






1
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(一)
By 苏剑林 | 2015-12-01 | 83747位读者 | 引用熵的概念
作为一名物理爱好者,我一直对统计力学中“熵”这个概念感到神秘和好奇。因此,当我接触数据科学的时候,我也对最大熵模型产生了浓厚的兴趣。
熵是什么?在通俗的介绍中,熵一般有两种解释:(1)熵是不确定性的度量;(2)熵是信息的度量。看上去说的不是一回事,其实它们说的就是同一个意思。首先,熵是不确定性的度量,它衡量着我们对某个事物的“无知程度”。熵为什么又是信息的度量呢?既然熵代表了我们对事物的无知,那么当我们从“无知”到“完全认识”这个过程中,就会获得一定的信息量,我们开始越无知,那么到达“完全认识”时,获得的信息量就越大,因此,作为不确定性的度量的熵,也可以看作是信息的度量,说准确点,是我们能从中获得的最大的信息量。
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 57039位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
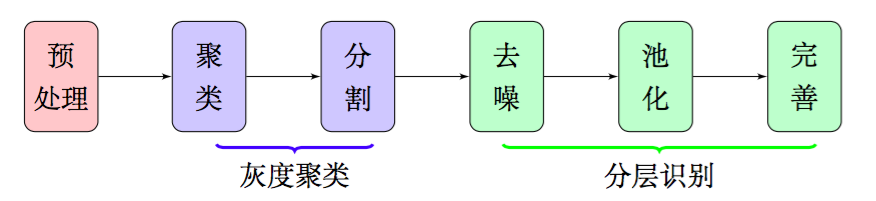
图2:特征提取大概流程
23
Feb
SVD分解(三):连Word2Vec都只不过是个SVD?
By 苏剑林 | 2017-02-23 | 97206位读者 | 引用这篇文章要带来一个“重磅”消息,如标题所示,居然连大名鼎鼎的深度学习词向量工具Word2Vec都只不过是个SVD!
当然,Word2Vec的超级忠实粉丝们,你们也不用太激动,这里只是说模型结构上是等价的,并非完全等价,Word2Vec还是有它的独特之处。只不过,经过我这样解释之后,估计很多问题就可以类似想通了。
词向量=one hot
让我们先来回顾一下去年的一篇文章《词向量与Embedding究竟是怎么回事?》,这篇文章主要说的是:所谓Embedding层,就是一个one hot的全连接层罢了(再次强调,这里说的完全等价,而不是“相当于”),而词向量,就是这个全连接层的参数;至于Word2Vec,就通过大大简化的语言模型来训练Embedding层,从而得到词向量(它的优化技巧有很多,但模型结构就只是这么简单);词向量能够减少过拟合风险,是因为用Word2Vec之类的工具、通过大规模语料来无监督地预训练了这个Embedding层,而跟one hot还是Embedding还是词向量本身没啥关系。
有了这个观点后,马上可以解释我们以前的一个做法为什么可行了。在做情感分类问题时,如果有了词向量,想要得到句向量,最简单的一个方案就是直接对句子中的词语的词向量求和或者求平均,这约能达到85%的准确率。事实上这也是facebook出品的文本分类工具FastText的做法了(FastText还多引入了ngram特征,来缓解词序问题,但总的来说,依旧是把特征向量求平均来得到句向量)。为什么这么一个看上去毫不直观的、简单粗暴的方案也能达到这么不错的准确率?
12
Feb
再来一顿贺岁宴:从K-Means到Capsule
By 苏剑林 | 2018-02-12 | 225695位读者 | 引用在本文中,我们再次对Capsule进行一次分析。
整体上来看,Capsule算法的细节不是很复杂,对照着它的流程把Capsule用框架实现它基本是没问题的。所以,困难的问题是理解Capsule究竟做了什么,以及为什么要这样做,尤其是Dynamic Routing那几步。
为什么我要反复对Capsule进行分析?这并非单纯的“炒冷饭”,而是为了得到对Capsule原理的理解。众所周知,Capsule给人的感觉就是“有太多人为约定的内容”,没有一种“虽然我不懂,但我相信应该就是这样”的直观感受。我希望尽可能将Capsule的来龙去脉思考清楚,使我们能觉得Capsule是一个自然、流畅的模型,甚至对它举一反三。
在《揭开迷雾,来一顿美味的Capsule盛宴》中,笔者先分析了动态路由的结果,然后指出输出是输入的某种聚类,这个“从结果到原因”的过程多多少少有些望文生义的猜测成分;这次则反过来,直接确认输出是输入的聚类,然后反推动态路由应该是怎样的,其中含糊的成分大大减少。两篇文章之间有一定的互补作用。
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 217038位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
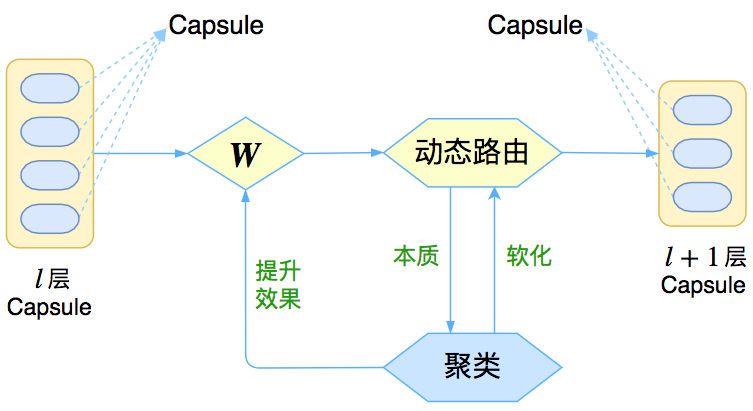
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 977701位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量$Z$生成目标数据$X$的模型,但是实现上有所不同。更准确地讲,它们是假设了$Z$服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型$X=g(Z)$,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
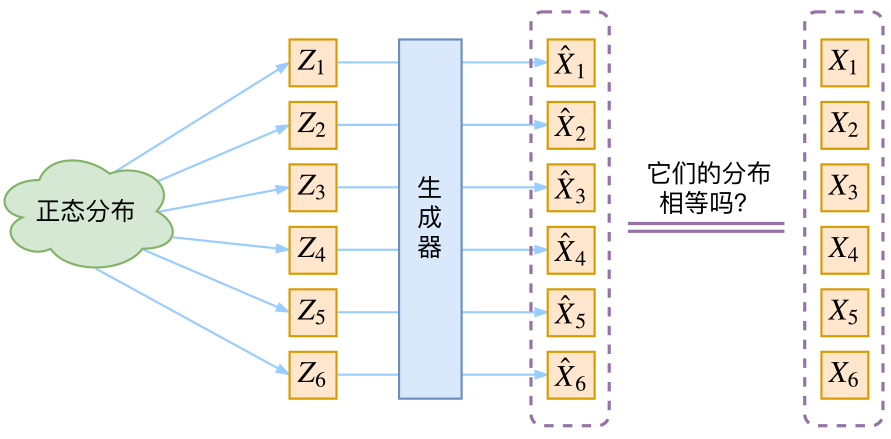
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
3
Apr
变分自编码器(三):这样做为什么能成?
By 苏剑林 | 2018-04-03 | 190957位读者 | 引用话说我觉得我自己最近写文章都喜欢长篇大论了,而且扎堆地来~之前连续写了三篇关于Capsule的介绍,这次轮到VAE了,本文是VAE的第三篇探索,说不准还会有第四篇~不管怎么样,数量不重要,重要的是能把问题都想清楚。尤其是对于VAE这种新奇的建模思维来说,更加值得细细地抠。
这次我们要关心的一个问题是:VAE为什么能成?
估计看VAE的读者都会经历这么几个阶段。第一个阶段是刚读了VAE的介绍,然后云里雾里的,感觉像自编码器又不像自编码器的,反复啃了几遍文字并看了源码之后才知道大概是怎么回事;第二个阶段就是在第一个阶段的基础上,再去细读VAE的原理,诸如隐变量模型、KL散度、变分推断等等,细细看下去,发现虽然折腾来折腾去,最终居然都能看明白了。
这时候读者可能就进入第三个阶段了。在这个阶段中,我们会有诸多疑问,尤其是可行性的疑问:“为什么它这样反复折腾,最终出来模型是可行的?我也有很多想法呀,为什么我的想法就不行?”
前文之要
让我们再不厌其烦地回顾一下前面关于VAE的一些原理。
VAE希望通过隐变量分解来描述数据$X$的分布
$$p(x)=\int p(x|z)p(z)dz,\quad p(x,z) = p(x|z)p(z)\tag{1}$$
13
Jun
“噪声对比估计”杂谈:曲径通幽之妙
By 苏剑林 | 2018-06-13 | 178121位读者 | 引用说到噪声对比估计,或者“负采样”,大家可能立马就想到了Word2Vec。事实上,它的含义远不止于此,噪音对比估计(NCE, Noise Contrastive Estimation)是一个迂回但却异常精美的技巧,它使得我们在没法直接完成归一化因子(也叫配分函数)的计算时,就能够去估算出概率分布的参数。本文就让我们来欣赏一下NCE的曲径通幽般的美妙。
注:由于出发点不同,本文所介绍的“噪声对比估计”实际上更偏向于所谓的“负采样”技巧,但两者本质上是一样的,在此不作区分。
问题起源
问题的根源是难分难舍的指数概率分布~
指数族分布
在很多问题中都会出现指数族分布,即对于某个变量$\boldsymbol{x}$的概率$p(\boldsymbol{x})$,我们将其写成
$$p(\boldsymbol{x}) = \frac{e^{G(\boldsymbol{x})}}{Z}\tag{1}$$
其中$G(\boldsymbol{x})$是$\boldsymbol{x}$的某个“能量”函数,而$Z=\sum_{\boldsymbol{x}} e^{G(\boldsymbol{x})}$则是归一化常数,也叫配分函数。这种分布也称为“玻尔兹曼分布”。

最近评论