






20
Mar
【福岛核电站】“最坏情况”有多坏?
By 苏剑林 | 2011-03-20 | 25346位读者 | 引用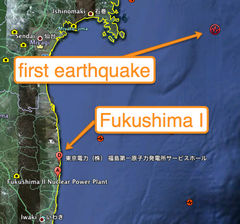
昨天在上“科学计算软件”课时,讲到了一个“抢15”游戏(Pick15),就是在1~9这9个数字中,双方轮流选一个数字,不可重复,谁的数字中有三个数字的和为15的,谁就是赢家。
这是个简单的游戏,属于博弈论范畴。在博弈论中有一个著名的“策梅洛定理”(Zermelo's theorem),它指出在二人的有限游戏中,如果双方皆拥有完全的资讯,并且运气因素并不牵涉在游戏中,那先行或后行者当一必有一方有必胜/必不败的策略。比如中国象棋就属于这一类游戏,它告诉我们对于其中一方必有一种必不败策略(有可能和棋,有可能胜,反正不会输)。当然,策梅洛定理只是告诉我们其存在性,并没有告诉我们怎么发现这个策略,甚至连哪一方有这种最优策略都没有给出判别方法。这是幸运的,因为如果真有一天发现了这种策略,那么像象棋这类博弈就失去了意义了。
上述的抢15游戏当然也属于这类游戏。不同于象棋的千变万化,它的变化比较简单,而且很容易看出它对先手有着明显的优势。下面我们来分析一下。
这已经是去年写的稿件了,刊登在今年二月份的《天文爱好者》上,本文的标题还登载了该期天爱的封面上,当时甚是高兴呢!在此与大家分享、共勉。
相信许多天文爱好者都知道第一、第二、第三宇宙速度的概念,也会有不少的天爱自己动手计算过它们。我们道,只要发射速度达到7.9km/s,宇宙飞船就可以绕地球运行了;超过11.2km/s,就可以抛开地球,成为太阳系的一颗“人造行星”;再大一点,超过16.7km/s,那么就连太阳也甩掉了,直奔深空。
16.7km/s,咋看上去并不大,因为地球绕太阳运行的速度已经是30km/s了,这个速度在宇宙中实在是太普通了。但是对于我们目前的技术来说,它大得有点可怕。维基百科上的资料显示,史上最强劲的火箭土星五号在运送阿波罗11号到月球时,飞船最终也只能加速到接近逃逸速度,即11.2km/s,而事实上第三宇宙速度已经是是目前人造飞行器的速度极限了。可是没有速度,我们就不能发射探测器去探索深空,那些科幻小说中的“星际移民”,就永远只能停留在小说上了。
13
Feb
Designing GANs:又一个GAN生产车间
By 苏剑林 | 2020-02-13 | 34166位读者 | 引用在2018年的文章里《f-GAN简介:GAN模型的生产车间》笔者介绍了f-GAN,并评价其为GAN模型的“生产车间”,顾名思义,这是指它能按照固定的流程构造出很多不同形式的GAN模型来。前几天在arxiv上看到了新出的一篇论文《Designing GANs: A Likelihood Ratio Approach》(后面简称Designing GANs或原论文),发现它在做跟f-GAN同样的事情,但走的是一条截然不同的路(不过最后其实是殊途同归),整篇论文颇有意思,遂在此分享一番。
f-GAN回顾
从《f-GAN简介:GAN模型的生产车间》中我们可以知道,f-GAN的首要步骤是找到满足如下条件的函数$f$:
1、$f$是非负实数到实数的映射($\mathbb{R}^* \to \mathbb{R}$);
2、$f(1)=0$;
3、$f$是凸函数。
17
Jun
OCR技术浅探:2. 背景与假设
By 苏剑林 | 2016-06-17 | 39121位读者 | 引用研究背景
关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不少成熟的OCR技术和产品产生,比如汉王OCR、ABBYY FineReader、Tesseract OCR等. 值得一提的是,ABBYY FineReader不仅正确率高(包括对中文的识别),而且还能保留大部分的排版效果,是一个非常强大的OCR商业软件.
然而,在诸多的OCR成品中,除了Tesseract OCR外,其他的都是闭源的、甚至是商业的软件,我们既无法将它们嵌入到我们自己的程序中,也无法对其进行改进. 开源的唯一选择是Google的Tesseract OCR,但它的识别效果不算很好,而且中文识别正确率偏低,有待进一步改进.
综上所述,不管是为了学术研究还是实际应用,都有必要对OCR技术进行探究和改进. 我们队伍将完整的OCR系统分为“特征提取”、“文字定位”、“光学识别”、“语言模型”四个方面,逐步进行解决,最终完成了一个可用的、完整的、用于印刷文字的OCR系统. 该系统可以初步用于电商、微信等平台的图片文字识别,以判断上面信息的真伪.
研究假设
在本文中,我们假设图像的文字部分有以下的特征:
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 57072位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
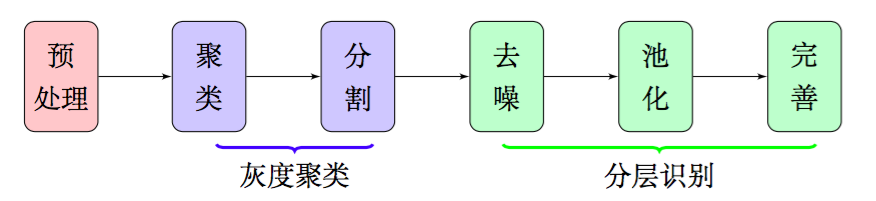
图2:特征提取大概流程
26
Jun
OCR技术浅探:8. 综合评估
By 苏剑林 | 2016-06-26 | 29855位读者 | 引用数据验证
尽管在测试环境下模型工作良好,但是实践是检验真理的唯一标准. 在本节中,我们通过自己的模型,与京东的测试数据进行比较验证.
衡量OCR系统的好坏有两部分内容:(1)是否成功地圈出了文字;(2)对于圈出来的文字,有没有成功识别. 我们采用评分的方法,对每一张图片的识别效果进行评分. 评分规则如下:
如果圈出的文字区域能够跟京东提供的检测样本的box文件中匹配,那么加1分,如果正确识别出文字来,另外加1分,最后每张图片的分数是前面总分除以文字总数.
按照这个规则,每张图片的评分最多是2分,最少是0分. 如果评分超过1,说明识别效果比较好了. 经过京东的测试数据比较,我们的模型平均评分大约是0.84,效果差强人意。
7
Apr
【不可思议的Word2Vec】 3.提取关键词
By 苏剑林 | 2017-04-07 | 201415位读者 | 引用本文主要是给出了关键词的一种新的定义,并且基于Word2Vec给出了一个实现方案。这种关键词的定义是自然的、合理的,Word2Vec只是一个简化版的实现方案,可以基于同样的定义,换用其他的模型来实现。
说到提取关键词,一般会想到TF-IDF和TextRank,大家是否想过,Word2Vec还可以用来提取关键词?而且,用Word2Vec提取关键词,已经初步含有了语义上的理解,而不仅仅是简单的统计了,而且还是无监督的!
什么是关键词?
诚然,TF-IDF和TextRank是两种提取关键词的很经典的算法,它们都有一定的合理性,但问题是,如果从来没看过这两个算法的读者,会感觉简直是异想天开的结果,估计很难能够从零把它们构造出来。也就是说,这两种算法虽然看上去简单,但并不容易想到。试想一下,没有学过信息相关理论的同学,估计怎么也难以理解为什么IDF要取一个对数?为什么不是其他函数?又有多少读者会破天荒地想到,用PageRank的思路,去判断一个词的重要性?
说到底,问题就在于:提取关键词和文本摘要,看上去都是一个很自然的任务,有谁真正思考过,关键词的定义是什么?这里不是要你去查汉语词典,获得一大堆文字的定义,而是问你数学上的定义。关键词在数学上的合理定义应该是什么?或者说,我们获取关键词的目的是什么?

最近评论