






20
Sep
10月国际空间站过境时间
By 苏剑林 | 2009-09-20 | 23311位读者 | 引用
31
Dec
写在2009年终结之际...
By 苏剑林 | 2009-12-31 | 16307位读者 | 引用
logo_iya2009
今天是2009年的最后一天了,再过4个小时,就要用上新的日历,写上新的一年了。
回过头来,才发现,其实我这一年里收获了很多,懂得了很多,成熟了很多...当然,也有犯了不少的错误。
这一年,我经历了许许多多的第一次:第一次外出、第一次...本来想详细列出一个“年终总结”来的,不过想了想,还是不要了。留在心底慢慢品味,慢慢懂得,慢慢长大...
感谢所有的人——包括亲人、朋友、老师,以及一切和我相关的人。不论是朋友,还是敌人;是伙伴,还是对手,他们都是我所需要的人。因为有他们,我的生活才能够更加有声有色!
7
Nov
人不能忘本|我的数学竞赛题
By 苏剑林 | 2009-11-07 | 43326位读者 | 引用
21
Mar
地球“黑暗”的一小时
By 苏剑林 | 2010-03-21 | 30082位读者 | 引用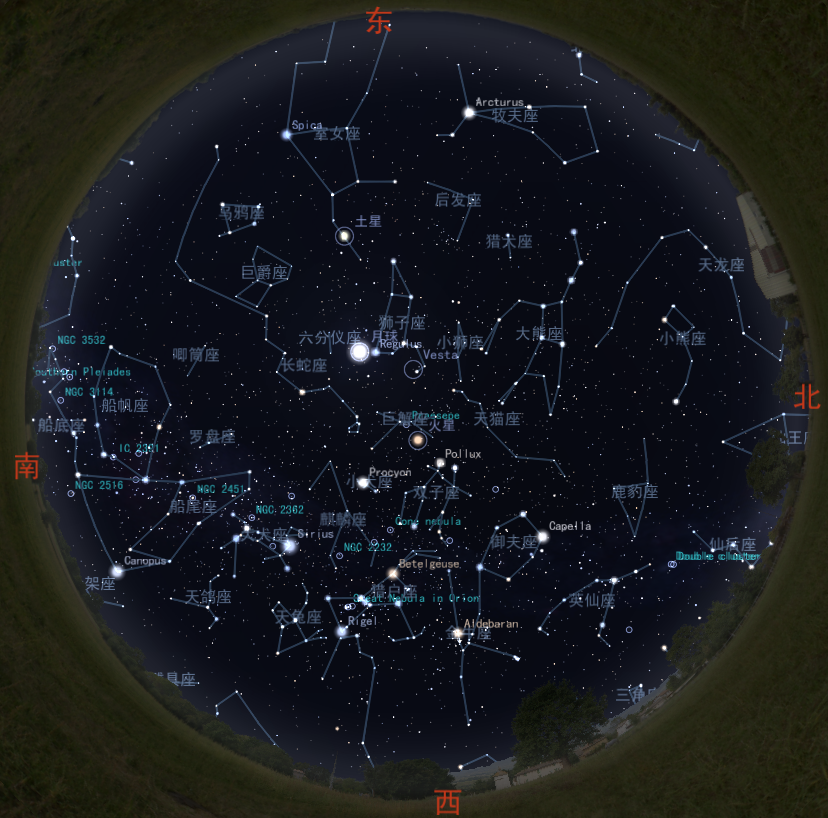
6
Feb
直上云霄的无穷指数方程
By 苏剑林 | 2010-02-06 | 32719位读者 | 引用
5
Aug
日出东方,重逢,最美的风采
By 苏剑林 | 2010-08-05 | 22458位读者 | 引用历时三年,经过三届评选,《日出东方》、《重逢》和《最美的风采》入围亚运会会歌候选歌曲。就BoJone而言,比较喜欢的事《日出东方》。最终结果如何?让我们拭目以待!
日出东方,我们在广州重逢,展示最美的风采!
其中,《日出东方》的作曲是知名曲作家李海鹰,作词是朱海。歌曲名字与广州亚运标识五羊上方绚丽的太阳形象完全契合,体现了克服困难取得胜利的体育精神,同时也有亚运火炬薪火相传、永不熄灭的含义。《重逢》的作曲是捞仔,作词是徐荣凯。歌曲取名重逢,突出了亚运会不仅是亚洲的运动盛会,也是亚洲兄弟姐妹四年一次的盛大友谊聚会,亚洲虽然辽阔,但亚洲人民之间的深厚友谊缩短了彼此的距离。《最美的风采》则是由香港著名作曲家金培达作曲,广州知名音乐人陈小奇作词。歌曲将“花海”与“运动会”的意象巧妙地融为一体,彰显出广州作为“花城”及亚运会主办城市所具有的风采,及“和谐亚洲,激情盛会”的主题。

最近评论