






15
Jul
漫话模型|模型与选芒果
By 苏剑林 | 2015-07-15 | 38729位读者 | 引用很多人觉得“模型”、“大数据”、“机器学习”这些字眼很高大很神秘,事实上,它跟我们生活中选水果差不了多少。本文用了几千字,来试图教会大家怎么选芒果...
模型的比喻

芒果
假如我要从一批芒果中,找出好吃的那个来。而我不能直接切开芒果尝尝,所以我只能观察芒果,能观察到的量有颜色、表面的气味、大小等等,这些就是我们能够收集到的信息(特征)。
生活中还要很多这样的例子,比如买火柴(可能年轻的城里人还没见过火柴?),如何判断一盒火柴的质量?难道要每根火柴都划划,看看着不着火?显然不行,我们最多也只能划几根,全部划了,火柴也不成火柴了。当然,我们还能看看火柴的样子,闻闻火柴的气味,这些动作是可以接受的。
3
Jan
用bert4keras做三元组抽取
By 苏剑林 | 2020-01-03 | 260174位读者 | 引用在开发bert4keras的时候就承诺过,会逐渐将之前用keras-bert实现的例子逐渐迁移到bert4keras来,而那里其中一个例子便是三元组抽取的任务。现在bert4keras的例子已经颇为丰富了,但还没有序列标注和信息抽取相关的任务,而三元组抽取正好是这样的一个任务,因此就补充上去了。
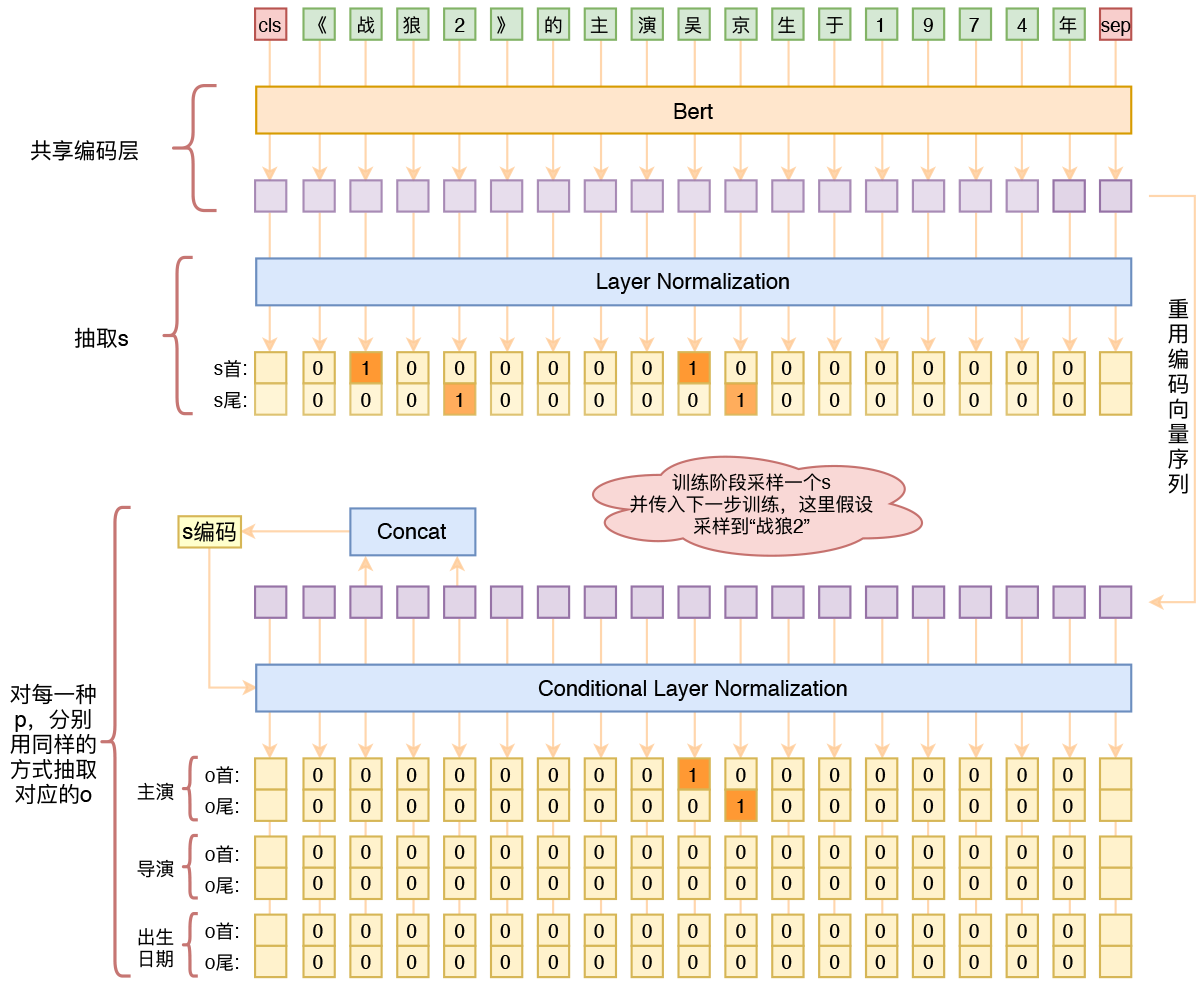
基于Bert的三元组抽取模型结构示意图
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 428583位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
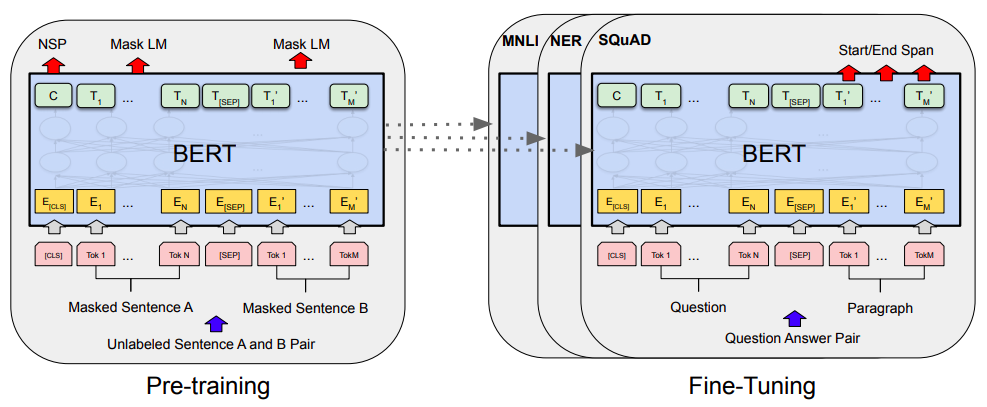
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
2
Apr
bert4keras在手,baseline我有:百度LIC2020
By 苏剑林 | 2020-04-02 | 94954位读者 | 引用百度的“2020语言与智能技术竞赛”开赛了,今年有五个赛道,分别是机器阅读理解、推荐任务对话、语义解析、关系抽取、事件抽取。每个赛道中,主办方都给出了基于PaddlePaddle的baseline模型,这里笔者也基于bert4keras给出其中三个赛道的个人baseline,从中我们可以看到用bert4keras搭建baseline模型的方便快捷与简练。
思路简析
这里简单分析一下这三个赛道的任务特点以及对应的baseline设计。
1
May
生成扩散模型漫谈(二十五):基于恒等式的蒸馏(上)
By 苏剑林 | 2024-05-01 | 50902位读者 | 引用今天我们分享一下论文《Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation》,顾名思义,这是一篇探讨如何更快更好地蒸馏扩散模型的新论文。
即便没有做过蒸馏,大家应该也能猜到蒸馏的常规步骤:随机采样大量输入,然后用扩散模型生成相应结果作为输出,用这些输入输出作为训练数据对,来监督训练一个新模型。然而,众所周知作为教师的原始扩散模型通常需要多步(比如1000步)迭代才能生成高质量输出,所以且不论中间训练细节如何,该方案的一个显著缺点是生成训练数据太费时费力。此外,蒸馏之后的学生模型通常或多或少都有效果损失。
有没有方法能一次性解决这两个缺点呢?这就是上述论文试图要解决的问题。
22
Jul
初试在Python中使用PARI/GP
By 苏剑林 | 2014-07-22 | 31073位读者 | 引用
26
Aug
fashion-mnist的gan玩具
By 苏剑林 | 2017-08-26 | 59633位读者 | 引用
fashion_mnist_demo
mnist的手写数字识别数据集一直是各种机器学习算法的试金石之一,最近有个新的数据集要向它叫板,称为fashion-mnist,内容是衣服鞋帽等分类。为了便于用户往fashion-mnist迁移,作者把数据集做成了几乎跟mnist手写数字识别数据集一模一样——同样数量、尺寸的图片,同样是10分类,甚至连数据打包和命名都跟mnist一样。看来fashion mnist为了取代mnist,也是拼了,下足了功夫,一切都做得一模一样,最大限度降低了使用成本~这叫板的心很坚定呀。
叫板的原因很简单——很多人吐槽,如果一个算法在mnist没用,那就一定没用了,但如果一个算法在mnist上有效,那它也不见得在真实问题中有效~也就是说,这个数据集太简单,没啥代表性。
fashion-mnist的github:https://github.com/zalandoresearch/fashion-mnist/
17
Jun
OCR技术浅探:1. 全文简述
By 苏剑林 | 2016-06-17 | 45037位读者 | 引用写在前面:前面的博文已经提过,在上个月我参加了第四届泰迪杯数据挖掘竞赛,做的是A题,跟OCR系统有些联系,还承诺过会把最终的结果开源。最近忙于毕业、搬东西,一直没空整理这些内容,现在抽空整理一下。
把结果发出来,并不是因为结果有多厉害、多先进(相反,当我对比了百度的这篇论文《基于深度学习的图像识别进展:百度的若干实践》之后,才发现论文的内容本质上还是传统那一套,远远还跟不上时代的潮流),而是因为虽然OCR技术可以说比较成熟了,但网络上根本就没有对OCR系统进行较为详细讲解的文章,而本文就权当补充这部分内容吧。我一直认为,技术应该要开源才能得到发展(当然,在中国这一点也确实值得商榷,因为开源很容易造成山寨),不管是数学物理研究还是数据挖掘,我大多数都会发表到博客中,与大家交流。

最近评论