






14
Jan
旁门左道之如何让Python的重试代码更加优雅
By 苏剑林 | 2024-01-14 | 64426位读者 | 引用这篇文章我们讨论一个编程题:如何更优雅地在Python中实现重试。
在文章《新年快乐!记录一下 Cool Papers 的开发体验》中,笔者分享了开发Cool Papers的一些经验,其中就提到了Cool Papers所需要的一些网络通信步骤。但凡涉及到网络通信,就有失败的风险(谁也无法保证网络不会间歇性抽风),所以重试是网络通信的基本操作。此外,当涉及到多进程、数据库、硬件交互等操作时,通常也需要引入重试机制。
在Python中,实现重试并不难,但如何更加简单而又不失可读性地实现重试,还是有一定技巧的。接下来笔者分享一下自己的尝试。
循环重试
完整的重试流程大致上包含循环重试、异常处理、延时等待、后续操作等部分,其标准写法就是用for循环,用“try ... except ...”来捕捉异常,一个参考代码是:
17
Dec
Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)
By 苏剑林 | 2021-12-17 | 94783位读者 | 引用两年前,在《万能的seq2seq:基于seq2seq的阅读理解问答》和《“非自回归”也不差:基于MLM的阅读理解问答》中,我们在尝试过分别利用“Seq2Seq+前缀树”和“MLM+前缀树”的方式做抽取式阅读理解任务,并获得了不错的结果。而在去年的ICLR2021上,Facebook的论文《Autoregressive Entity Retrieval》同样利用“Seq2Seq+前缀树”的组合,在实体链接和文档检索上做到了效果与效率的“双赢”。
事实上,“Seq2Seq+前缀树”的组合理论上可以用到任意检索型任务中,堪称是检索任务的“新范式”。本文将再次回顾“Seq2Seq+前缀树”的思路,并用它来实现最近推出的KgCLUE知识图谱问答榜单的一个baseline。
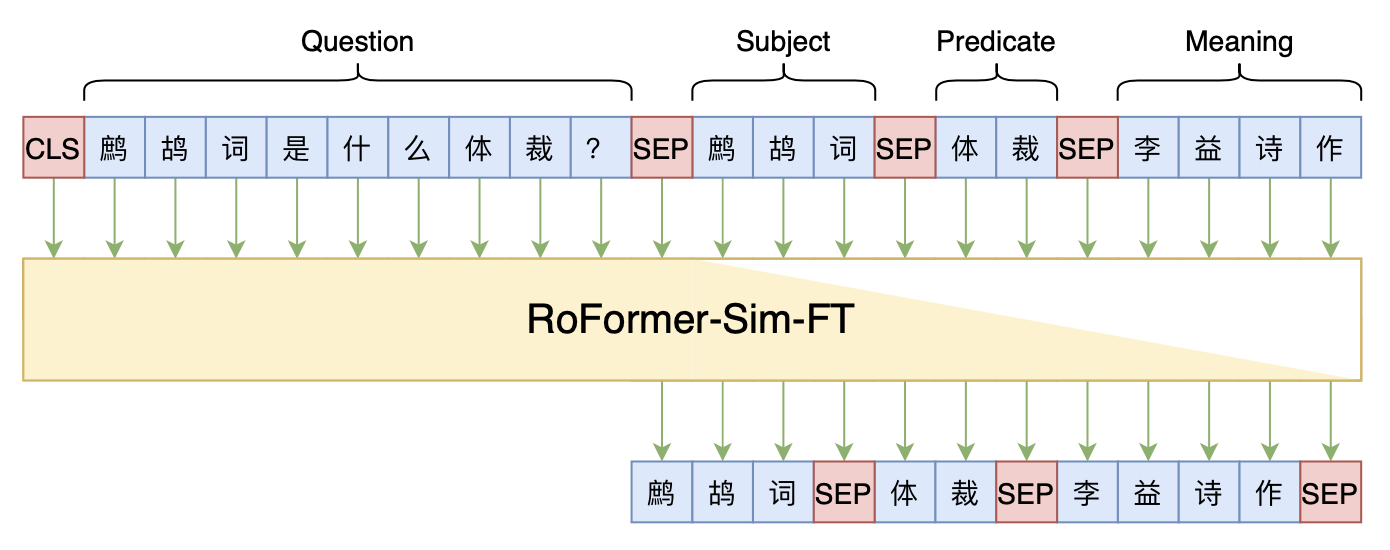
本文baseline模型示意图
31
Oct
bert4keras在手,baseline我有:CLUE基准代码
By 苏剑林 | 2021-10-31 | 110163位读者 | 引用CLUE(Chinese GLUE)是中文自然语言处理的一个评价基准,目前也已经得到了较多团队的认可。CLUE官方Github提供了tensorflow和pytorch的baseline,但并不易读,而且也不方便调试。事实上,不管是tensorflow还是pytorch,不管是CLUE还是GLUE,笔者认为能找到的baseline代码,都很难称得上人性化,试图去理解它们是一件相当痛苦的事情。
所以,笔者决定基于bert4keras实现一套CLUE的baseline。经过一段时间的测试,基本上复现了官方宣称的基准成绩,并且有些任务还更优。最重要的是,所有代码尽量保持了清晰易读的特点,真·“Deep Learning for Humans”。
代码简介
下面简单介绍一下该代码中各个任务baseline的构建思路。在阅读文章和代码之前,请读者自行先观察一下每个任务的数据格式,这里不对任务数据进行详细介绍。
26
Jun
OCR技术浅探:9. 代码共享(完)
By 苏剑林 | 2016-06-26 | 90727位读者 | 引用
18
Dec
迟到一年的建模:再探碎纸复原
By 苏剑林 | 2014-12-18 | 112256位读者 | 引用前言:一年前国赛的时候,很初级地做了一下B题,做完之后还写了个《碎纸复原:一个人的数学建模》。当时就是对题目很有兴趣,然后通过一天的学习,基本完成了附件一二的代码,对附件三也只是有个概念。而今年我们上的数学建模课,老师把这道题作为大作业让我们做,于是我便再拾起了一年前的那份激情,继续那未完成的一个人的数学建模...
与去年不同的是,这次将所有代码用Python实现了,更简洁,更清晰,甚至可能更高效~~以下是论文全文。
研究背景
2011年10月29日,美国国防部高级研究计划局(DARPA)宣布了一场碎纸复原挑战赛(Shredder Challenge),旨在寻找到高效有效的算法,对碎纸机处理后的碎纸屑进行复原。[1]该竞赛吸引了全美9000支参赛队伍参与角逐,经过一个多月的时间,有一支队伍成功完成了官方的题目。
近年来,碎纸复原技术日益受到重视,它显示了在碎片中“还原真相”的可能性,表明我们可以从一些破碎的片段中“解密”出原始信息来。另一方面,该技术也和照片处理领域中的“全景图拼接技术”有一定联系,该技术是指通过若干张不同侧面的照片,合成一张完整的全景图。因此,分析研究碎纸复原技术,有着重要的意义。
写在前面:作为离散数学的实验作业,我选择了研究数独。经过测试发现,数独的自动推理还不算难,我把两种常规的推理思路转化为了计算机代码,并结合了随机性推导,得到了一个解题能力还不错的数独程序。事实上,本文的程序还可以进一步优化,以得到更高能力的数独程序(只需要整理一下代码,加上几个循环和判断即可),但是我实在太懒,没有动力继续弄下去了,就这样先和大家分享吧。最后,笔者认为本文的算法是更接近我们的思维的算法。
数独简介
历史
相传数独源起于拉丁方阵(Latin Square),1970年代在美国发展,改名为数字拼图(Number Place)、之后流传至日本并发扬光大,以数学智力游戏智力拼图游戏发表。在1984年一本游戏杂志《パズル通信ニコリ》正式把它命名为数独,意思是“在每一格只有一个数字”。后来一位前任香港高等法院的新西兰籍法官高乐德(Wayne Gould)在1997年3月到日本东京旅游时,无意中发现了。他首先在英国的《泰晤士报》上发表,不久其他报纸也发表,很快便风靡全英国,之后他用了6年时间编写了电脑程式,并将它放在网站上,使这个游戏很快在全世界流行。
台湾于2005年5月由“中国时报”首度引进, 且每日连载, 亦造成很大的回响。台湾数独发展协会(Taiwan Sudoku Association, 简称 TSA)亦为世界解谜联盟会员。香港是在2005年7月30日由AM730在创刊时引入数独。中国大陆是在2007年2月28日正式引入数独。北京晚报智力休闲数独俱乐部(数独联盟前身)在新闻大厦举行加入世界谜题联合会的颁证仪式,成为世界谜题联合会的39个成员之一。(引用自“中文维基百科”: http://zh.wikipedia.org/wiki/数独)
22
Sep
一个人的数学建模:碎纸复原
By 苏剑林 | 2013-09-22 | 47014位读者 | 引用
suizhiji
笔者一直无心参加数学竞赛,主要原因是我喜欢能够持续深入地思考一个问题,而不想被竞赛的时间限制所束缚。我并不是一个机灵的人,因此很难有竞赛所需要的“灵光一现”。大概一个多星期前全国数学建模的预赛开始了,我也饶有兴致地关注了一下,并且留意到了B题这道有趣的题目——碎纸复原,然后就开始思考算法了。那时候应该是9月13日中午,我开始了一个人的数学建模,“一个人”并不是说我一个人就组成一支队了,而是我一个人自由高效地在构思算法、摸索代码,不为比赛,只为达到目的,那种兴奋一直持续到了当晚凌晨三点。
28
Sep
开始学习数学软件Scilab
By 苏剑林 | 2012-09-28 | 51220位读者 | 引用其实很早之前我就想学习一款数学软件的使用,以前很感兴趣的是mathematica,也玩弄过一阵子,但毕竟在高中没有多大需要,也就没有坚持下来。更重要的是,这些软件都是要收费的。上了大学后,听了师兄姐对数学建模的讲述,发现他们基本上也是用mathematica或者matlab的,但这两个软件都是要收费的,我不大想用破解版本。既然我都已经用上了ubuntu了,那么我就该好好利用它。据说命令跟matlab很相似的软件是scilab,还有octave,不同的是这些都是开源免费的。
出于熟悉代码操作和数学软件编程的目的,我选择了学习scilab。虽然网上说octave与matlab的相似程度更高,但是我感觉scilab比octave用的更广一些,所以就用它。所谓“一理通百理明”,先专心学好一个。
下面是我编写的第一个scialb程序,利用威尔逊方法来进行素性测试。这个代码的主要目的是练习条件语句和循环语句,以及一些输出输入的技巧而已。程序本身比较丑陋。
//我的第一个scilab程序
//完成于2012.09.27
label1=['p:';]; //定义标签
B=x_mdialog(['本程序使用威尔逊方法判断进行素数测试。';'请输入要判断的数'],label1,['127';]); //输入框
p=evstr(B(1)); //提取输入框里边的数字进行赋值
i=1;
j=1;
q=p-1;
while i<q
j=j*i;
j=modulo(j,p);//这个是模函数。
i=i+1;
end
if j==1
messagebox(['这是一个素数';],['测试结果']); //输出,其中后边的“测试结果”是输入框的标题
else
messagebox(['这是一个合数';],['测试结果']);
end

最近评论