$\text{Re}[]$代表复数的实部。为了满足式$\eqref{eq:r1}$,我们可以假设存在复数$\boldsymbol{q}_{m-n}$使得
\begin{equation}\boldsymbol{p}_m \boldsymbol{p}_n^* = \boldsymbol{q}_{m-n}\end{equation}
这样两边取实部就得到了式$\eqref{eq:r1}$。为了求解这个方程,我们可以使用复数的指数形式,即设$\boldsymbol{p}_m=r_m e^{\text{i}\phi_m}, \boldsymbol{p}_n^*=r_n e^{-\text{i}\phi_n}, \boldsymbol{q}_{m-n}=R_{m-n} e^{\text{i}\Phi_{m-n}}$得到
\begin{equation}r_m r_n e^{\text{i}(\phi_m - \phi_n)} = R_{m-n} e^{\text{i}\Phi_{m-n}}\quad\Rightarrow\quad \left\{\begin{aligned}&r_m r_n = R_{m-n}\\ & \phi_m - \phi_n=\Phi_{m-n}\end{aligned}\right.\end{equation}
对于第一个方程,代入$n=m$得$r_m^2=R_0$,即$r_m$是一个常数,简单起见这里设为1就好;对于第二个方程,代入$n=0$得$\phi_m - \phi_0=\Phi_m$,简单起见设$\phi_0=0$,那么$\phi_m=\Phi_m$,即$\phi_m - \phi_n=\phi_{m-n}$,代入$n=m-1$得$\phi_m - \phi_{m-1}=\phi_1$,那么$\{\phi_m\}$只是一个等差数列,通解为$m\theta$,因此我们就得到二维情形下位置编码的解为:
\begin{equation}\boldsymbol{p}_m = e^{\text{i}m\theta}\quad\Leftrightarrow\quad \boldsymbol{p}_m=\begin{pmatrix}\cos m\theta \\ \sin m\theta\end{pmatrix}\end{equation}
由于内积满足线性叠加性,所以更高维的偶数维位置编码,我们可以表示为多个二维位置编码的组合:
\begin{equation}\boldsymbol{p}_m = \begin{pmatrix}e^{\text{i}m\theta_0} \\ e^{\text{i}m\theta_1} \\ \vdots \\ e^{\text{i}m\theta_{d/2-1}}\end{pmatrix}\quad\Leftrightarrow\quad \boldsymbol{p}_m=\begin{pmatrix}\cos m\theta_0 \\ \sin m\theta_0 \\ \cos m\theta_1 \\ \sin m\theta_1 \\ \vdots \\ \cos m\theta_{d/2-1} \\ \sin m\theta_{d/2-1} \end{pmatrix}\label{eq:r2}\end{equation}
它同样满足式$\eqref{eq:r1}$。当然,这只能说是式$\eqref{eq:r1}$的一个解,但不是唯一解,对于我们来说,求出一个简单的解就行了。
远程衰减 #
基于前面的假设,我们推导出了位置编码的形式$\eqref{eq:r2}$,它跟标准的Sinusoidal位置编码$\eqref{eq:sin}$形式基本一样了,只是$\sin,\cos$的位置有点不同。一般情况下,神经网络的神经元都是无序的,所以哪怕打乱各个维度,也是一种合理的位置编码,因此除了各个$\theta_i$没确定下来外,式$\eqref{eq:r2}$和式$\eqref{eq:sin}$并无本质区别。
式$\eqref{eq:sin}$的选择是$\theta_i = 10000^{-2i/d}$,这个选择有什么意义呢?事实上,这个形式有一个良好的性质:它使得随着$|m-n|$的增大,$\langle\boldsymbol{p}_m, \boldsymbol{p}_n\rangle$有着趋于零的趋势。按照我们的直观想象,相对距离越大的输入,其相关性应该越弱,因此这个性质是符合我们的直觉的。只是,明明是周期性的三角函数,怎么会呈现出衰减趋势呢?
这的确是个神奇的现象,源于高频振荡积分的渐近趋零性。具体来说,我们将内积写为
\begin{equation}\begin{aligned}
\langle\boldsymbol{p}_m, \boldsymbol{p}_n\rangle =&\, \text{Re}\left[e^{\text{i}(m-n)\theta_0} + e^{\text{i}(m-n)\theta_1} + \cdots + e^{\text{i}(m-n)\theta_{d/2-1}}\right]\\
=&\,\frac{d}{2}\cdot\text{Re}\left[\sum_{i=0}^{d/2-1} e^{\text{i}(m-n)10000^{-i/(d/2)}}\frac{1}{d/2}\right]\\
\sim&\, \frac{d}{2}\cdot\text{Re}\left[\int_0^1 e^{\text{i}(m-n)\cdot 10000^{-t}}dt\right]
\end{aligned}\end{equation}
这样问题就变成了积分$\int_0^1 e^{\text{i}(m-n)\theta_t}dt$的渐近估计问题了。其实这种振荡积分的估计在量子力学中很常见,可以利用其中的方法进行分析,但对于我们来说,最直接的方法就是通过Mathematica把积分结果的图像画出来:
\[Theta][t_] = (1/10000)^t;
f[x_] = Re[Integrate[Exp[I*x*\[Theta][t]], {t, 0, 1}]];
Plot[f[x], {x, -128, 128}]然后从图像中我们就可以看出确实具有衰减趋势:
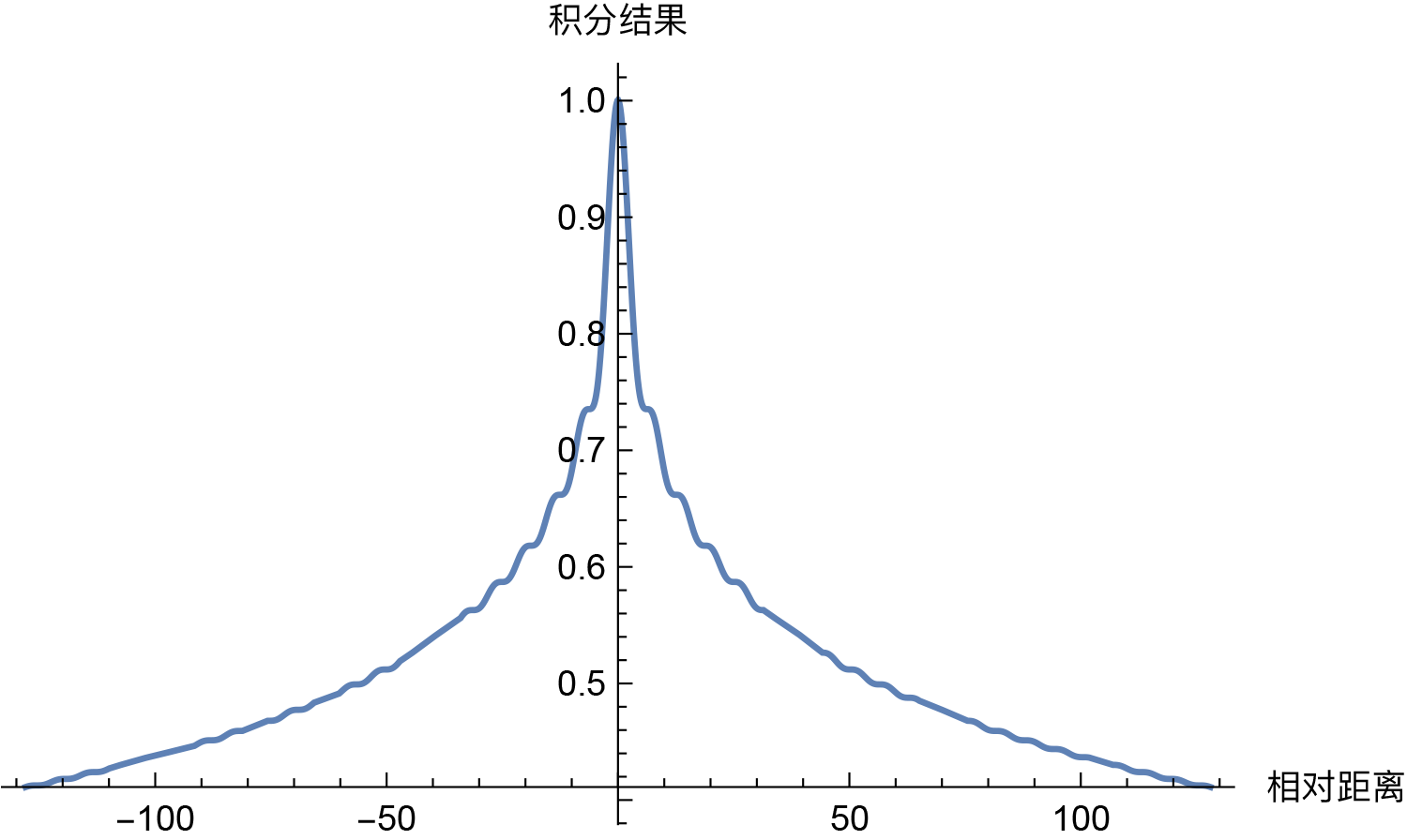
通过直接积分估计Sinusoidal位置编码的内积衰减趋势
那么,问题来了,必须是$\theta_t = 10000^{-t}$才能呈现出远程衰减趋势吗?当然不是。事实上,对于我们这里的场景,“几乎”每个$[0,1]$上的单调光滑函数$\theta_t$,都能使得积分$\int_0^1 e^{\text{i}(m-n)\theta_t}dt$具有渐近衰减趋势,比如幂函数$\theta_t = t^{\alpha}$。那么,$\theta_t = 10000^{-t}$有什么特别的吗?我们来比较一些结果。
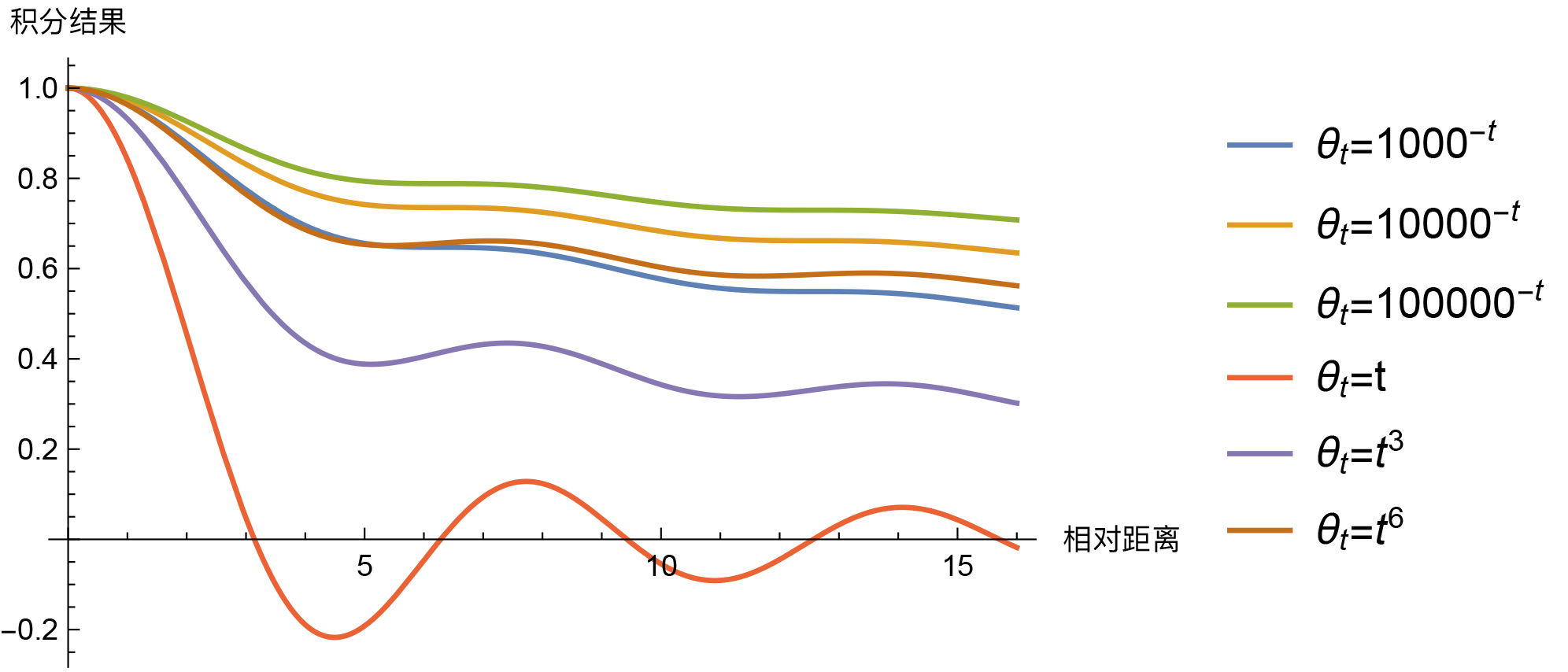
几个不同的θt的积分结果(短距离趋势)

几个不同的θt的积分结果(长距离趋势)
就这样看上去,除了$\theta_t=t$比较异常之外(与横轴有交点),其他都没有什么明显的区分度,很难断定孰优孰劣,无非就是幂函数在短距离降得快一点,而指数函数则在长距离降得快一点,$\theta_t$整体越接近于0,那么整体就降得慢一些,等等。如此看来$\theta_t = 10000^{-t}$也只是一个折中的选择,没有什么特殊性,要是笔者来选,多半会选$\theta_t = 1000^{-t}$。还有一个方案是,直接让$\theta_i = 10000^{-2i/d}$作为各个$\theta_i$的初始化值,然后将它设为可训练的,由模型自动完成微调,这样也不用纠结选哪个了。
一般情况 #
前面两节中,我们展示了通过绝对位置编码来表达相对位置信息的思想,加上远程衰减的约束,可以“反推”出Sinusoidal位置编码,并且给出了关于$\theta_i$的其他选择。但是别忘了,到目前为止,我们的推导都是基于$\boldsymbol{\mathcal{H}}=\boldsymbol{I}$这个简单情况的,对于一般的$\boldsymbol{\mathcal{H}}$,使用上述Sinusoidal位置编码,还能具备以上的良好性质吗?
如果$\boldsymbol{\mathcal{H}}$是一个对角阵,那么上面的各个性质可以得到一定的保留,此时
\begin{equation}\boldsymbol{p}_m^{\top} \boldsymbol{\mathcal{H}} \boldsymbol{p}_n=\sum_{i=1}^{d/2} \boldsymbol{\mathcal{H}}_{2i,2i} \cos m\theta_i \cos n\theta_i + \boldsymbol{\mathcal{H}}_{2i+1,2i+1} \sin m\theta_i \sin n\theta_i\end{equation}
由积化和差公式得到
\begin{equation}\sum_{i=1}^{d/2} \frac{1}{2}\left(\boldsymbol{\mathcal{H}}_{2i,2i} + \boldsymbol{\mathcal{H}}_{2i+1,2i+1}\right) \cos (m-n)\theta_i + \frac{1}{2}\left(\boldsymbol{\mathcal{H}}_{2i,2i} - \boldsymbol{\mathcal{H}}_{2i+1,2i+1}\right) \cos (m+n)\theta_i \end{equation}
可以看到它也是确实包含了相对位置$m-n$,只不过可能会多出$m+n$这一项,如果不需要它,模型可以让$\boldsymbol{\mathcal{H}}_{2i,2i} = \boldsymbol{\mathcal{H}}_{2i+1,2i+1}$来消除它。在这个特例下,我们指出的是Sinusoidal位置编码赋予了模型学习相对位置的可能,至于具体需要什么位置信息,则由模型的训练自行决定。
特别地,对于上式,远程衰减特性依然存在,比如第一项求和,类比前一节的近似,它相当于积分
\begin{equation}\sum_{i=1}^{d/2} \frac{1}{2}\left(\boldsymbol{\mathcal{H}}_{2i,2i} + \boldsymbol{\mathcal{H}}_{2i+1,2i+1}\right) \cos (m-n)\theta_i \sim \int_0^1 h_t e^{\text{i}(m-n)\theta_t}dt\end{equation}
同样地,振荡积分的一些估计结果(参考《Oscillatory integrals》、《学习笔记3-一维振荡积分与应用》等)告诉我们,该振荡积分在比较容易达到的条件下,有$|m-n|\to\infty$时积分值趋于零,因此远程衰减特性是可以得到保留的。
如果$\boldsymbol{\mathcal{H}}$不是对角阵,那么很遗憾,上述性质都很难重现的。我们只能寄望于$\boldsymbol{\mathcal{H}}$的对角线部分占了主项,这样一来上述的性质还能近似保留。对角线部分占主项,意味着$d$维向量之间任意两个维度的相关性比较小,满足一定的解耦性。对于Embedding层来说,这个假设还是有一定的合理性的,笔者检验了BERT训练出来的词Embedding矩阵和位置Embedding矩阵的协方差矩阵,发现对角线元素明显比非对角线元素大,证明了对角线元素占主项这个假设具有一定的合理性。
问题讨论 #
有读者会反驳:就算你把Sinusoidal位置编码说得无与伦比,也改变不了直接训练的位置编码比Sinusoidal位置编码效果要好的事实。的确,有实验表明,在像BERT这样的经过充分预训练的Transformer模型中,直接训练的位置编码效果是要比Sinusoidal位置编码好些,这个并不否认。本文要做的事情,只是从一些原理和假设出发,推导Sinusoidal位置编码为什么可以作为一个有效的位置,但并不是说它一定就是最好的位置编码。
推导是基于一些假设的,如果推导出来的结果不够好,那么就意味着假设与实际情况不够符合。那么,对于Sinusoidal位置编码来说,问题可能出现在哪呢?我们可以逐步来反思一下。
第一步,泰勒展开,这个依赖于$\boldsymbol{p}$是小量,笔者也在BERT中做了检验,发现词Embedding的平均模长要比位置Embedding的平均模长大,这说明$\boldsymbol{p}$是小量某种程度上是合理的,但是多合理也说不准,因为Embedding模长虽然更大但也没压倒性;第二步,假设$\boldsymbol{\mathcal{H}}$是单位阵,因为上一节我们分析了它很可能是对角线占主项的,所以先假设单位阵可能也不是太大的问题;第三步,假设通过两个绝对位置向量的内积来表达相对位置,这个直觉上告诉我们应该是合理的,绝对位置的相互应当有能力表达一定程度的相对位置信息;最后一步,通过自动远程衰减的特性来确定$\theta_i$,这个本身应该也是好的,但就是这一步变数太大,因为可选的$\theta_i$形式太多,甚至还有可训练的$\theta_i$,很难挑出最合理的,因此如果说Sinusoidal位置编码不够好,这一步也非常值得反思。
文章小结 #
总的来说,本文试图基于一些假设,反推出Sinusoidal位置编码来,这些假设具有其一定的合理性,也有一定的问题,所以相应的Sinusoidal位置编码可圈可点,但并非毫无瑕疵。但不管怎样,在当前的深度学习中,能够针对具体的问题得到一个显式解,而不是直接暴力拟合,Sinusoidal位置编码是一个不可多得的案例,值得我们思考回味。
转载到请包括本文地址:https://spaces.ac.cn/archives/8231
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Mar. 08, 2021). 《Transformer升级之路:1、Sinusoidal位置编码追根溯源 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8231
@online{kexuefm-8231,
title={Transformer升级之路:1、Sinusoidal位置编码追根溯源},
author={苏剑林},
year={2021},
month={Mar},
url={\url{https://spaces.ac.cn/archives/8231}},
}

March 8th, 2021
对于第一个方程,代入n=m得r2m=R0,这个地方感觉有问题, Rm-n这样的只是一个符号,下标应该不能计算的吧。比如m=n=2 和m=n=3对应的R值应该是不一样的吧。
很显然,$R_{m-n}$是$m-n$的函数,要不然为什么记作$R_{m-n}$而不是$R_{m,n}$?
March 9th, 2021
"""
对于第二个方程,代入$n=0$得$\phi_m−\phi_0=\Phi_m$,简单起见设$\phi_0=0$,那么$\phi _m=\Phi_m$,即$\phi_m−\phi_n=\phi_{m−n}$
"""
最后一句不太理解,意思是对于$\phi_0=0$,$\phi_m−\phi_n=\phi_{m−n}$成立,还是可以推广到任意$m,n$,好像推广不了任意$m,n$啊
看明白了,谢谢
March 15th, 2021
页面开着刷新一下,题目变了哈哈
计划有变,打算集合更多样的内容~
March 23rd, 2021
文中似乎只讨论了Sinusoidal对(4)式中最后一项(交互项)具有良好的性质,这里有些问题请教:
1 Sinusoidal对(4)式中2-5项(绝对位置)会产生怎样的影响?
2 (4)式中最后一项(交互项)相对2-5项的比值有多大,如果比值太小是否可以忽略掉(如果不忽略至少也不必太过重视)
“相对不变性”、“远程衰减”是“好”的位置编码应有的几个性质,但我担心由于(4)式2-5项比重较大,导致这几个好性质得不到体现。
这还真是个好问题,我好像也忽略了这一点。整体而言,由于$\boldsymbol{p}_m,\boldsymbol{p}_n$的模长都是固定的,所以绝对位置项是不可能呈现出衰减趋势的,因此相对位置项的话,基本是能衰减多少就衰减多少吧,有种“无害可能还有利”的感觉在里边。不过这个可能也确实是Sinusoidal位置编码不够好的原因。
下一篇文章将会详细介绍我们自研的位置编码,能够具有Sinusoidal的特性,并且很大程度上修复Sinusoidal的缺点,敬请期待~
April 25th, 2021
苏神,能否给个公式14的具体推导,因为我根据求和与积分的关系可以推导出公式11,但是不知道如何推出公式14
我觉得好像利用公式
$$
\lim \limits_{n\to \infty} \frac{1}{n}\sum_{i=1}^{n}f(\frac{i}{n})=\int_0^1 f(x)dx
$$
推不出式(14)
其实$(14)$没有什么“推导”之说,$\sim$的意思是“类比”、“相当于”,就是说我们要分析$\sum_i a_i b_i$的性态,大致上相当于分析$\int a(x)b(x)dx$的性态,但两者没有必然的互推关系,只是一种类比。
更严格的分析,可以参考 https://kexue.fm/archives/8265 中的远程衰减的分析。
感谢苏神回复,明白了
April 28th, 2021
Sinusoidal位置编码可以表达相对位置关系,那么可以说明可以表达词与词之间的顺序关系么,进一步可以表达词与词之间的方向么?
“词与词之间的顺序关系”、“词与词之间的方向”具体是什么概念?
June 1st, 2021
再补充下,注意到Eq. (9)得出的结果代入Eq. (5),可以发现$\langle p_m,p_n\rangle = \langle p_n,p_m\rangle$,即这种编码方式不能捕捉相对距离的方向,即[TENER: Adapting Transformer Encoder for Named Entity Recognition
](https://arxiv.org/abs/1911.04474)中Figure 3中所述的问题。
其实也不至于,因为实际情况并不是直接内积的~
确实。。。
June 3rd, 2021
牛啊,是怎么想到复数并且是指数这块的?
June 8th, 2021
你好,苏神, 里面有句话不是很能理解 ”像Transformer这样的纯Attention模型,它是全对称的“ , 我理解的是因为attention 无论字在哪, 和其他字的相关性是不变的,所以加权后是不变的, 但是attention前面不是有线性变换吗,矩阵的位置不会根据字顺序调整, 他输出到attention前面的结果是不是就变了呢 ?
全连接也没在token之间运算,仅仅是每个token内部(向量维度之间)进行交互运算。
如果句子编码成 seq_len * emb_len 的向量, 但是不在emb_len的维度进行线性变换, 而是在seq_len 维度进行一个 seq_len * seq_len 的线性变换, 算是token间的运算吗 ? 能引入位置信息了吗 ?
那肯定可以啊,这就是最近很火的mlp-mixer系列工作。
参考:https://kexue.fm/archives/8431
好的,谢谢苏神。
August 31st, 2021
深度学习中能解出显式解的问题,太难得了,大多数场景还得靠训练拟合。