






18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 344494位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
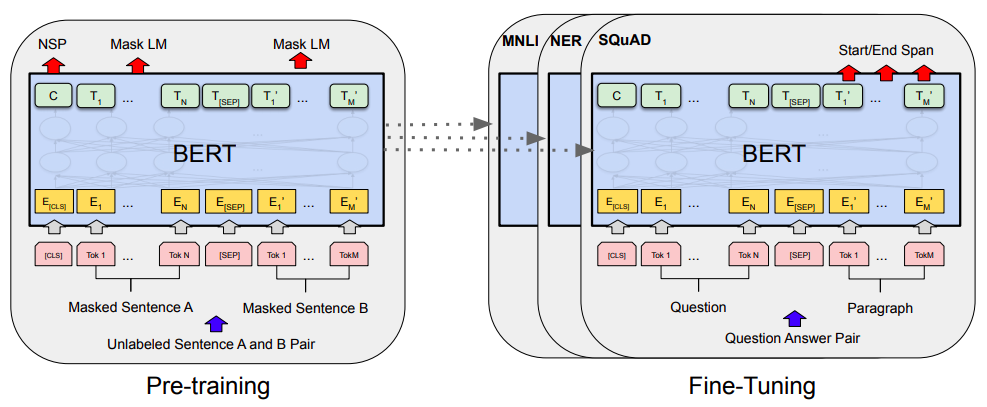
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
7
Apr
【不可思议的Word2Vec】 3.提取关键词
By 苏剑林 | 2017-04-07 | 172997位读者 | 引用本文主要是给出了关键词的一种新的定义,并且基于Word2Vec给出了一个实现方案。这种关键词的定义是自然的、合理的,Word2Vec只是一个简化版的实现方案,可以基于同样的定义,换用其他的模型来实现。
说到提取关键词,一般会想到TF-IDF和TextRank,大家是否想过,Word2Vec还可以用来提取关键词?而且,用Word2Vec提取关键词,已经初步含有了语义上的理解,而不仅仅是简单的统计了,而且还是无监督的!
什么是关键词?
诚然,TF-IDF和TextRank是两种提取关键词的很经典的算法,它们都有一定的合理性,但问题是,如果从来没看过这两个算法的读者,会感觉简直是异想天开的结果,估计很难能够从零把它们构造出来。也就是说,这两种算法虽然看上去简单,但并不容易想到。试想一下,没有学过信息相关理论的同学,估计怎么也难以理解为什么IDF要取一个对数?为什么不是其他函数?又有多少读者会破天荒地想到,用PageRank的思路,去判断一个词的重要性?
说到底,问题就在于:提取关键词和文本摘要,看上去都是一个很自然的任务,有谁真正思考过,关键词的定义是什么?这里不是要你去查汉语词典,获得一大堆文字的定义,而是问你数学上的定义。关键词在数学上的合理定义应该是什么?或者说,我们获取关键词的目的是什么?
3
Apr
【不可思议的Word2Vec】 2.训练好的模型
By 苏剑林 | 2017-04-03 | 365270位读者 | 引用由于后面几篇要讲解Word2Vec怎么用,因此笔者先训练好了一个Word2Vec模型。为了节约读者的时间,并且保证读者可以复现后面的结果,笔者决定把这个训练好的模型分享出来,用Gensim训练的。单纯的词向量并不大,但第一篇已经说了,我们要用到完整的Word2Vec模型,因此我将完整的模型分享出来了,包含四个文件,所以文件相对大一些。
提醒读者的是,如果你想获取完整的Word2Vec模型,又不想改源代码,那么Python的Gensim库应该是你唯一的选择,据我所知,其他版本的Word2Vec最后都是只提供词向量给我们,没有完整的模型。
对于做知识挖掘来说,显然用知识库语料(如百科语料)训练的Word2Vec效果会更好。但百科语料我还在爬取中,爬完了我再训练一个模型,到时再分享。
模型概况
这个模型的大概情况如下:
$$\begin{array}{c|c}
\hline
\text{训练语料} & \text{微信公众号的文章,多领域,属于中文平衡语料}\\
\hline
\text{语料数量} & \text{800万篇,总词数达到650亿}\\
\hline
\text{模型词数} & \text{共352196词,基本是中文词,包含常见英文词}\\
\hline
\text{模型结构} & \text{Skip-Gram + Huffman Softmax}\\
\hline
\text{向量维度} & \text{256维}\\
\hline
\text{分词工具} & \text{结巴分词,加入了有50万词条的词典,关闭了新词发现}\\
\hline
\text{训练工具} & \text{Gensim的Word2Vec,服务器训练了7天}\\
\hline
\text{其他情况} & \text{窗口大小为10,最小词频是64,迭代了10次}\\
\hline
\end{array}$$
2
Apr
【不可思议的Word2Vec】 1.数学原理
By 苏剑林 | 2017-04-02 | 50099位读者 | 引用对于了解深度学习、自然语言处理NLP的读者来说,Word2Vec可以说是家喻户晓的工具,尽管不是每一个人都用到了它,但应该大家都会听说过它——Google出品的高效率的获取词向量的工具。
Word2Vec不可思议?
大多数人都是将Word2Vec作为词向量的等价名词,也就是说,纯粹作为一个用来获取词向量的工具,关心模型本身的读者并不多。可能是因为模型过于简化了,所以大家觉得这样简化的模型肯定很不准确,所以没法用,但它的副产品词向量的质量反而还不错。没错,如果是作为语言模型来说,Word2Vec实在是太粗糙了。
但是,为什么要将它作为语言模型来看呢?抛开语言模型的思维约束,只看模型本身,我们就会发现,Word2Vec的两个模型 —— CBOW和Skip-Gram —— 实际上大有用途,它们从不同角度来描述了周围词与当前词的关系,而很多基本的NLP任务,都是建立在这个关系之上,如关键词抽取、逻辑推理等。这几篇文章就是希望能够抛砖引玉,通过介绍Word2Vec模型本身,以及几个看上去“不可思议”的用法,来提供一些研究此类问题的新思路。

最近评论