






14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 116708位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
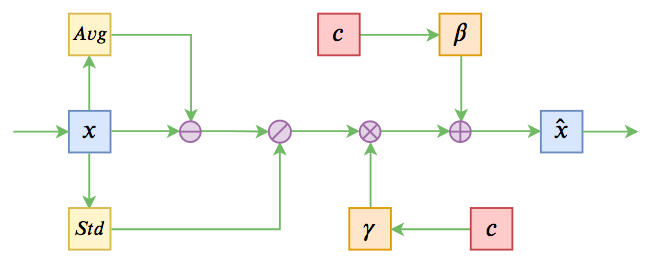
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
19
Apr
从DCGAN到SELF-MOD:GAN的模型架构发展一览
By 苏剑林 | 2019-04-19 | 81457位读者 | 引用事实上,O-GAN的发现,已经达到了我对GAN的理想追求,使得我可以很惬意地跳出GAN的大坑了。所以现在我会试图探索更多更广的研究方向,比如NLP中还没做过的任务,又比如图神经网络,又或者其他有趣的东西。
不过,在此之前,我想把之前的GAN的学习结果都记录下来。
这篇文章中,我们来梳理一下GAN的架构发展情况,当然主要的是生成器的发展,判别器一直以来的变动都不大。还有,本文介绍的是GAN在图像方面的模型架构发展,跟NLP的SeqGAN没什么关系。
此外,关于GAN的基本科普,本文就不再赘述了。

棋盘效应图示,体现为放大之后出现如国际象棋棋盘一样的交错效应。图片来自文章《Deconvolution and Checkerboard Artifacts》
1
Dec
级联抑制:提升GAN表现的一种简单有效的方法
By 苏剑林 | 2019-12-01 | 34111位读者 | 引用昨天刷arxiv时发现了一篇来自星星韩国的论文,名字很直白,就叫做《A Simple yet Effective Way for Improving the Performance of GANs》。打开一看,发现内容也很简练,就是提出了一种加强GAN的判别器的方法,能让GAN的生成指标有一定的提升。
作者把这个方法叫做Cascading Rejection,我不知道咋翻译,扔到百度翻译里边显示“级联抑制”,想想看好像是有这么点味道,就暂时这样叫着了。介绍这个方法倒不是因为它有多强大,而是觉得它的几何意义很有趣,而且似乎有一定的启发性。
正交分解
GAN的判别器一般是经过多层卷积后,通过flatten或pool得到一个固定长度的向量$\boldsymbol{v}$,然后再与一个权重向量$\boldsymbol{w}$做内积,得到一个标量打分(先不考虑偏置项和激活函数等末节):
\begin{equation}D(\boldsymbol{x})=\langle \boldsymbol{v},\boldsymbol{w}\rangle\end{equation}
也就是说,用$\boldsymbol{v}$作为输入图片的表征,然后通过$\boldsymbol{v}$和$\boldsymbol{w}$的内积大小来判断出这个图片的“真”的程度。
25
Nov
6个派生优化器的简单介绍及其实现
By 苏剑林 | 2019-11-25 | 52590位读者 | 引用优化器可能是深度学习最“玄学”的一个模块之一了:有时候换一个优化器就能带来明显的提升,有时候别人说提升很多的优化器用到自己的任务上却一丁点用都没有,理论性质好的优化器不一定工作得很好,纯粹拍脑袋而来的优化器也未必就差了。但不管怎样,优化器终究也为热爱“深度炼丹”的同学提供了多一个选择。
近几年来,关于优化器的工作似乎也在慢慢增多,很多论文都提出了对常用优化器(尤其是Adam)的大大小小的改进。本文就汇总一些优化器工作或技巧,并统一给出了代码实现,供读者有需调用。
基本形式
所谓“派生”,就是指相关的技巧都是建立在已有的优化器上的,任意一个已有的优化器都可以用上这些技巧,从而变成一个新的优化器。
已有的优化器的基本形式为:
\begin{equation}\begin{aligned}\boldsymbol{g}_t =&\, \nabla_{\boldsymbol{\theta}} L\\
\boldsymbol{h}_t =&\, f(\boldsymbol{g}_{\leq t})\\
\boldsymbol{\theta}_{t+1} =&\, \boldsymbol{\theta}_t - \gamma \boldsymbol{h}_t
\end{aligned}\end{equation}
其中$\boldsymbol{g}_t$即梯度,而$\boldsymbol{g}_{\leq t}$指的是截止到当前步的所有梯度信息,它们经过某种运算$f$(比如累积动量、累积二阶矩校正学习率等)后得到$\boldsymbol{h}_t$,然后由$\boldsymbol{h}_t$来更新参数,这里的$\gamma$就是指学习率。
29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 142599位读者 | 引用在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
27
Oct
什么时候多进程的加速比可以大于1?
By 苏剑林 | 2019-10-27 | 59747位读者 | 引用多进程或者多线程等并行加速目前已经不是什么难事了,相信很多读者都体验过。一般来说,我们会有这样的结论:多进程的加速比很难达到1。换句话说,当你用10进程去并行跑一个任务时,一般只能获得不到10倍的加速,而且进程越多,这个加速比往往就越低。
要注意,我们刚才说“很难达到1”,说明我们的潜意识里就觉得加速比最多也就是1。理论上确实是的,难不成用10进程还能获得20倍的加速?这不是天上掉馅饼吗?不过我前几天确实碰到了一个加速比远大于1的例子,所以在这里跟大家分享一下。
词频统计
我的原始任务是统计词频:我有很多文章,然后我们要对这些文章进行分词,最后汇总出一个词频表出来。一般的写法是这样的:
tokens = {}
for text in read_texts():
for token in tokenize(text):
tokens[token] = tokens.get(token, 0) + 1这种写法在我统计THUCNews全部文章的词频时,大概花了20分钟。
9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 97291位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
29
Apr
节省显存的重计算技巧也有了Keras版了
By 苏剑林 | 2020-04-29 | 49915位读者 | 引用不少读者最近可能留意到了公众号文章《BERT重计算:用22.5%的训练时间节省5倍的显存开销(附代码)》,里边介绍了一个叫做“重计算”的技巧,简单来说就是用来省显存的方法,让平均训练速度慢一点,但batch_size可以增大好几倍。该技巧首先发布于论文《Training Deep Nets with Sublinear Memory Cost》,其实在2016年就已经提出了,只不过似乎还没有特别流行起来。
探索
公众号文章提到该技巧在pytorch和paddlepaddle都有原生实现了,但tensorflow还没有。但事实上从tensorflow 1.8开始,tensorflow就已经自带了该功能了,当时被列入了tf.contrib这个子库中,而从tensorflow 1.15开始,它就被内置为tensorflow的主函数之一,那就是tf.recompute_grad。
找到tf.recompute_grad之后,笔者就琢磨了一下它的用法,经过一番折腾,最终居然真的成功地用起来了,居然成功地让batch_size从48增加到了144!然而,在继续整理测试的过程中,发现这玩意居然在tensorflow 2.x是失效的...于是再折腾了两天,查找了各种资料并反复调试,最终算是成功地补充了这一缺陷。
最后是笔者自己的开源实现:
该实现已经内置在bert4keras中,使用bert4keras的读者可以升级到最新版本(0.7.5+)来测试该功能。

最近评论