






30
Jan
GPLinker:基于GlobalPointer的实体关系联合抽取
By 苏剑林 | 2022-01-30 | 116387位读者 | 引用在将近三年前的百度“2019语言与智能技术竞赛”(下称LIC2019)中,笔者提出了一个新的关系抽取模型(参考《基于DGCNN和概率图的轻量级信息抽取模型》),后被进一步发表和命名为“CasRel”,算是当时关系抽取的SOTA。然而,CasRel提出时笔者其实也是首次接触该领域,所以现在看来CasRel仍有诸多不完善之处,笔者后面也有想过要进一步完善它,但也没想到特别好的设计。
后来,笔者提出了GlobalPointer以及近日的Efficient GlobalPointer,感觉有足够的“材料”来构建新的关系抽取模型了。于是笔者从概率图思想出发,参考了CasRel之后的一些SOTA设计,最终得到了一版类似TPLinker的模型。
基础思路
关系抽取乍看之下是三元组$(s,p,o)$(即subject, predicate, object)的抽取,但落到具体实现上,它实际是“五元组”$(s_h,s_t,p,o_h,o_t)$的抽取,其中$s_h,s_t$分别是$s$的首、尾位置,而$o_h,o_t$则分别是$o$的首、尾位置。
14
Feb
多任务学习漫谈(三):分主次之序
By 苏剑林 | 2022-02-14 | 34652位读者 | 引用多任务学习是一个很宽泛的命题,不同场景下多任务学习的目标不尽相同。在《多任务学习漫谈(一):以损失之名》和《多任务学习漫谈(二):行梯度之事》中,我们将多任务学习的目标理解为“做好每一个任务”,具体表现是“尽量平等地处理每一个任务”,我们可以称之为“平行型多任务学习”。然而,并不是所有多任务学习的目标都是如此,在很多场景下,我们主要还是想学好某一个主任务,其余任务都只是辅助,希望通过增加其他任务的学习来提升主任务的效果罢了,此类场景我们可以称为“主次型多任务学习”。
在这个背景下,如果还是沿用平行型多任务学习的“做好每一个任务”的学习方案,那么就可能会明显降低主任务的效果了。所以本文继续沿着“行梯度之事”的想法,探索主次型多任务学习的训练方案。
目标形式
在这篇文章中,我们假设读者已经阅读并且基本理解《多任务学习漫谈(二):行梯度之事》里边的思想和方法,那么在梯度视角下,让某个损失函数保持下降的必要条件是更新量与其梯度夹角至少大于90度,这是贯穿全文的设计思想。
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 75284位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
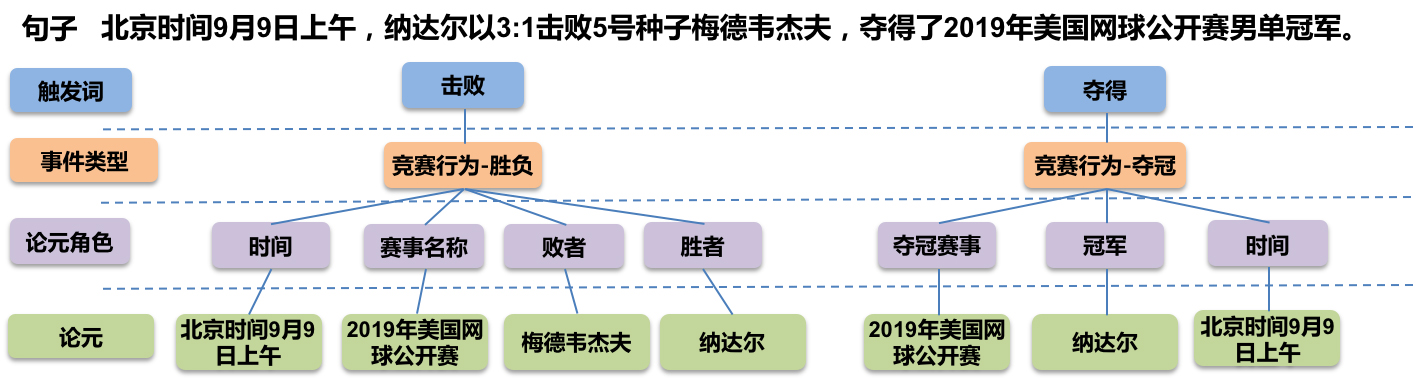
标准的事件抽取样本(图片来自百度DuEE的GitHub)
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 172925位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
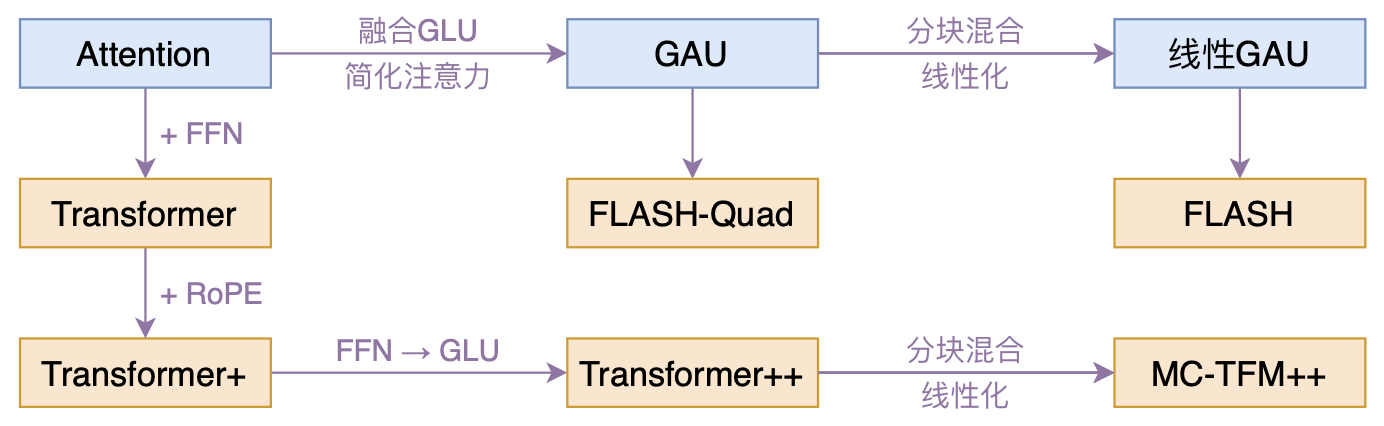
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
28
Apr
在bert4keras中使用混合精度和XLA加速训练
By 苏剑林 | 2022-04-28 | 25732位读者 | 引用之前笔者一直都是聚焦于模型的构思和实现,鲜有关注模型的训练加速,像混合精度和XLA这些技术,虽然也有听过,但没真正去实践过。这两天折腾了一番,成功在bert4keras中使用了混合精度和XLA来加速训练,在此做个简单的总结,供大家参考。
本文的多数经验结论并不只限于bert4keras中使用,之所以在标题中强调bert4keras,只不过bert4keras中的模型实现相对较为规整,因此启动这些加速技巧所要做的修改相对更少。
实验环境
本文的实验显卡为3090,使用的docker镜像为nvcr.io/nvidia/tensorflow:21.09-tf1-py3,其中自带的tensorflow版本为1.15.5。另外,实验所用的bert4keras版本为0.11.3。其他环境也可以参考着弄,要注意有折腾精神,不要指望着无脑调用。
顺便提一下,3090、A100等卡只能用cuda11,而tensorflow官网的1.15版本是不支持cuda11的,如果还想用tensorflow 1.x,那么只能用nvidia亲自维护的nvidia-tensorflow,或者用其构建的docker镜像。用nvidia而不是google维护的tensorflow,除了能让你在最新的显卡用上1.x版本外,还有nvidia专门做的一些额外优化,具体文档可以参考这里。
7
May
多标签“Softmax+交叉熵”的软标签版本
By 苏剑林 | 2022-05-07 | 47160位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
在《将“Softmax+交叉熵”推广到多标签分类问题》中,我们提出了一个用于多标签分类的损失函数:
\begin{equation}\log \left(1 + \sum\limits_{i\in\Omega_{neg}} e^{s_i}\right) + \log \left(1 + \sum\limits_{j\in\Omega_{pos}} e^{-s_j}\right)\label{eq:original}\end{equation}
这个损失函数有着单标签分类中“Softmax+交叉熵”的优点,即便在正负类不平衡的依然能够有效工作。但从这个损失函数的形式我们可以看到,它只适用于“硬标签”,这就意味着label smoothing、mixup等技巧就没法用了。本文则尝试解决这个问题,提出上述损失函数的一个软标签版本。
巧妙联系
多标签分类的经典方案就是转化为多个二分类问题,即每个类别用sigmoid函数$\sigma(x)=1/(1+e^{-x})$激活,然后各自用二分类交叉熵损失。当正负类别极其不平衡时,这种做法的表现通常会比较糟糕,而相比之下损失$\eqref{eq:original}$通常是一个更优的选择。
11
Apr
熵不变性Softmax的一个快速推导
By 苏剑林 | 2022-04-11 | 18119位读者 | 引用在文章《从熵不变性看Attention的Scale操作》中,我们推导了一版具有熵不变性质的注意力机制:
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\kappa \log n}{d}QK^{\top}\right)V\label{eq:a}\end{equation}
可以观察到,它主要是往Softmax里边引入了长度相关的缩放因子$\log n$来实现的。原来的推导比较繁琐,并且做了较多的假设,不利于直观理解,本文为其补充一个相对简明快速的推导。
推导过程
我们可以抛开注意力机制的背景,直接设有$s_1,s_2,\cdots,s_n\in\mathbb{R}$,定义
$$p_i = \frac{e^{\lambda s_i}}{\sum\limits_{i=1}^n e^{\lambda s_i}}$$
18
May
当BERT-whitening引入超参数:总有一款适合你
By 苏剑林 | 2022-05-18 | 37376位读者 | 引用在《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者提出了BERT-whitening,验证了一个线性变换就能媲美当时的SOTA方法BERT-flow。此外,BERT-whitening还可以对句向量进行降维,带来更低的内存占用和更快的检索速度。然而,在《无监督语义相似度哪家强?我们做了个比较全面的评测》中我们也发现,whitening操作并非总能带来提升,有些模型本身就很贴合任务(如经过有监督训练的SimBERT),那么额外的whitening操作往往会降低效果。
为了弥补这个不足,本文提出往BERT-whitening中引入了两个超参数,通过调节这两个超参数,我们几乎可以总是获得“降维不掉点”的结果。换句话说,即便是原来加上whitening后效果会下降的任务,如今也有机会在降维的同时获得相近甚至更好的效果了。
方法概要
目前BERT-whitening的流程是:
\begin{equation}\begin{aligned}
\tilde{\boldsymbol{x}}_i =&\, (\boldsymbol{x}_i - \boldsymbol{\mu})\boldsymbol{U}\boldsymbol{\Lambda}^{-1/2} \\
\boldsymbol{\mu} =&\, \frac{1}{N}\sum\limits_{i=1}^N \boldsymbol{x}_i \\
\boldsymbol{\Sigma} =&\, \frac{1}{N}\sum\limits_{i=1}^N (\boldsymbol{x}_i - \boldsymbol{\mu})^{\top}(\boldsymbol{x}_i - \boldsymbol{\mu}) = \boldsymbol{U}\boldsymbol{\Lambda}\boldsymbol{U}^{\top} \,\,(\text{SVD分解})
\end{aligned}\end{equation}

最近评论