






13
Feb
MathPlayer 2.2发布,大家升级啦!
By 苏剑林 | 2010-02-13 | 19675位读者 | 引用如果你已经安装了MathPlayer,就这里检查一下你的版本是否最新版:
http://www.dessci.com/en/products/mathplayer/check.htm
如果你还没有安装,欢迎你点击下面的链接下载安装:
http://www.dessci.com/en/products/mathplayer/download.htm
7
Mar
通过ssh动态端口转发共享校园资源(附带干货)
By 苏剑林 | 2016-03-07 | 36520位读者 | 引用众所周知,校园网最宝贵的资源应该有两样:一是IPv6,IPv6是访问Google等网站的最理想途径,当然IPv6并非所有高校都有;二是论文库,一般高校都会买了一部分论文库(知网、万方等)的下载权,供校园用户使用。如果说访问Google还有VPN等诸多方式的话,那么对于校外用户来说访问知网等资源就显得格外宝贵了,一般只是叫校内用户下载,或者就只能付费了(那个贵呀!)。
站长还是学生,在学校同时享用着IPv6和论文库资源,确实很爽。自从用上Openwrt的路由之后,一直想着怎么把校园网资源共享出去。曾经考虑过搭建PPTP VPN,但是感觉略有复杂(当然,跟其他VPN相比,搭建PPTP VPN算是非常简单的了,可是我还是不怎么喜欢。),而且当时还没解决内网穿透的问题。最近借助ssh反向代理的方式实现了内网穿透,继而认识到,通过ssh动态端口转发,居然还可以搭建代理,并且实现远程访问内网(校园网)资源,而且几乎不用在路由器本身上面做任何配置。不得不说,ssh真是一个极其强大的东西呀。
添加普通帐号
既然要共享,就没理由把root账户都分享出去了,因此,第一步要实现的是在Openwrt上添加一个代理账号,而且为了安全和保密,这个账号不允许真的登陆服务器进行操作,而只允许进行端口转发。
31
Dec
2017年快乐!Responsive Geekg for Typecho
By 苏剑林 | 2016-12-31 | 34692位读者 | 引用
27
Aug
fashion mnist的一个baseline (MobileNet 95%)
By 苏剑林 | 2017-08-27 | 81391位读者 | 引用浅尝
昨天简单试了一下在fashion mnist的gan模型,发现还能work,当然那个尝试也没什么技术水平,就是把原来的脚本改一下路径跑了就完事。今天回到fashion mnist本身的主要任务——10分类,用Keras测了一下一些模型在上面的分类效果,最后得到了94.5%左右的准确率,加上随机翻转的数据扩增能做到95%。
首先随便手写了一些模型的组合,测试发现准确率都不大好,看来对于这个数据集来说,自己构思模型是比较困难的了,于是想着用现成的模型结构。一说到现成的cnn模型,基本上我们都会想到VGG、ResNet、inception、Xception等,但这些模型为解决imagenet的1000分类问题而设计,用到这个入门级别的数据集上似乎过于庞大了,而且也容易过拟合。后来突然想起,Keras好像自带了个叫MobileNet的模型,查看了一下模型权重,发现参数量不大,但是容量应该还是可以的,故选用MobileNet做实验。
深究
6
Jan
《Attention is All You Need》浅读(简介+代码)
By 苏剑林 | 2018-01-06 | 885058位读者 | 引用2017年中,有两篇类似同时也是笔者非常欣赏的论文,分别是FaceBook的《Convolutional Sequence to Sequence Learning》和Google的《Attention is All You Need》,它们都算是Seq2Seq上的创新,本质上来说,都是抛弃了RNN结构来做Seq2Seq任务。
这篇博文中,笔者对《Attention is All You Need》做一点简单的分析。当然,这两篇论文本身就比较火,因此网上已经有很多解读了(不过很多解读都是直接翻译论文的,鲜有自己的理解),因此这里尽可能多自己的文字,尽量不重复网上各位大佬已经说过的内容。
序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_t)$,其中$\boldsymbol{x}_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$\boldsymbol{X}\in \mathbb{R}^{n\times d}$。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
\begin{equation}\boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t)\end{equation}
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 116689位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
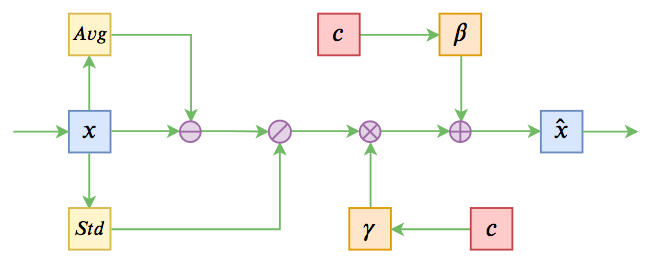
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
12
Jan
Self-Orthogonality Module:一个即插即用的核正交化模块
By 苏剑林 | 2020-01-12 | 54918位读者 | 引用前些天刷Arxiv看到新文章《Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters》(下面简称“原论文”),看上去似乎有点意思,于是阅读了一番,读完确实有些收获,在此记录分享一下。
给全连接或者卷积模型的核加上带有正交化倾向的正则项,是不少模型的需求,比如大名鼎鼎的BigGAN就加入了类似的正则项。而这篇论文则引入了一个新的正则项,笔者认为整个分析过程颇为有趣,可以一读。
为什么希望正交?
在开始之前,我们先约定:本文所出现的所有一维向量都代表列向量。那么,现在假设有一个$d$维的输入样本$\boldsymbol{x}\in \mathbb{R}^d$,经过全连接或卷积层时,其核心运算就是:
\begin{equation}\boldsymbol{y}^{\top}=\boldsymbol{x}^{\top}\boldsymbol{W},\quad \boldsymbol{W}\triangleq (\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k)\label{eq:k}\end{equation}
其中$\boldsymbol{W}\in \mathbb{R}^{d\times k}$是一个矩阵,它就被称“核”(全连接核/卷积核),而$\boldsymbol{w}_1,\boldsymbol{w}_2,\dots,\boldsymbol{w}_k\in \mathbb{R}^{d}$是该矩阵的各个列向量。
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 91446位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
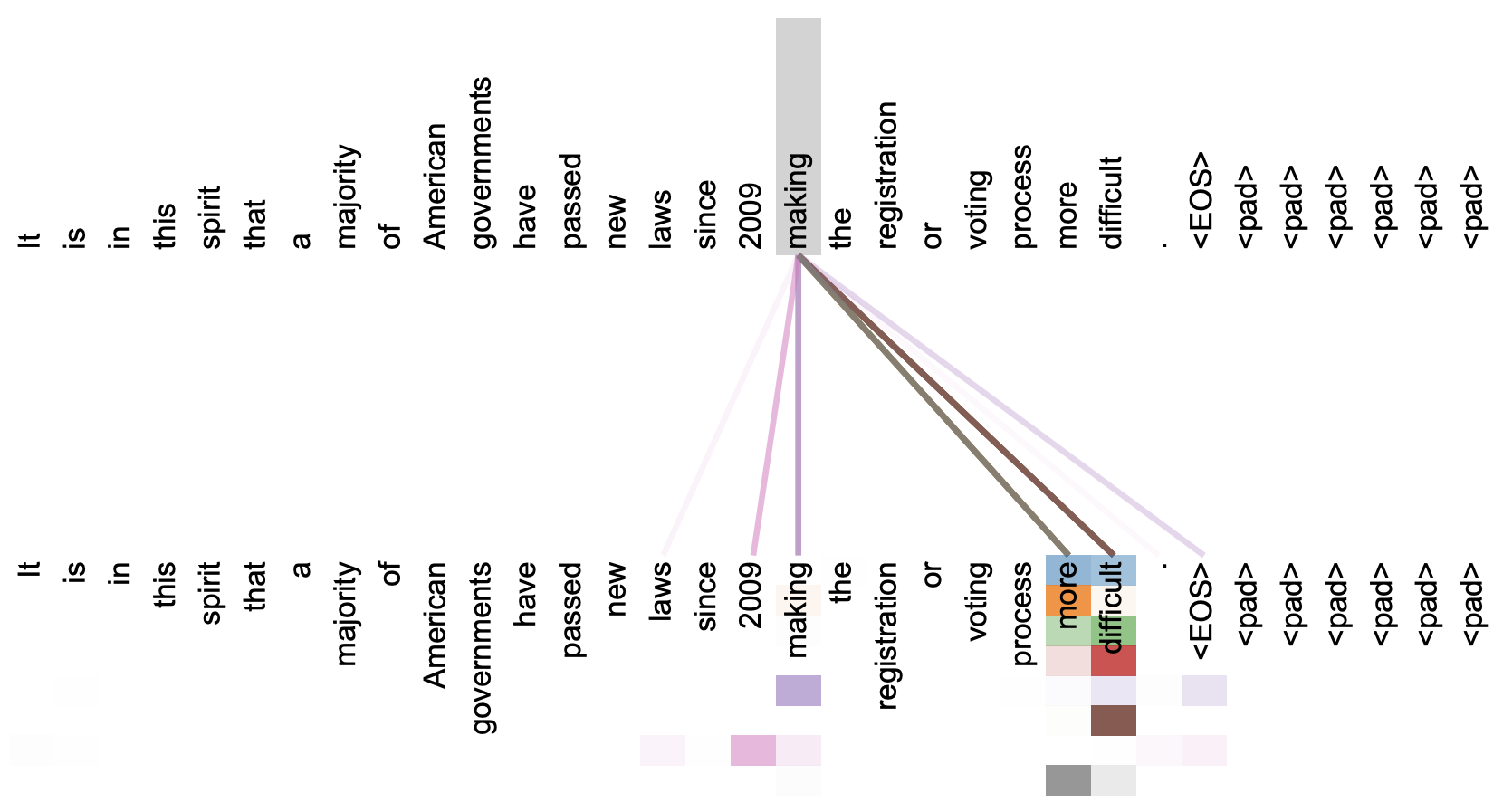
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。

最近评论