






11
Aug
细水长flow之NICE:流模型的基本概念与实现
By 苏剑林 | 2018-08-11 | 280539位读者 | 引用前言:自从在机器之心上看到了glow模型之后(请看《下一个GAN?OpenAI提出可逆生成模型Glow》),我就一直对其念念不忘。现在机器学习模型层出不穷,我也经常关注一些新模型动态,但很少像glow模型那样让我怦然心动,有种“就是它了”的感觉。更意外的是,这个效果看起来如此好的模型,居然是我以前完全没有听说过的。于是我翻来覆去阅读了好几天,越读越觉得有意思,感觉通过它能将我之前的很多想法都关联起来。在此,先来个阶段总结。
背景
本文主要是《NICE: Non-linear Independent Components Estimation》一文的介绍和实现。这篇文章也是glow这个模型的基础文章之一,可以说它就是glow的奠基石。
艰难的分布
众所周知,目前主流的生成模型包括VAE和GAN,但事实上除了这两个之外,还有基于flow的模型(flow可以直接翻译为“流”,它的概念我们后面再介绍)。事实上flow的历史和VAE、GAN它们一样悠久,但是flow却鲜为人知。在我看来,大概原因是flow找不到像GAN一样的诸如“造假者-鉴别者”的直观解释吧,因为flow整体偏数学化,加上早期效果没有特别好但计算量又特别大,所以很难让人提起兴趣来。不过现在看来,OpenAI的这个好得让人惊叹的、基于flow的glow模型,估计会让更多的人投入到flow模型的改进中。

glow模型生成的高清人脸
27
Mar
费曼积分法(7):欧拉数学的综合
By 苏剑林 | 2013-03-27 | 36464位读者 | 引用
30
May
路径积分系列:1.我的毕业论文
By 苏剑林 | 2016-05-30 | 29050位读者 | 引用之前承诺过会把毕业论文共享出来,让大家批评指正,却一直偷懒没动。事实上,毕业论文的主要内容就是路径积分的一些入门级别的内容,标题为《随机游走、随机微分方程与偏微分方程的路径积分方法》。我的摘要是这样写的:
本文从随机游走模型出发,得到了关于随机游走模型的一般结果;然后基于随机游走模型引入了路径积分,并且通过路径积分方法,实现了随机游走、随机微分方程与抛物型微分方程的相互转化,并给出了一些计算案例.
路径积分方法是量子理论的一种形式,但实际上它可以抽象为一个有用的数学工具,本文的主要方法正是抽象后的路径积分;其次,量子力学中有一个相当典型的抛物型偏微分方程——薛定谔方程,物理学家已经对它进行了大量的研究,有众多的成果;而随机微分方程是一个微分方程的拓展,在物理、工程、金融等很多方面都有重要应用,这个领域中也有很多研究方法;最后,随机游走是一个简单而重要的模型,它是很多扩散模型的基础,而且具有容易使用计算机模拟的特性. 因此,实现三者的转化是很有意义的.
本文有一些新的内容,比如现有文献比较少研究的不对称随机游走方面、以及现有文献比较含糊的对路径积分的介绍等,可以供同好参考,希望借此方式,能够让一些读者以更简洁明了的方式理解路径积分. 但是本文主要是陈述性的,旨在在国内推广路径积分方法. 在国外,路径积分方法得到了相当的重视,它源于量子力学,但应用已经不仅仅限于量子力学,如著作[1],因此,推广路径积分方法、增加路径积分的中文资料,是很有意义和很有必要的事情.
本文所有推导和例子均以一维为例,相应的多维问题可以类似地计算。
3
Aug
生成扩散模型漫谈(五):一般框架之SDE篇
By 苏剑林 | 2022-08-03 | 197361位读者 | 引用在写生成扩散模型的第一篇文章时,就有读者在评论区推荐了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,可以说该论文构建了一个相当一般化的生成扩散模型理论框架,将DDPM、SDE、ODE等诸多结果联系了起来。诚然,这是一篇好论文,但并不是一篇适合初学者的论文,里边直接用到了随机微分方程(SDE)、Fokker-Planck方程、得分匹配等大量结果,上手难度还是颇大的。
不过,在经过了前四篇文章的积累后,现在我们可以尝试去学习一下这篇论文了。在接下来的文章中,笔者将尝试从尽可能少的理论基础出发,尽量复现原论文中的推导结果。
随机微分
在DDPM中,扩散过程被划分为了固定的$T$步,还是用《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》的类比来说,就是“拆楼”和“建楼”都被事先划分为了$T$步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。
6
Nov
【外微分浅谈】5. 几何意义
By 苏剑林 | 2016-11-06 | 71464位读者 | 引用对于前面所述的外微分,包括后面还略微涉及到的微分形式的积分,都是纯粹代数定义的内容,本身不具有任何的几何意义。但是,我们可以将某些公式或者定义,与一些几何内容对应起来,使我们更深刻地理解它,并且更灵活运用它。但是,它仅仅是一种对应,而且取决于我们的诠释。比如,我们说外微分公式
$$\int_{\partial D} Pdx+Qdy = \int_{D} \left(\frac{\partial Q}{\partial x}-\frac{\partial P}{\partial y}\right)dx\land dy \tag{32} $$
对应于格林公式
$$\int_{\partial D} Pdx+Qdy = \int_{D} \left(\frac{\partial Q}{\partial x}-\frac{\partial P}{\partial y}\right)dxdy \tag{33} $$
。这是没问题的,但它们并不等价,它们仅仅是形式上刚好一样。因为格林公式是描述闭合曲线的积分跟面积分的联系,而外微分的公式是一种纯粹的代数运算。因为你完全可以将$dx\land dy$对应于$-dxdy$而不是$dxdy$,这样就得到另外一种几何的对应。
更深刻的问题是:为什么恰好有这个对应?也就是说,为什么经过一些调整和诠释后,就能够得到与积分公式的对应?首先要明确的是外积与普通的数的乘积,除了反对称性之外,是没有任何区别的,因此不少性质得以保留;其次,还应该要回到反对称本身来考虑,矩阵的行列式代表着矩阵所对应的向量组张成的$n$维立体的体积,然而行列式是反对称的,这就意味着反对称运算跟体积、积分等有着先天的联系。当然,更细致的认识,笔者也还没做到。
此外,我们说寻求微分形式的几何意义,通常只是针对不超过3维的空间来讨论的,更高维的几何图像我们很难想象出来,尤其是高维的曲面积分,一般只是类比,但类比是否成立,有时还需要进一步商榷。因此,这种情况下,倒不如干脆点,说微分形式描述的东西就是几何,而不再去寻找所谓的几何意义了。也就是说,反过来,将微分形式和外微分作为公理式的第一性原理来定义几何。
甚至,你可以只将外微分当作是一种记忆各种微分、积分公式的有效途径,比如现在我要大家默写三维空间中的斯托克斯公式,大家估计会乱,因为不一定记得是哪个减哪个。但是在外微分框架下,可以很快地将它推导一遍。好比式$(11)$,如果非要寻求几何解释,那就是开普勒第二定律:单位时间内扫过的面积相等;然而没有几何解释,你依旧可以把方程解下去。
10
Dec
BiGAN-QP:简单清晰的编码&生成模型
By 苏剑林 | 2018-12-10 | 66636位读者 | 引用前不久笔者通过直接在对偶空间中分析的思路,提出了一个称为GAN-QP的对抗模型框架,它的特点是可以从理论上证明既不会梯度消失,又不需要L约束,使得生成模型的搭建和训练都得到简化。
GAN-QP是一个对抗框架,所以理论上原来所有的GAN任务都可以往上面试试。前面《不用L约束又不会梯度消失的GAN,了解一下?》一文中我们只尝试了标准的随机生成任务,而这篇文章中我们尝试既有生成器、又有编码器的情况:BiGAN-QP。
BiGAN与BiGAN-QP
注意这是BiGAN,不是前段时间很火的BigGAN,BiGAN是双向GAN(Bidirectional GAN),提出于《Adversarial feature learning》一文,同期还有一篇非常相似的文章叫做《Adversarially Learned Inference》,提出了叫做ALI的模型,跟BiGAN差不多。总的来说,它们都是往普通的GAN模型中加入了编码器,使得模型既能够具有普通GAN的随机生成功能,又具有编码器的功能,可以用来提取有效的特征。把GAN-QP这种对抗模式用到BiGAN中,就得到了BiGAN-QP。
话不多说,先来上效果图(左边是原图,右边是重构):

BiGAN-QP重构效果图
20
May
函数光滑化杂谈:不可导函数的可导逼近
By 苏剑林 | 2019-05-20 | 126126位读者 | 引用一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。
还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到$\text{argmax}$等操作),所以没法直接用。
这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案;另外一种是试图给正确率找一个光滑可导的近似公式。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。
max
后面谈到的大部分内容,基础点就是$\max$操作的光滑近似,我们有:
\begin{equation}\max(x_1,x_2,\dots,x_n) = \lim_{K\to +\infty}\frac{1}{K}\log\left(\sum_{i=1}^n e^{K x_i}\right)\end{equation}
28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 195992位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
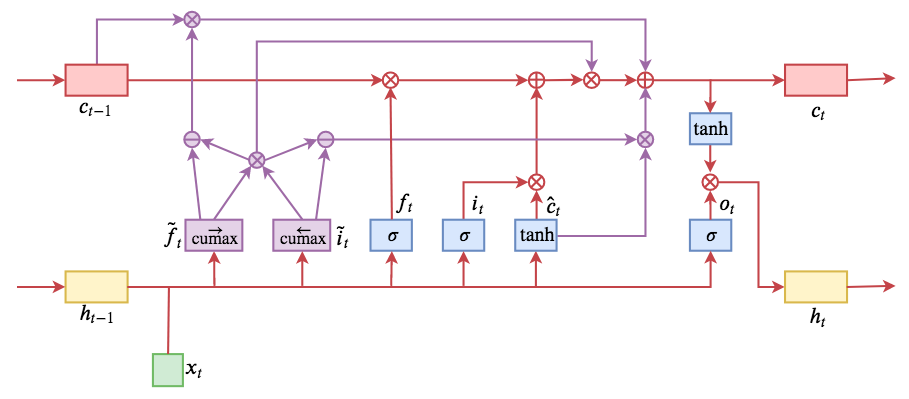
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~

最近评论