






27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 155915位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
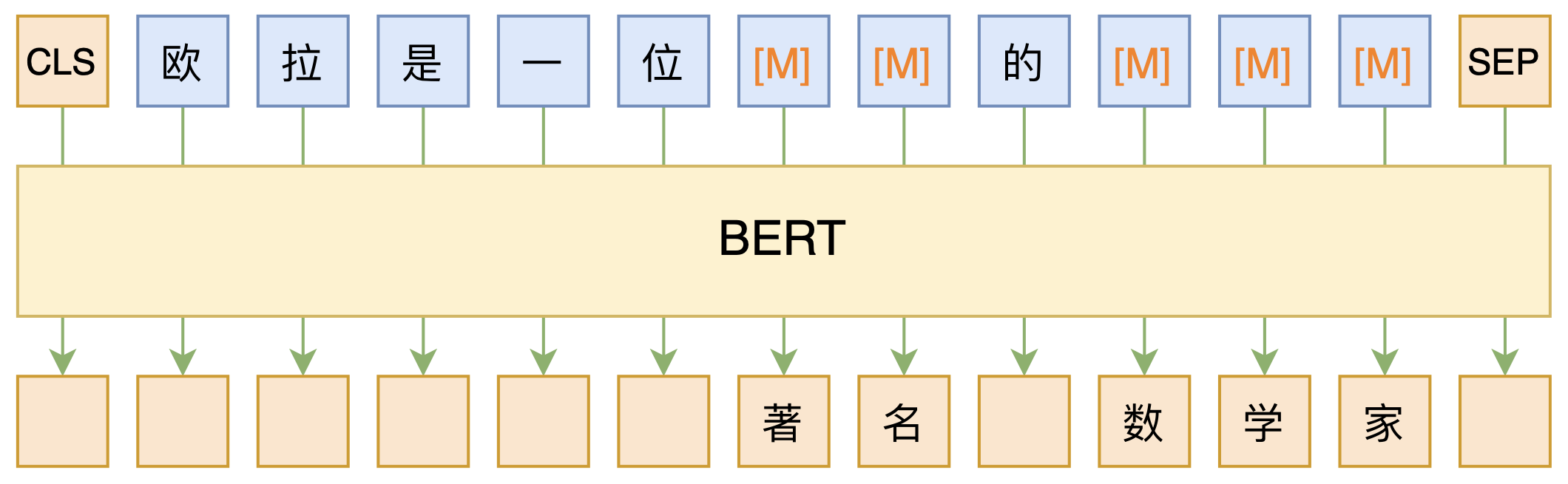
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
10
Oct
从动力学角度看优化算法(五):为什么学习率不宜过小?
By 苏剑林 | 2020-10-10 | 56721位读者 | 引用本文的主题是“为什么我们需要有限的学习率”,所谓“有限”,指的是不大也不小,适中即可,太大容易导致算法发散,这不难理解,但为什么太小也不好呢?一个容易理解的答案是,学习率过小需要迭代的步数过多,这是一种没有必要的浪费,因此从“节能”和“加速”的角度来看,我们不用过小的学习率。但如果不考虑算力和时间,那么过小的学习率是否可取呢?Google最近发布在Arxiv上的论文《Implicit Gradient Regularization》试图回答了这个问题,它指出有限的学习率隐式地给优化过程带来了梯度惩罚项,而这个梯度惩罚项对于提高泛化性能是有帮助的,因此哪怕不考虑算力和时间等因素,也不应该用过小的学习率。
对于梯度惩罚,本博客已有过多次讨论,在文章《对抗训练浅谈:意义、方法和思考(附Keras实现)》和《泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练》中,我们就分析了对抗训练一定程度上等价于对输入的梯度惩罚,而文章《我们真的需要把训练集的损失降低到零吗?》介绍的Flooding技巧则相当于对参数的梯度惩罚。总的来说,不管是对输入还是对参数的梯度惩罚,都对提高泛化能力有一定帮助。
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 70430位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。
6
Nov
那个屠榜的T5模型,现在可以在中文上玩玩了
By 苏剑林 | 2020-11-06 | 134006位读者 | 引用不知道大家对Google去年的屠榜之作T5还有没有印象?就是那个打着“万事皆可Seq2Seq”的旗号、最大搞了110亿参数、一举刷新了GLUE、SuperGLUE等多个NLP榜单的模型,而且过去一年了,T5仍然是SuperGLUE榜单上的第一,目前还稳妥地拉开着第二名2%的差距。然而,对于中文界的朋友来说,T5可能没有什么存在感,原因很简单:没有中文版T5可用。不过这个现状要改变了,因为Google最近放出了多国语言版的T5(mT5),里边当然是包含了中文语言。虽然不是纯正的中文版,但也能凑合着用一下。

“万事皆可Seq2Seq”的T5
本文将会对T5模型做一个简单的回顾与介绍,然后再介绍一下如何在bert4keras中调用mT5模型来做中文任务。作为一个原生的Seq2Seq预训练模型,mT5在文本生成任务上的表现还是相当不错的,非常值得一试。
11
Nov
当GPT遇上中国象棋:写过文章解过题,要不再来下盘棋?
By 苏剑林 | 2020-11-11 | 55788位读者 | 引用
中国象棋
不知道读者有没有看过量子位年初的文章《最强写作AI竟然学会象棋和作曲,语言模型跨界操作引热议,在线求战》,里边提到有网友用GPT2模型训练了一个下国际象棋的模型。笔者一直在想,这么有趣的事情怎么可以没有中文版呢?对于国际象棋来说,其中文版自然就是中国象棋了,于是我一直有想着把它的结果在中国象棋上面复现一下。拖了大半年,在最近几天终于把这个事情完成了,在此跟大家分享一下。
象棋谱式
将军不离九宫内,士止相随不出官。
象飞四方营四角,马行一步一尖冲。
炮须隔子打一子,车行直路任西东。
唯卒只能行一步,过河横进退无踪。
1
Dec
Performer:用随机投影将Attention的复杂度线性化
By 苏剑林 | 2020-12-01 | 85269位读者 | 引用Attention机制的$\mathcal{O}(n^2)$复杂度是一个老大难问题了,改变这一复杂度的思路主要有两种:一是走稀疏化的思路,比如我们以往介绍过的Sparse Attention以及Google前几个月搞出来的Big Bird,等等;二是走线性化的思路,这部分工作我们之前总结在《线性Attention的探索:Attention必须有个Softmax吗?》中,读者可以翻看一下。本文则介绍一项新的改进工作Performer,出自Google的文章《Rethinking Attention with Performers》,它的目标相当霸气:通过随机投影,在不损失精度的情况下,将Attention的复杂度线性化。
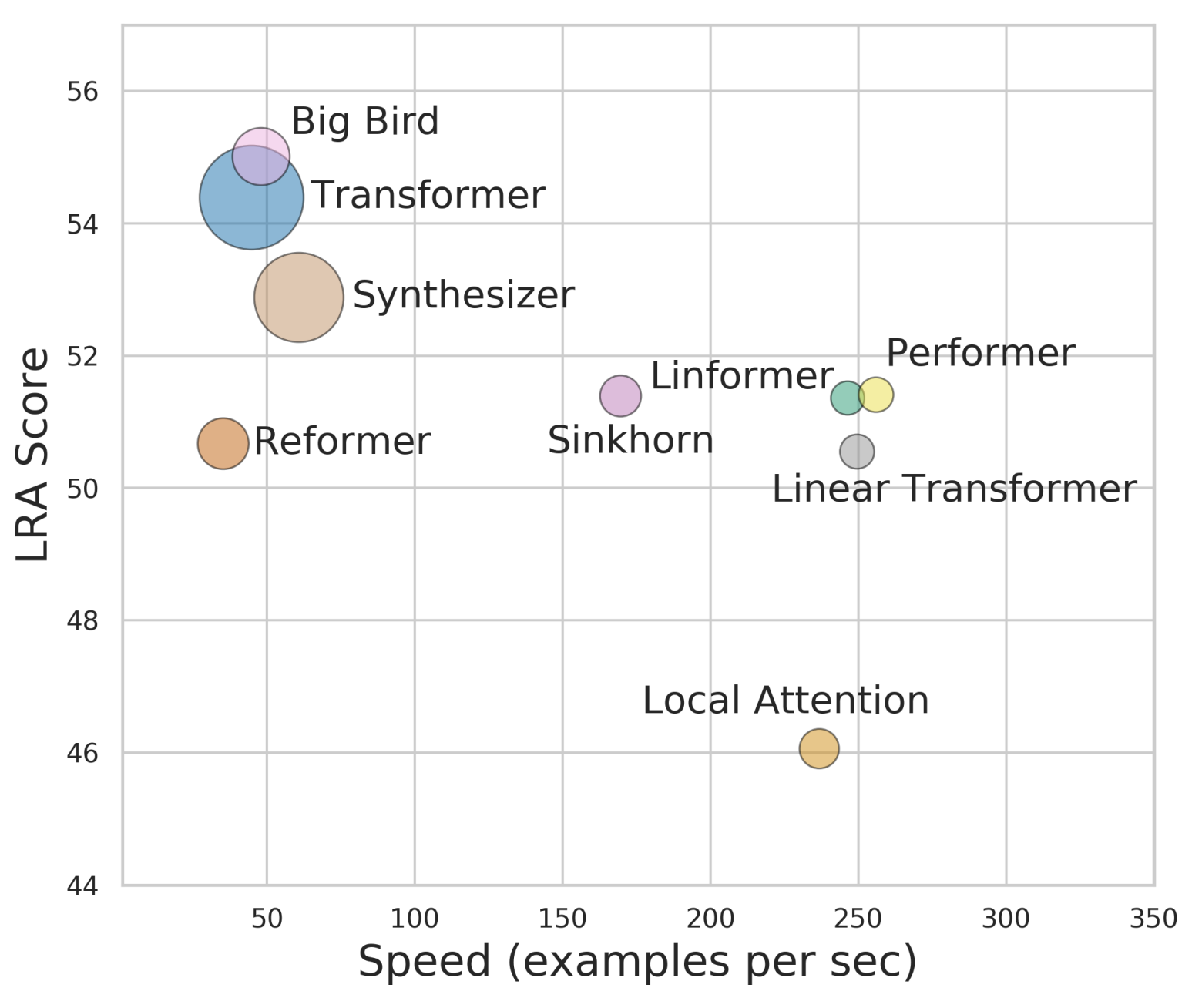
各个Transformer模型的“效果-速度-显存”图,纵轴是效果,横轴是速度,圆圈的大小代表所需要的显存。理论上来说,越靠近右上方的模型越好,圆圈越小的模型越好
说直接点,就是理想情况下我们可以不用重新训练模型,输出结果也不会有明显变化,但是复杂度降到了$\mathcal{O}(n)$!看起来真的是“天上掉馅饼”般的改进了,真的有这么美好吗?
7
Dec
【龟鱼记】全陶粒的同程底滤生态缸
By 苏剑林 | 2020-12-07 | 59644位读者 | 引用
1
Jan
SPACES:“抽取-生成”式长文本摘要(法研杯总结)
By 苏剑林 | 2021-01-01 | 245951位读者 | 引用“法研杯”算是近年来比较知名的NLP赛事之一,今年是第三届,包含四个赛道,其中有一个“司法摘要”赛道引起了我们的兴趣。经过了解,这是面向法律领域裁判文书的长文本摘要生成,这应该是国内第一个公开的长文本生成任务和数据集。过去一年多以来,我们在文本生成方面都有持续的投入和探索,所以决定选择该赛道作为检验我们研究成果的“试金石”。很幸运,我们最终以微弱的优势获得了该赛道的第一名。在此,我们对我们的比赛模型做一个总结和分享。

比赛榜单截图
在该比赛中,我们跳出了纯粹炼丹的过程,通过新型的Copy机制、Sparse Softmax等颇具通用性的新方法提升了模型的性能。整体而言,我们的模型比较简洁有效,而且可以做到端到端运行。窃以为我们的结果对工程和研究都有一定的参考价值。

最近评论