






5
Mar
短文本匹配Baseline:脱敏数据使用预训练模型的尝试
By 苏剑林 | 2021-03-05 | 144949位读者 | 引用最近凑着热闹玩了玩全球人工智能技术创新大赛中的“小布助手对话短文本语义匹配”赛道,其任务就是常规的短文本句子对二分类任务,这任务在如今各种预训练Transformer“横行”的时代已经没啥什么特别的难度了,但有意思的是,这次比赛脱敏了,也就是每个字都被影射为数字ID了,我们无法得到原始文本。
在这种情况下,还能用BERT等预训练模型吗?用肯定是可以用的,但需要一些技巧,并且可能还需要再预训练一下。本文分享一个baseline,它将分类、预训练和半监督学习都结合在了一起,能够用于脱敏数据任务。
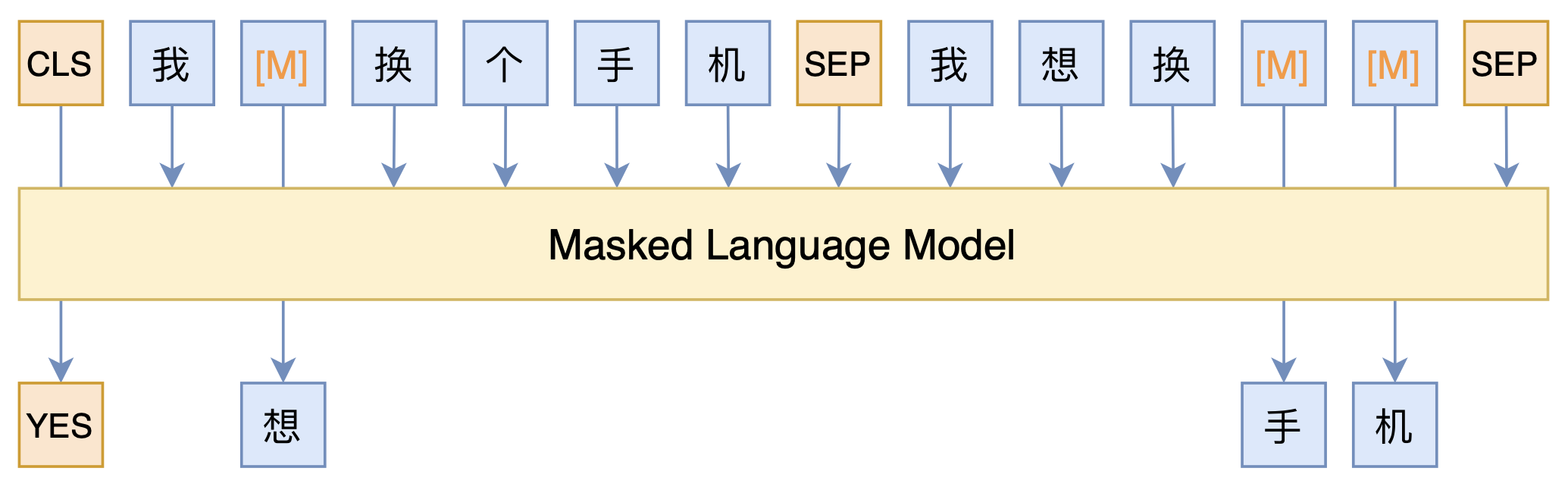
本文模型示意图
3
Mar
T5 PEGASUS:开源一个中文生成式预训练模型
By 苏剑林 | 2021-03-03 | 275884位读者 | 引用去年在文章《那个屠榜的T5模型,现在可以在中文上玩玩了》中我们介绍了Google的多国语言版T5模型(mT5),并给出了用mT5进行中文文本生成任务的例子。诚然,mT5做中文生成任务也是一个可用的方案,但缺乏完全由中文语料训练出来模型总感觉有点别扭,于是决心要搞一个出来。
经过反复斟酌测试,我们决定以mT5为基础架构和初始权重,先结合中文的特点完善Tokenizer,然后模仿PEGASUS来构建预训练任务,从而训练一版新的T5模型,这就是本文所开源的T5 PEGASUS。

T5 PEGASUS的训练数据示例
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 72152位读者 | 引用标准Attention的$\mathcal{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
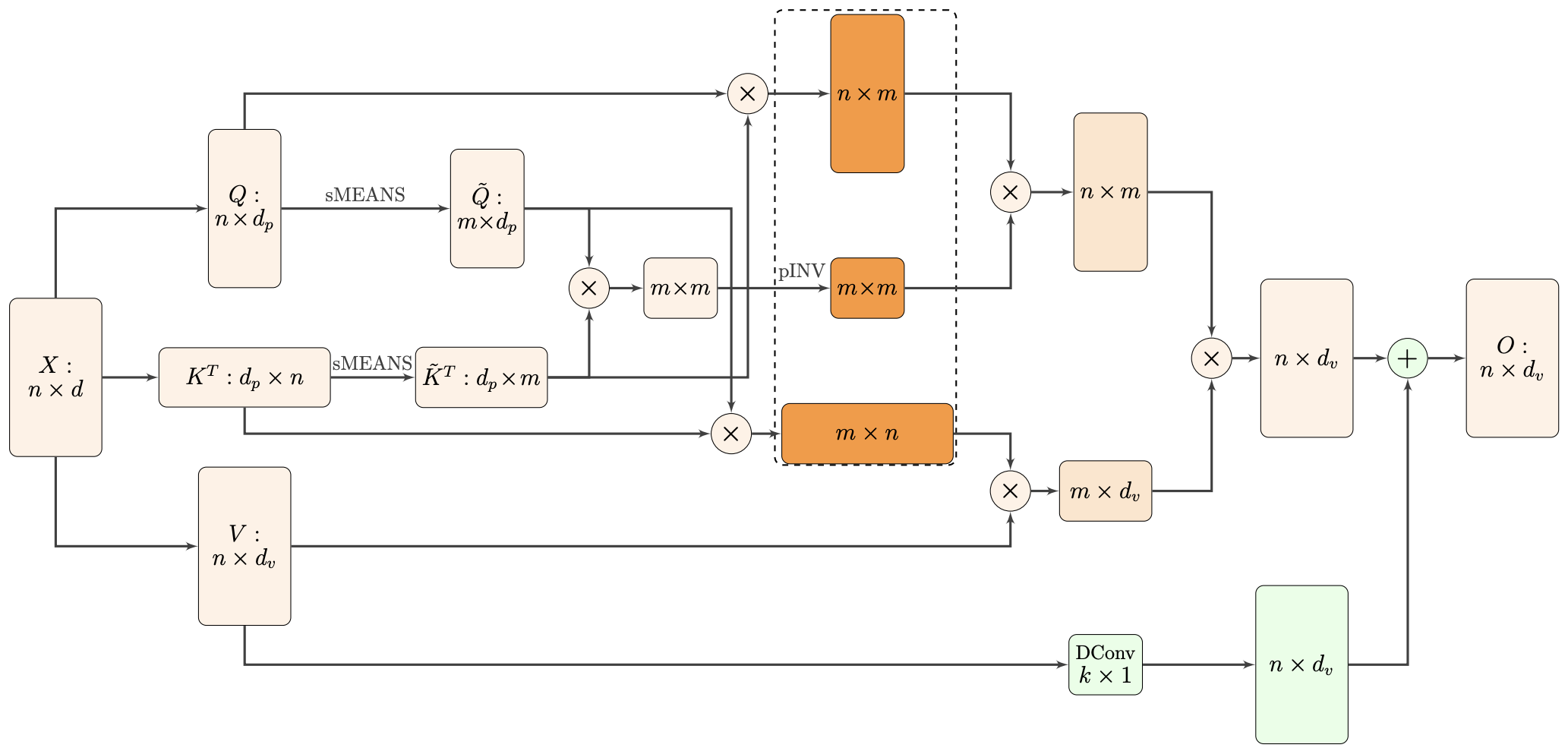
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。
26
Jan
Seq2Seq重复解码现象的理论分析尝试
By 苏剑林 | 2021-01-26 | 44682位读者 | 引用去年笔者写过博文《如何应对Seq2Seq中的“根本停不下来”问题?》,里边介绍了一篇论文中对Seq2Seq解码不停止现象的处理,并指出那篇论文只是提了一些应对该问题的策略,并没有提供原理上的理解。近日,笔者在Arixv读到了AAAI 2021的一篇名为《A Theoretical Analysis of the Repetition Problem in Text Generation》的论文,里边从理论上分析了Seq2Seq重复解码现象。从本质上来看,重复解码和解码不停止其实都是同理的,所以这篇新论文算是填补了前面那篇论文的空白。
经过学习,笔者发现该论文确实有不少可圈可点之处,值得一读。笔者对原论文中的分析过程做了一些精简、修正和推广,将结果记录成此文,供大家参考。此外,抛开问题背景不讲,读者也可以将本文当成一节矩阵分析习题课,供大家复习线性代数哈~
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 319682位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 93928位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
11
Nov
当GPT遇上中国象棋:写过文章解过题,要不再来下盘棋?
By 苏剑林 | 2020-11-11 | 76750位读者 | 引用
中国象棋
不知道读者有没有看过量子位年初的文章《最强写作AI竟然学会象棋和作曲,语言模型跨界操作引热议,在线求战》,里边提到有网友用GPT2模型训练了一个下国际象棋的模型。笔者一直在想,这么有趣的事情怎么可以没有中文版呢?对于国际象棋来说,其中文版自然就是中国象棋了,于是我一直有想着把它的结果在中国象棋上面复现一下。拖了大半年,在最近几天终于把这个事情完成了,在此跟大家分享一下。
象棋谱式
将军不离九宫内,士止相随不出官。
象飞四方营四角,马行一步一尖冲。
炮须隔子打一子,车行直路任西东。
唯卒只能行一步,过河横进退无踪。
6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 185628位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。

“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。

最近评论