






9
Sep
重新写了之前的新词发现算法:更快更好的新词发现
By 苏剑林 | 2019-09-09 | 107960位读者 | 引用新词发现是NLP的基础任务之一,主要是希望通过无监督发掘一些语言特征(主要是统计特征),来判断一批语料中哪些字符片段可能是一个新词。本站也多次围绕“新词发现”这个话题写过文章,比如:
在这些文章之中,笔者觉得理论最漂亮的是《基于语言模型的无监督分词》,而作为新词发现算法来说综合性能比较好的应该是《更好的新词发现算法》,本文就是复现这篇文章的新词发现算法。
29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 89329位读者 | 引用
2
Apr
bert4keras在手,baseline我有:百度LIC2020
By 苏剑林 | 2020-04-02 | 104886位读者 | 引用百度的“2020语言与智能技术竞赛”开赛了,今年有五个赛道,分别是机器阅读理解、推荐任务对话、语义解析、关系抽取、事件抽取。每个赛道中,主办方都给出了基于PaddlePaddle的baseline模型,这里笔者也基于bert4keras给出其中三个赛道的个人baseline,从中我们可以看到用bert4keras搭建baseline模型的方便快捷与简练。
思路简析
这里简单分析一下这三个赛道的任务特点以及对应的baseline设计。
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 105798位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
5
Jun
为什么梯度裁剪能加速训练过程?一个简明的分析
By 苏剑林 | 2020-06-05 | 35836位读者 | 引用本文介绍来自MIT的一篇ICLR 2020满分论文《Why gradient clipping accelerates training: A theoretical justification for adaptivity》,顾名思义,这篇论文就是分析为什么梯度裁剪能加速深度学习的训练过程。原文很长,公式很多,还有不少研究复杂性的概念,说实话对笔者来说里边的大部分内容也是懵的,不过大概能捕捉到它的核心思想:引入了比常用的L约束更宽松的约束条件,从新的条件出发论证了梯度裁剪的必要性。本文就是来简明分析一下这个过程,供读者参考。
梯度裁剪
假设需要最小化的函数为f(θ),θ就是优化参数,那么梯度下降的更新公式就是
θ←θ−η∇θf(θ)
其中η就是学习率。而所谓梯度裁剪(gradient clipping),就是根据梯度的模长来对更新量做一个缩放,比如
θ←θ−η∇θf(θ)×min
或者
\begin{equation}\theta \leftarrow \theta- \eta \nabla_{\theta} f(\theta)\times \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert+\gamma}\label{eq:clip-2}\end{equation}
其中\gamma > 0是一个常数。这两种方式都被视为梯度裁剪,总的来说就是控制更新量的模长不超过一个常数,第二种形式也跟RMSProp等自适应学习率优化器相关。此外,更精确地,我们有下面的不等式
\begin{equation}\frac{1}{2}\min\left\{1, \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert}\right\}\leq \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert+\gamma}\leq \min\left\{1, \frac{\gamma}{\Vert \nabla_{\theta} f(\theta)\Vert}\right\}\end{equation}
也就是说两者是可以相互控制的,所以其实两者基本是等价的。
7
Sep
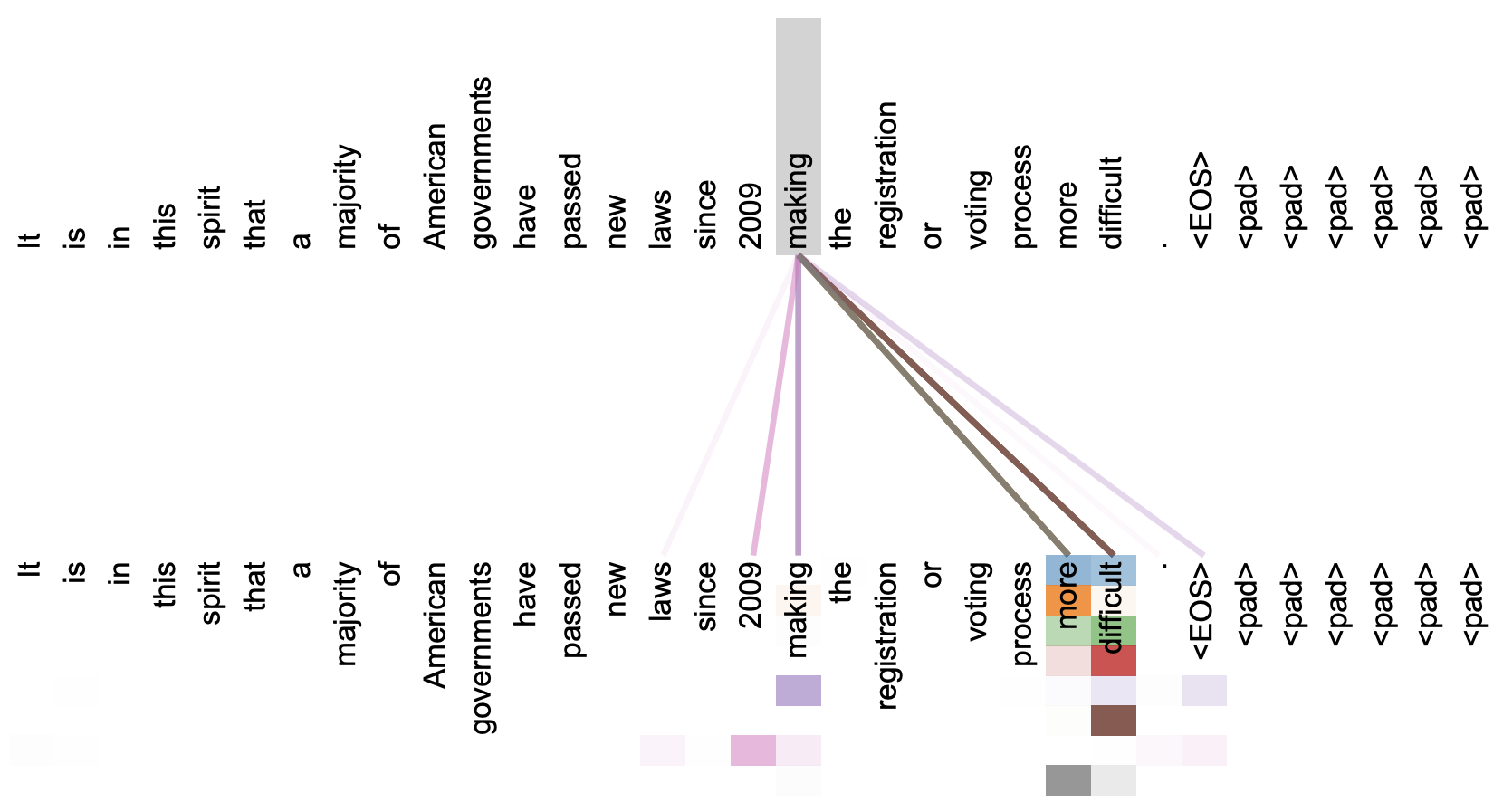
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 122357位读者 | 引用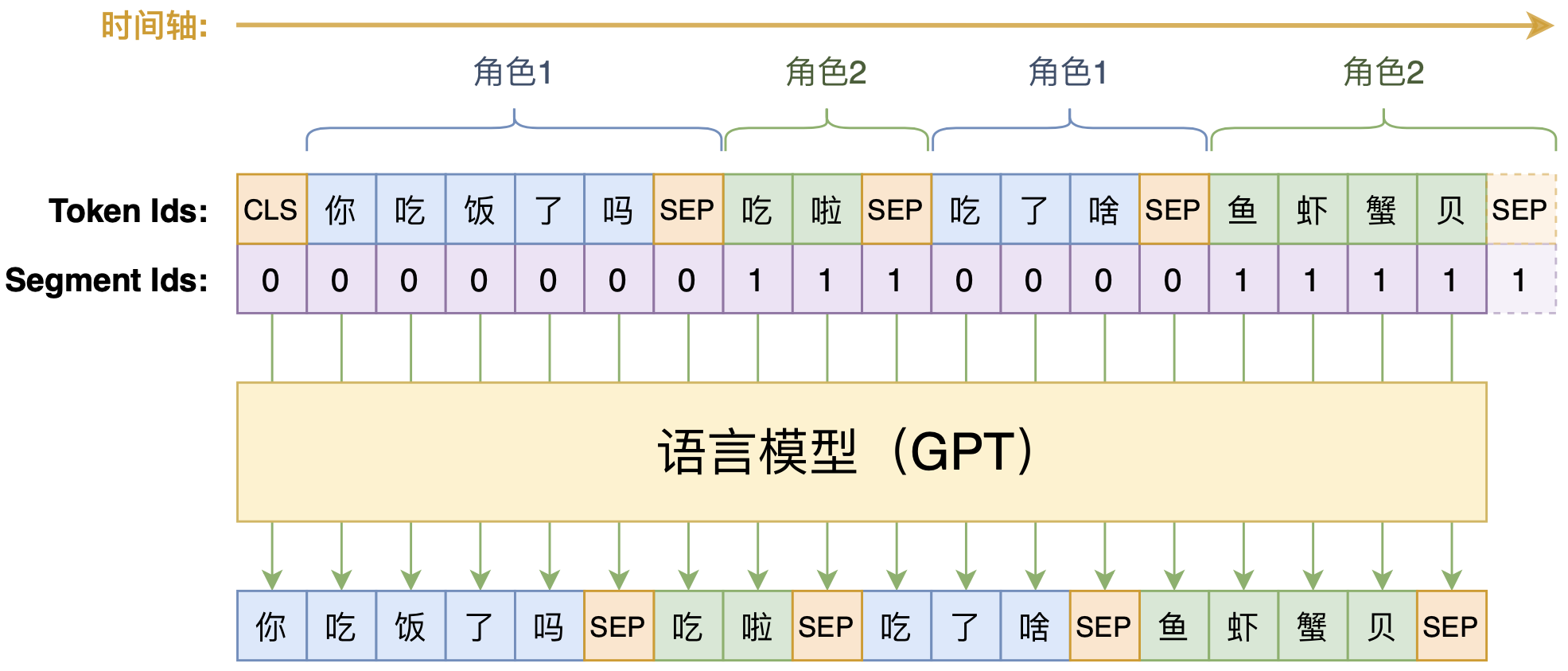
25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 136423位读者 | 引用机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
本文的问答生成模型示意图
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 76958位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。

最近评论