






27
Jul
生成扩散模型漫谈(四):DDIM = 高观点DDPM
By 苏剑林 | 2022-07-27 | 395980位读者 | 引用相信很多读者都听说过甚至读过克莱因的《高观点下的初等数学》这套书,顾名思义,这是在学到了更深入、更完备的数学知识后,从更高的视角重新审视过往学过的初等数学,以得到更全面的认知,甚至达到温故而知新的效果。类似的书籍还有很多,比如《重温微积分》、《复分析:可视化方法》等。
回到扩散模型,目前我们已经通过三篇文章从不同视角去解读了DDPM,那么它是否也存在一个更高的理解视角,让我们能从中得到新的收获呢?当然有,《Denoising Diffusion Implicit Models》介绍的DDIM模型就是经典的案例,本文一起来欣赏它。
思路分析
在《生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪》中,我们提到过该文章所介绍的推导跟DDIM紧密相关。具体来说,文章的推导路线可以简单归纳如下:
\begin{equation}p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\xrightarrow{\text{推导}}p(\boldsymbol{x}_t|\boldsymbol{x}_0)\xrightarrow{\text{推导}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)\xrightarrow{\text{近似}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)\end{equation}
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 272475位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
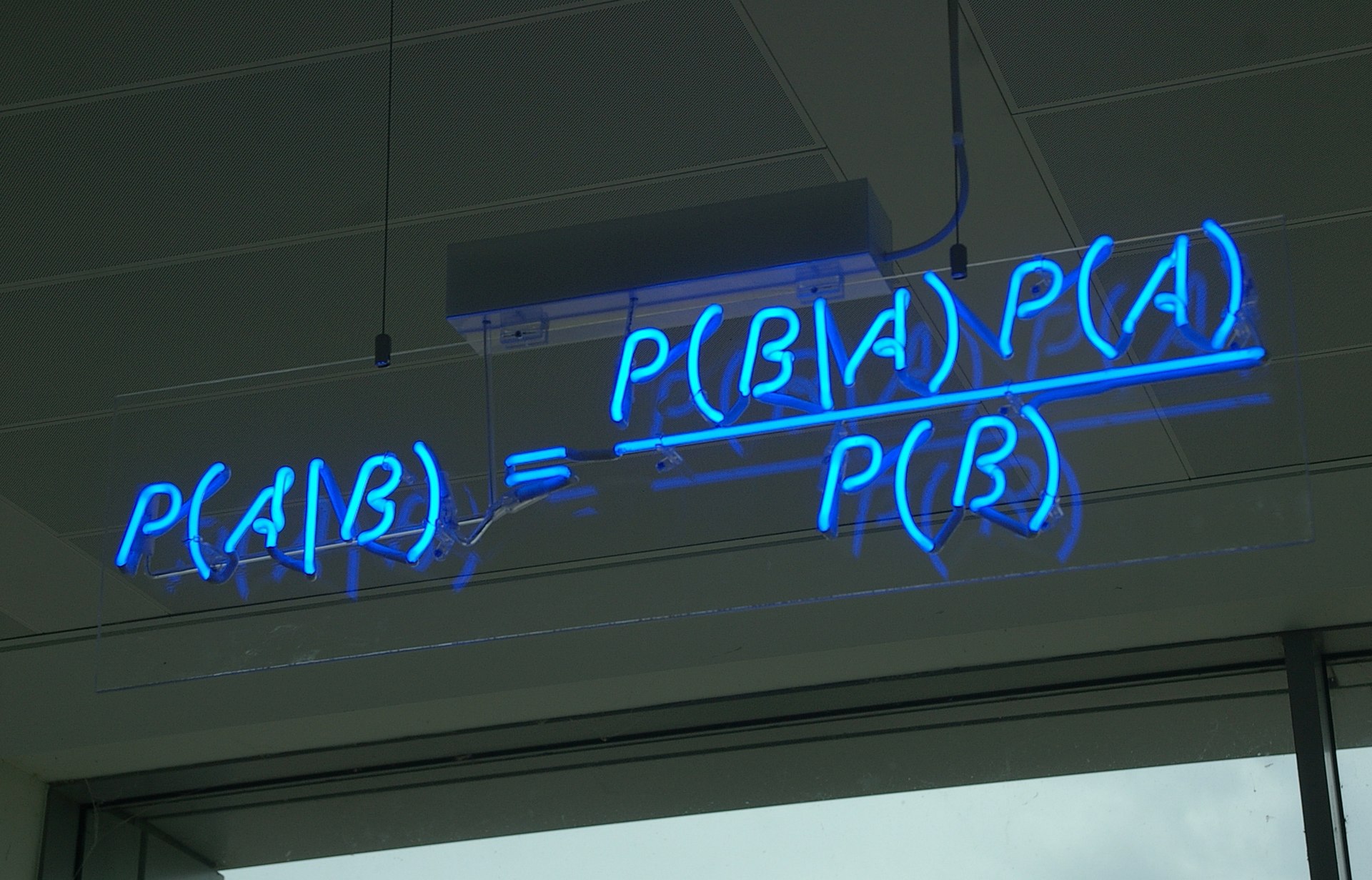
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
6
Jul
生成扩散模型漫谈(二):DDPM = 自回归式VAE
By 苏剑林 | 2022-07-06 | 229762位读者 | 引用在文章《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中,我们为生成扩散模型DDPM构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型DDPM的理论形式。在该文章中,我们还指出DDPM本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器VAE,实际上DDPM的原论文中也是将它按照VAE的思路进行推导的。
所以,本文就从VAE的角度来重新介绍一版DDPM,同时分享一下自己的Keras实现代码和实践经验。
Github地址:https://github.com/bojone/Keras-DDPM
多步突破
在传统的VAE中,编码过程和生成过程都是一步到位的:
\begin{equation}\text{编码:}\,\,x\to z\,,\quad \text{生成:}\,\,z\to x\end{equation}
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 59188位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 760114位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 284226位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
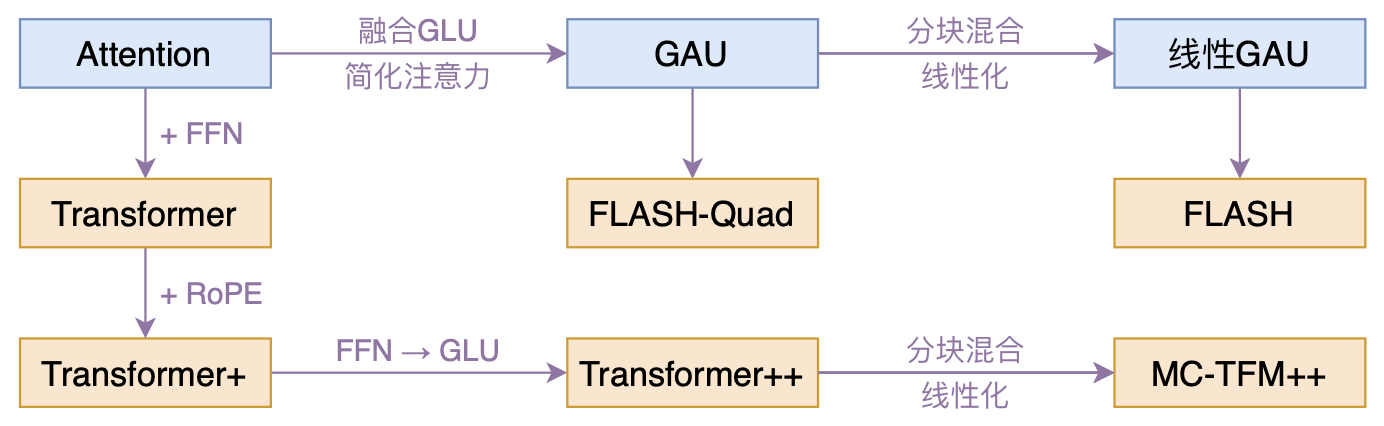
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
9
Dec
变分自编码器(八):估计样本概率密度
By 苏剑林 | 2021-12-09 | 99028位读者 | 引用在本系列的前面几篇文章中,我们已经从多个角度来理解了VAE,一般来说,用VAE是为了得到一个生成模型,或者是做更好的编码模型,这都是VAE的常规用途。但除了这些常规应用外,还有一些“小众需求”,比如用来估计$x$的概率密度,这在做压缩的时候通常会用到。
本文就从估计概率密度的角度来了解和推导一下VAE模型。
两个问题
所谓估计概率密度,就是在已知样本$x_1,x_2,\cdots,x_N\sim \tilde{p}(x)$的情况下,用一个待定的概率密度簇$q_{\theta}(x)$去拟合这批样本,拟合的目标一般是最小化负对数似然:
\begin{equation}\mathbb{E}_{x\sim \tilde{p}(x)}[-\log q_{\theta}(x)] = -\frac{1}{N}\sum_{i=1}^N \log q_{\theta}(x_i)\label{eq:mle}\end{equation}
15
Nov
WGAN新方案:通过梯度归一化来实现L约束
By 苏剑林 | 2021-11-15 | 75267位读者 | 引用当前,WGAN主流的实现方式包括参数裁剪(Weight Clipping)、谱归一化(Spectral Normalization)、梯度惩罚(Gradient Penalty),本来则来介绍一种新的实现方案:梯度归一化(Gradient Normalization),该方案出自两篇有意思的论文,分别是《Gradient Normalization for Generative Adversarial Networks》和《GraN-GAN: Piecewise Gradient Normalization for Generative Adversarial Networks》。
有意思在什么地方呢?从标题可以看到,这两篇论文应该是高度重合的,甚至应该是同一作者的。但事实上,这是两篇不同团队的、大致是同一时期的论文,一篇中了ICCV,一篇中了WACV,它们基于同样的假设推出了几乎一样的解决方案,内容重合度之高让我一直以为是同一篇论文。果然是巧合无处不在啊~

最近评论