






9
Aug
素数之美2:Bertrand假设的证明
By 苏剑林 | 2014-08-09 | 23316位读者 | 引用有了上一篇文章的$\prod\limits_{p\leq n}p < 4^{n-1}$的基础,我们其实已经很接近Bertrand假设的证明了。Bertrand假设的证明基于对二项式系数$C_n^{2n}$的素因子次数的细致考察,而在本篇文章中,我们先得到一个关于素数之积的下限公式,然后由此证明一个比Bertrand假设稍微弱一点的假设。最后,则通过一个简单的技巧,将我们的证明推动至Bertrand假设。
二项式系数的素因子
首先,我们考察$n!$中的素因子$p$的次数,结果是被称为Legendre定理的公式:
$n$中素因子$p$的次数恰好为$\sum\limits_{k\geq 1}\left\lfloor\frac{n}{p^k}\right\rfloor$。
证明很简单,因为$n!=1\times 2\times 3\times 4\times \dots \times n$,每隔$p$就有一个$p$的倍数,每隔$p^2$就有一个$p^2$的倍数,每隔$p^3$就有一个$p^3$的倍数,每增加一次幂,将多贡献一个$p$因子,所以把每个间隔数叠加即可。注意该和虽然写成无穷形式,但是非零项是有限的。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 261395位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
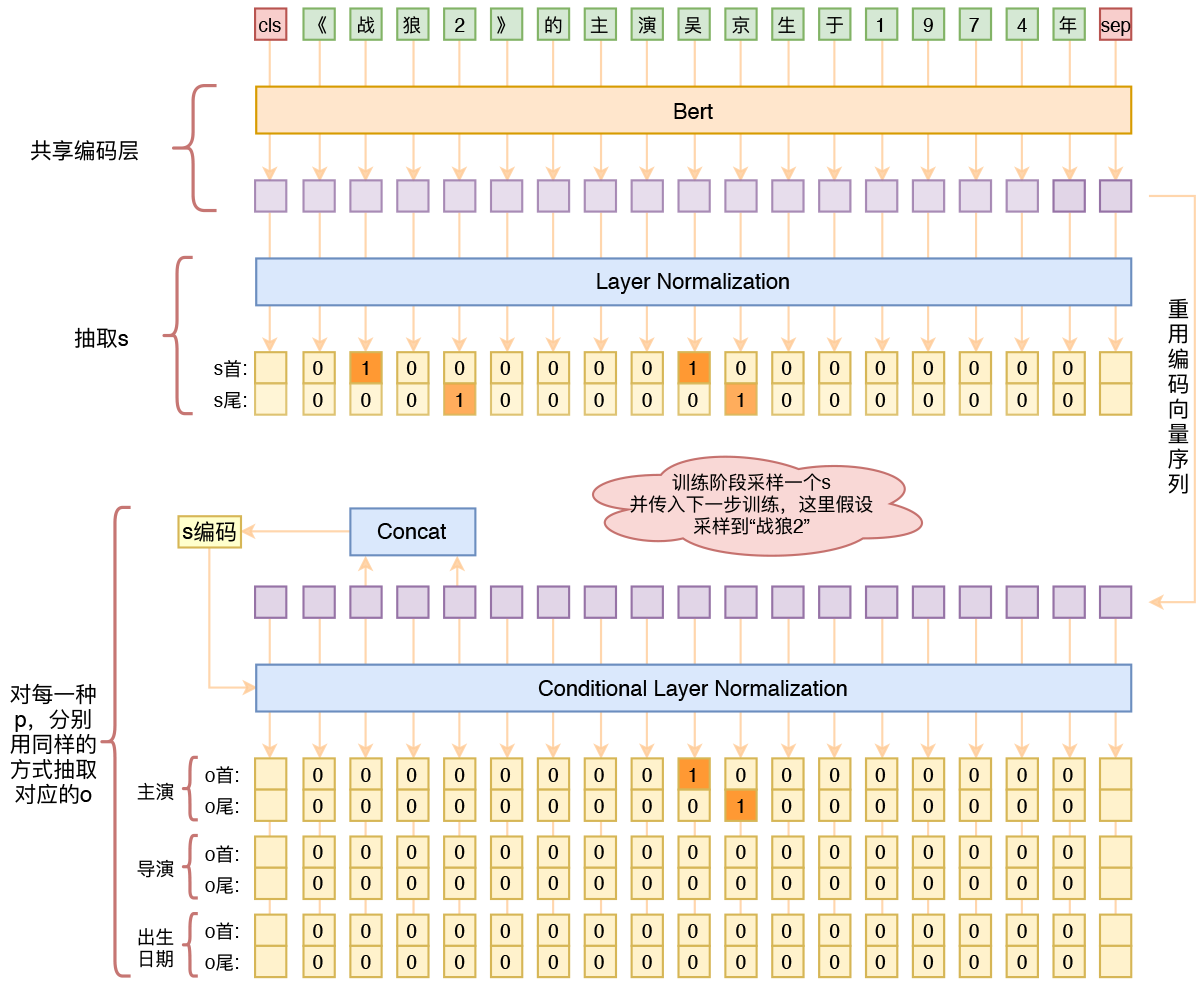
基于Bert的三元组抽取模型结构示意图
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 430208位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
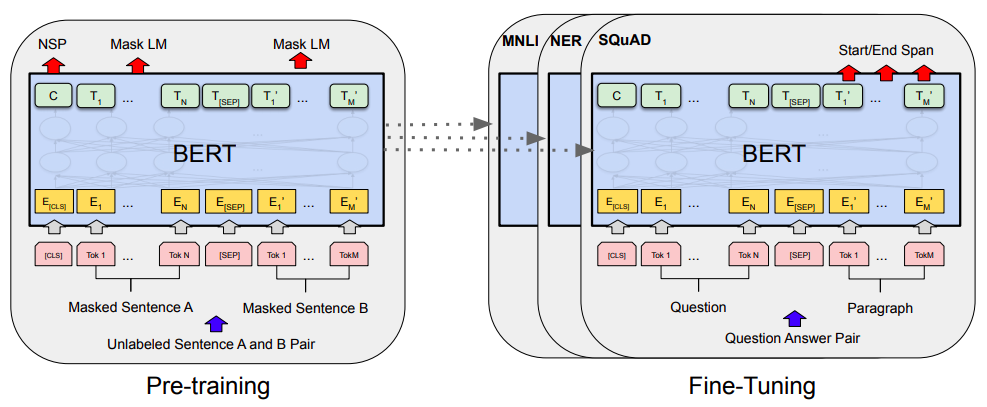
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
27
Aug
自己实现了一个bert4keras
By 苏剑林 | 2019-08-27 | 181874位读者 | 引用分享个人实现的bert4keras:
29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 144157位读者 | 引用在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 82231位读者 | 引用
2
Apr
bert4keras在手,baseline我有:百度LIC2020
By 苏剑林 | 2020-04-02 | 95395位读者 | 引用百度的“2020语言与智能技术竞赛”开赛了,今年有五个赛道,分别是机器阅读理解、推荐任务对话、语义解析、关系抽取、事件抽取。每个赛道中,主办方都给出了基于PaddlePaddle的baseline模型,这里笔者也基于bert4keras给出其中三个赛道的个人baseline,从中我们可以看到用bert4keras搭建baseline模型的方便快捷与简练。
思路简析
这里简单分析一下这三个赛道的任务特点以及对应的baseline设计。
18
May
鱼与熊掌兼得:融合检索和生成的SimBERT模型
By 苏剑林 | 2020-05-18 | 298082位读者 | 引用前段时间我们开放了一个名为SimBERT的模型权重,它是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明。在这篇文章里,我们来补充这部分内容。
UniLM
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。我们之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

UniLM的Mask
关于站长
智能搜索
支持整句搜索!网站自动使用结巴分词进行分词,并结合ngrams排序算法给出合理的搜索结果。

最近评论