






1
May
以蒸馏的名义:“从去噪自编码器到生成模型”重现江湖
By 苏剑林 | 2024-05-01 | 29795位读者 | 引用今天我们分享一下论文《Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation》,顾名思义,这是一篇探讨如何更快更好地蒸馏扩散模型的新论文。
即便没有做过蒸馏,大家应该也能猜到蒸馏的常规步骤:随机采样大量输入,然后用扩散模型生成相应结果作为输出,用这些输入输出作为训练数据对,来监督训练一个新模型。然而,众所周知作为教师的原始扩散模型通常需要多步(比如1000步)迭代才能生成高质量输出,所以且不论中间训练细节如何,该方案的一个显著缺点是生成训练数据太费时费力。此外,蒸馏之后的学生模型通常或多或少都有效果损失。
有没有方法能一次性解决这两个缺点呢?这就是上述论文试图要解决的问题。
3
Mar
T5 PEGASUS:开源一个中文生成式预训练模型
By 苏剑林 | 2021-03-03 | 170042位读者 | 引用去年在文章《那个屠榜的T5模型,现在可以在中文上玩玩了》中我们介绍了Google的多国语言版T5模型(mT5),并给出了用mT5进行中文文本生成任务的例子。诚然,mT5做中文生成任务也是一个可用的方案,但缺乏完全由中文语料训练出来模型总感觉有点别扭,于是决心要搞一个出来。
经过反复斟酌测试,我们决定以mT5为基础架构和初始权重,先结合中文的特点完善Tokenizer,然后模仿PEGASUS来构建预训练任务,从而训练一版新的T5模型,这就是本文所开源的T5 PEGASUS。

T5 PEGASUS的训练数据示例
11
Jun
SimBERTv2来了!融合检索和生成的RoFormer-Sim模型
By 苏剑林 | 2021-06-11 | 103530位读者 | 引用去年我们放出了SimBERT模型,它算是我们开源的比较成功的模型之一,获得了不少读者的认可。简单来说,SimBERT是一个融生成和检索于一体的模型,可以用来作为句向量的一个比较高的baseline,也可以用来实现相似问句的自动生成,可以作为辅助数据扩增工具使用,这一功能是开创性的。
近段时间,我们以RoFormer为基础模型,对SimBERT相关技术进一步整合和优化,最终发布了升级版的RoFormer-Sim模型。
简介
RoFormer-Sim是SimBERT的升级版,我们也可以通俗地称之为“SimBERTv2”,而SimBERT则默认是指旧版。从外部看,除了基础架构换成了RoFormer外,RoFormer-Sim跟SimBERT没什么明显差别,事实上它们主要的区别在于训练的细节上,我们可以用两个公式进行对比:
\begin{array}{c}
\text{SimBERT} = \text{BERT} + \text{UniLM} + \text{对比学习} \\[5pt]
\text{RoFormer-Sim} = \text{RoFormer} + \text{UniLM} + \text{对比学习} + \text{BART} + \text{蒸馏}\\
\end{array}
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 344540位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 117770位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
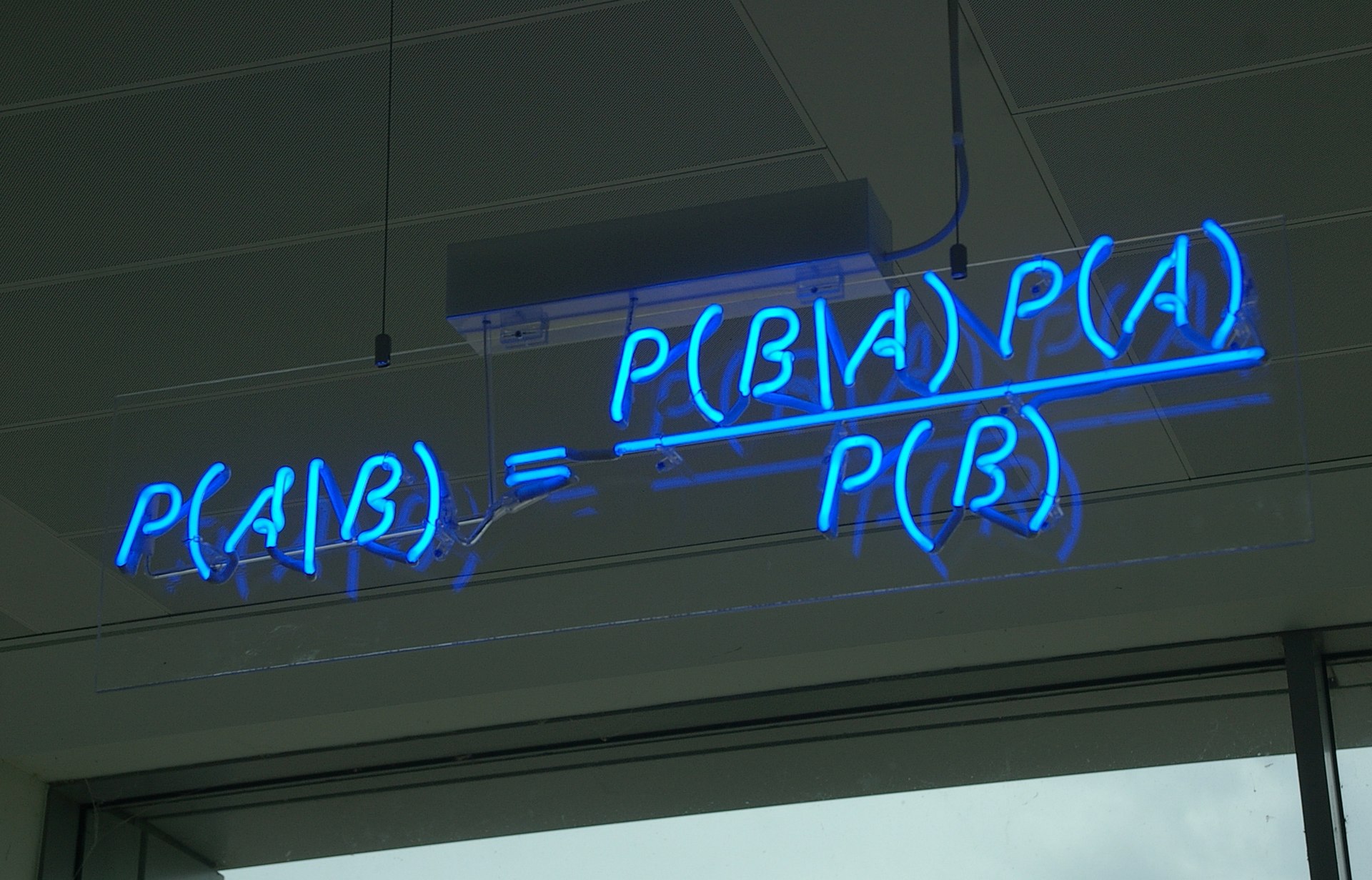
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
6
Jul
生成扩散模型漫谈(二):DDPM = 自回归式VAE
By 苏剑林 | 2022-07-06 | 112301位读者 | 引用在文章《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中,我们为生成扩散模型DDPM构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型DDPM的理论形式。在该文章中,我们还指出DDPM本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器VAE,实际上DDPM的原论文中也是将它按照VAE的思路进行推导的。
所以,本文就从VAE的角度来重新介绍一版DDPM,同时分享一下自己的Keras实现代码和实践经验。
Github地址:https://github.com/bojone/Keras-DDPM
多步突破
在传统的VAE中,编码过程和生成过程都是一步到位的:
\begin{equation}\text{编码:}\,\,x\to z\,,\quad \text{生成:}\,\,z\to x\end{equation}
3
Aug
生成扩散模型漫谈(五):一般框架之SDE篇
By 苏剑林 | 2022-08-03 | 153257位读者 | 引用在写生成扩散模型的第一篇文章时,就有读者在评论区推荐了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,可以说该论文构建了一个相当一般化的生成扩散模型理论框架,将DDPM、SDE、ODE等诸多结果联系了起来。诚然,这是一篇好论文,但并不是一篇适合初学者的论文,里边直接用到了随机微分方程(SDE)、Fokker-Planck方程、得分匹配等大量结果,上手难度还是颇大的。
不过,在经过了前四篇文章的积累后,现在我们可以尝试去学习一下这篇论文了。在接下来的文章中,笔者将尝试从尽可能少的理论基础出发,尽量复现原论文中的推导结果。
随机微分
在DDPM中,扩散过程被划分为了固定的$T$步,还是用《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》的类比来说,就是“拆楼”和“建楼”都被事先划分为了$T$步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。
30
Aug
生成扩散模型漫谈(九):条件控制生成结果
By 苏剑林 | 2022-08-30 | 117452位读者 | 引用前面的几篇文章都是比较偏理论的结果,这篇文章我们来讨论一个比较有实用价值的主题——条件控制生成。
作为生成模型,扩散模型跟VAE、GAN、flow等模型的发展史很相似,都是先出来了无条件生成,然后有条件生成就紧接而来。无条件生成往往是为了探索效果上限,而有条件生成则更多是应用层面的内容,因为它可以实现根据我们的意愿来控制输出结果。从DDPM至今,已经出来了很多条件扩散模型的工作,甚至可以说真正带火了扩散模型的就是条件扩散模型,比如脍炙人口的文生图模型DALL·E 2、Imagen。
在这篇文章中,我们对条件扩散模型的理论基础做个简单的学习和总结。
技术分析
从方法上来看,条件控制生成的方式分两种:事后修改(Classifier-Guidance)和事前训练(Classifier-Free)。

最近评论