






10
Jun
【翻译】巨型望远镜:要继续,就得有牺牲!
By 苏剑林 | 2015-06-10 | 27946位读者 | 引用
2007年末公布的30米望远镜效果图
文章来自:新科学家,这是一篇关于30米望远镜(Thirty Meter Telescope,TMT)的新闻,起因是望远镜的制造遭到当地人的不满,当然背后的原因是很深远的,难以说清楚。更多有关TMT的新闻,可以阅读:http://www.ctmt.org/
夏威夷的巨型望远镜:要继续,就得有牺牲!
四分之一必须离开!在停止了两个月之后,夏威夷的巨型30米望远镜(Thirty Meter Telescope,TMT)重新回归到建设进程——但要牺牲其他望远镜。
由于夏威夷当地居民的抗议声越来越大,早在四月望远镜的建设工作就被迫暂停。与该望远镜相比,目前世界上所有的望远镜都相形见绌——它让能够让天文学家们凝视可见的宇宙的边缘。它位于许多夏威夷人认为是“神圣之地”的死火山莫纳克亚山,因此被夏威夷人认为是一种侮辱——尤其是在山顶已经有十多个望远镜了。
5
Sep
进驻中山大学南校区,折腾校园网
By 苏剑林 | 2016-09-05 | 81309位读者 | 引用开始研究僧之旅,希望有一天能企及扫地僧的境界。
进入中山大学后,各种郁闷的事情就来了。首先最郁闷的就是开学时间特早,8月26日开学,感觉至少比一般学校早了一星期,开学这么早有意思么~~接着就是感觉中大的管理制度各种混乱,比我本科的华师差多了。好吧,这些琐事先不吐槽,接下来弄校园网,这是作死的开始。
我们是在南校区的,校园网是通过锐捷客户端来认证的,而我是用macbook的,不过中大这边还很人性化地提供了Mac版的锐捷,体积就1M左右,挺好的。但众所周知,macbook并没有有线网卡,每次我上网都得插着个USB网卡然后连着网线,这该有多郁闷。于是想办法通过路由器拨号。我也不算没经验的了,对openwrt这个系统有过一定研究,以前在本科的时候也是锐捷,可以用mentohust替代拨号,很简单。于是我在这里重复这样的过程,发现一直认证失败,按照网上提示的各种方法,都无法解决。
经过研究,我发现在Windows下,这里就只能用官方提供了锐捷4.90版本,从其他地方下载的更高级或者更低级的锐捷,都无法通过验证。估计就是因为这个机制,导致了mentohust难以通过验证。而且网上流行的mentohust都是基于V2协议的,但4.90是基于V4的。后来我又去下载了V4版本的进行交叉编译,测试发现还不成功。几近绝望的时候,我发现了mentohust-proxy,一个mentohust的改进版,让我找到了希望。(怎么找到它?我是直接到github搜索了,因为实在没辙了~~)
原理很简单,如果直接通过mentohust无法完成认证,那么就通过代理模式,由电脑来完成认证,而mentohust只需要负责发送心跳包维持联网就行。这是个很折中的方案,但应该说是一个很通用的方案,因为它的成功与否,基本就取决于自己电脑的锐捷客户端而已。看到这个方案,我就知道有戏了,于是赶紧补习了一下交叉编译的知识,最后成功编译好了,并且在路由上成功地完成了认证。
1
Dec
基于双向GRU和语言模型的视角情感分析
By 苏剑林 | 2016-12-01 | 87822位读者 | 引用前段时间参加了一个傻逼的网络比赛——基于视角的领域情感分析,主页在这里。比赛的任务是找出一段话的实体然后判断情感,比如“我喜欢本田,我不喜欢丰田”这句话中,要标出“本田”和“丰田”,并且站在本田的角度,情感是积极的,站在丰田的角度,情感就是消极的。也就是说,等价于将实体识别和情感分析结合起来了。
吐槽
看起来很高端,哪里傻逼了?比赛任务本身还不错,值得研究,然而官方却很傻逼,主要体现为:1、比赛分初赛、复赛、决赛三个阶段,初赛一个多月时间,然后筛选部分进入复赛,复赛就简单换了一点数据,题目、数据的领域都没有变化,复赛也是一个月的时间,这傻逼复赛究竟有什么意义?2、大家可以看看选手们在群里讨论什么:
26
Aug
细水长flow之RealNVP与Glow:流模型的传承与升华
By 苏剑林 | 2018-08-26 | 315364位读者 | 引用话在开头
上一篇文章《细水长flow之NICE:流模型的基本概念与实现》中,我们介绍了flow模型中的一个开山之作:NICE模型。从NICE模型中,我们能知道flow模型的基本概念和基本思想,最后笔者还给出了Keras中的NICE实现。
本文我们来关心NICE的升级版:RealNVP和Glow。
精巧的flow
不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入$\boldsymbol{x}$编码为隐变量$\boldsymbol{z}$,并且使得$\boldsymbol{z}$服从标准正态分布。得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建。
为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。
31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 68322位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
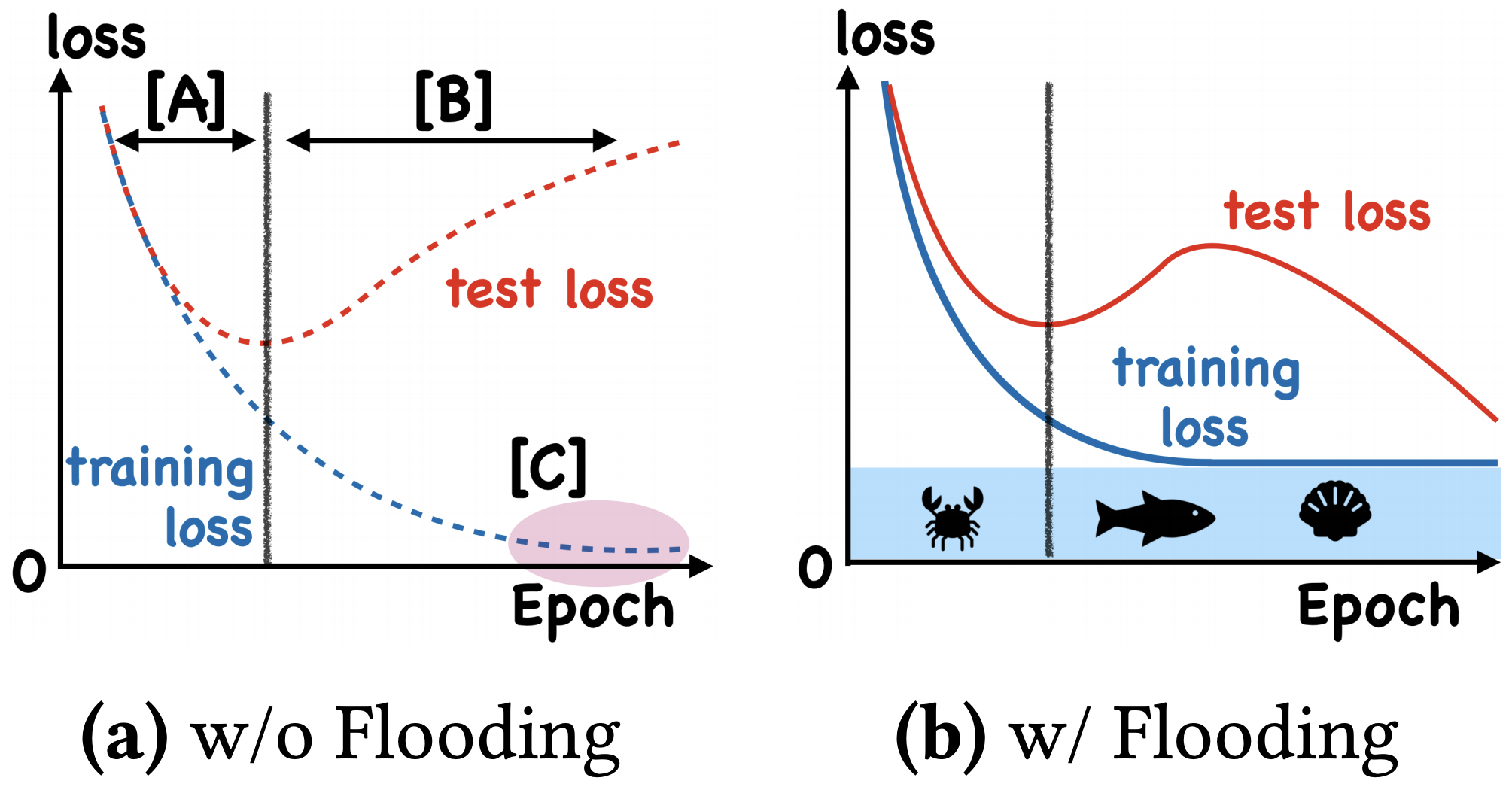
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图

最近评论