






6
Mar
【中文分词系列】 7. 深度学习分词?只需一个词典!
By 苏剑林 | 2017-03-06 | 113720位读者 | 引用这个系列慢慢写到第7篇,基本上也把分词的各种模型理清楚了,除了一些细微的调整(比如最后的分类器换成CRF)外,剩下的就看怎么玩了。基本上来说,要速度,就用基于词典的分词,要较好地解决组合歧义何和新词识别,则用复杂模型,比如之前介绍的LSTM、FCN都可以。但问题是,用深度学习训练分词器,需要标注语料,这费时费力,仅有的公开的几个标注语料,又不可能赶得上时效,比如,几乎没有哪几个公开的分词系统能够正确切分出“扫描二维码,关注微信号”来。
本文就是做了这样的一个实验,仅用一个词典,就完成了一个深度学习分词器的训练,居然效果还不错!这种方案可以称得上是半监督的,甚至是无监督的。
18
Apr
最小熵原理(一):无监督学习的原理
By 苏剑林 | 2018-04-18 | 83819位读者 | 引用话在开头
在深度学习等端到端方案已经逐步席卷NLP的今天,你是否还愿意去思考自然语言背后的基本原理?我们常说“文本挖掘”,你真的感受到了“挖掘”的味道了吗?
无意中的邂逅
前段时间看了一篇关于无监督句法分析的文章,继而从它的参考文献中发现了论文《Redundancy Reduction as a Strategy for Unsupervised Learning》,这篇论文介绍了如何从去掉空格的英文文章中将英文单词复原。对应到中文,这不就是词库构建吗?于是饶有兴致地细读了一番,发现论文思路清晰、理论完整、结果漂亮,让人赏心悦目。
尽管现在看来,这篇论文的价值不是很大,甚至其结果可能已经被很多人学习过了,但是要注意:这是一篇1993年的论文!在PC机还没有流行的年代,就做出了如此前瞻性的研究。虽然如今深度学习流行,NLP任务越做越复杂,这确实是一大进步,但是我们对NLP原理的真正了解,还不一定超过几十年前的前辈们多少。
这篇论文是通过“去冗余”(Redundancy Reduction)来实现无监督地构建词库的,从信息论的角度来看,“去冗余”就是信息熵的最小化。无监督句法分析那篇文章也指出“信息熵最小化是无监督的NLP的唯一可行的方案”。我进而学习了一些相关资料,并且结合自己的理解思考了一番,发现这个评论确实是耐人寻味。我觉得,不仅仅是NLP,信息熵最小化很可能是所有无监督学习的根本。
2
Oct
深度学习的互信息:无监督提取特征
By 苏剑林 | 2018-10-02 | 267851位读者 | 引用
随机采样的KNN样本
对于NLP来说,互信息是一个非常重要的指标,它衡量了两个东西的本质相关性。本博客中也多次讨论过互信息,而我也对各种利用互信息的文章颇感兴趣。前几天在机器之心上看到了最近提出来的Deep INFOMAX模型,用最大化互信息来对图像做无监督学习,自然也颇感兴趣,研读了一番,就得到了本文。
本文整体思路源于Deep INFOMAX的原始论文,但并没有照搬原始模型,而是按照这自己的想法改动了模型(主要是先验分布部分),并且会在相应的位置进行注明。
我们要做什么
自编码器
特征提取是无监督学习中很重要且很基本的一项任务,常见形式是训练一个编码器将原始数据集编码为一个固定长度的向量。自然地,我们对这个编码器的基本要求是:保留原始数据的(尽可能多的)重要信息。
我们怎么知道编码向量保留了重要信息呢?一个很自然的想法是这个编码向量应该也要能还原出原始图片出来,所以我们还训练一个解码器,试图重构原图片,最后的loss就是原始图片和重构图片的mse。这导致了标准的自编码器的设计。后来,我们还希望编码向量的分布尽量能接近高斯分布,这就导致了变分自编码器。
重构的思考
20
Dec
从动力学角度看优化算法(二):自适应学习率算法
By 苏剑林 | 2018-12-20 | 46133位读者 | 引用在《从动力学角度看优化算法(一):从SGD到动量加速》一文中,我们提出SGD优化算法跟常微分方程(ODE)的数值解法其实是对应的,由此还可以很自然地分析SGD算法的收敛性质、动量加速的原理等等内容。
在这篇文章中,我们继续沿着这个思路,去理解优化算法中的自适应学习率算法。
RMSprop
首先,我们看一个非常经典的自适应学习率优化算法:RMSprop。RMSprop虽然不是最早提出的自适应学习率的优化算法,但是它却是相当实用的一种,它是诸如Adam这样的更综合的算法的基石,通过它我们可以观察自适应学习率的优化算法是怎么做的。
算法概览
一般的梯度下降是这样的:
$$\begin{equation}\boldsymbol{\theta}_{n+1}=\boldsymbol{\theta}_{n} - \gamma \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\end{equation}$$
很明显,这里的$\gamma$是一个超参数,便是学习率,它可能需要在不同阶段做不同的调整。
而RMSprop则是
$$\begin{equation}\begin{aligned}\boldsymbol{g}_{n+1} =& \nabla_{\boldsymbol{\theta}} L(\boldsymbol{\theta}_{n})\\
\boldsymbol{G}_{n+1}=&\lambda \boldsymbol{G}_{n} + (1 - \lambda) \boldsymbol{g}_{n+1}\otimes \boldsymbol{g}_{n+1}\\
\boldsymbol{\theta}_{n+1}=&\boldsymbol{\theta}_{n} - \frac{\tilde{\gamma}}{\sqrt{\boldsymbol{G}_{n+1} + \epsilon}}\otimes \boldsymbol{g}_{n+1}
\end{aligned}\end{equation}$$
7
Oct
深度学习中的Lipschitz约束:泛化与生成模型
By 苏剑林 | 2018-10-07 | 147217位读者 | 引用前言:去年写过一篇WGAN-GP的入门读物《互怼的艺术:从零直达WGAN-GP》,提到通过梯度惩罚来为WGAN的判别器增加Lipschitz约束(下面简称“L约束”)。前几天遐想时再次想到了WGAN,总觉得WGAN的梯度惩罚不够优雅,后来也听说WGAN在条件生成时很难搞(因为不同类的随机插值就开始乱了...),所以就想琢磨一下能不能搞出个新的方案来给判别器增加L约束。
闭门造车想了几天,然后发现想出来的东西别人都已经做了,果然是只有你想不到,没有别人做不到。主要包含在这两篇论文中:《Spectral Norm Regularization for Improving the Generalizability of Deep Learning》和《Spectral Normalization for Generative Adversarial Networks》。
所以这篇文章就按照自己的理解思路,对L约束相关的内容进行简单的介绍。注意本文的主题是L约束,并不只是WGAN。它可以用在生成模型中,也可以用在一般的监督学习中。
L约束与泛化
扰动敏感
记输入为$x$,输出为$y$,模型为$f$,模型参数为$w$,记为
$$\begin{equation}y = f_w(x)\end{equation}$$
很多时候,我们希望得到一个“稳健”的模型。何为稳健?一般来说有两种含义,一是对于参数扰动的稳定性,比如模型变成了$f_{w+\Delta w}(x)$后是否还能达到相近的效果?如果在动力学系统中,还要考虑模型最终是否能恢复到$f_w(x)$;二是对于输入扰动的稳定性,比如输入从$x$变成了$x+\Delta x$后,$f_w(x+\Delta x)$是否能给出相近的预测结果。读者或许已经听说过深度学习模型存在“对抗攻击样本”,比如图片只改变一个像素就给出完全不一样的分类结果,这就是模型对输入过于敏感的案例。
26
Dec
【学习清单】最近比较重要的GAN进展论文
By 苏剑林 | 2018-12-26 | 63819位读者 | 引用这篇文章简单列举一下我认为最近这段时间中比较重要的GAN进展论文,这基本也是我在学习GAN的过程中主要去研究的论文清单。
生成模型之味
GAN是一个大坑,尤其像我这样的业余玩家,一头扎进去很久也很难有什么产出,尤其是各个大公司拼算力搞出来一个个大模型,个人几乎都没法玩了。但我总觉得,真的去碰了生成模型,才觉得自己碰到了真正的机器学习。这一点,不管在图像中还是文本中都是如此。所以,我还是愿意去关注生成模型。
当然,GAN不是生成模型的唯一选择,却是一个非常有趣的选择。在图像中至少有GAN、flow、pixelrnn/pixelcnn这几种选择,但要说潜力,我还是觉得GAN才是最具前景的,不单是因为效果,主要是因为它那对抗的思想。而在文本中,事实上seq2seq机制就是一个概率生成模型了,而pixelrnn这类模型,实际上就是模仿着seq2seq来做的,当然也有用GAN做文本生成的研究(不过基本上都涉及到了强化学习)。也就是说,其实在NLP中,生成模型也有很多成果,哪怕你主要是研究NLP的,也终将碰到生成模型。
好了,话不多说,还是赶紧把清单列一列,供大家参考,也作为自己的备忘。
10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 97392位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 146875位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
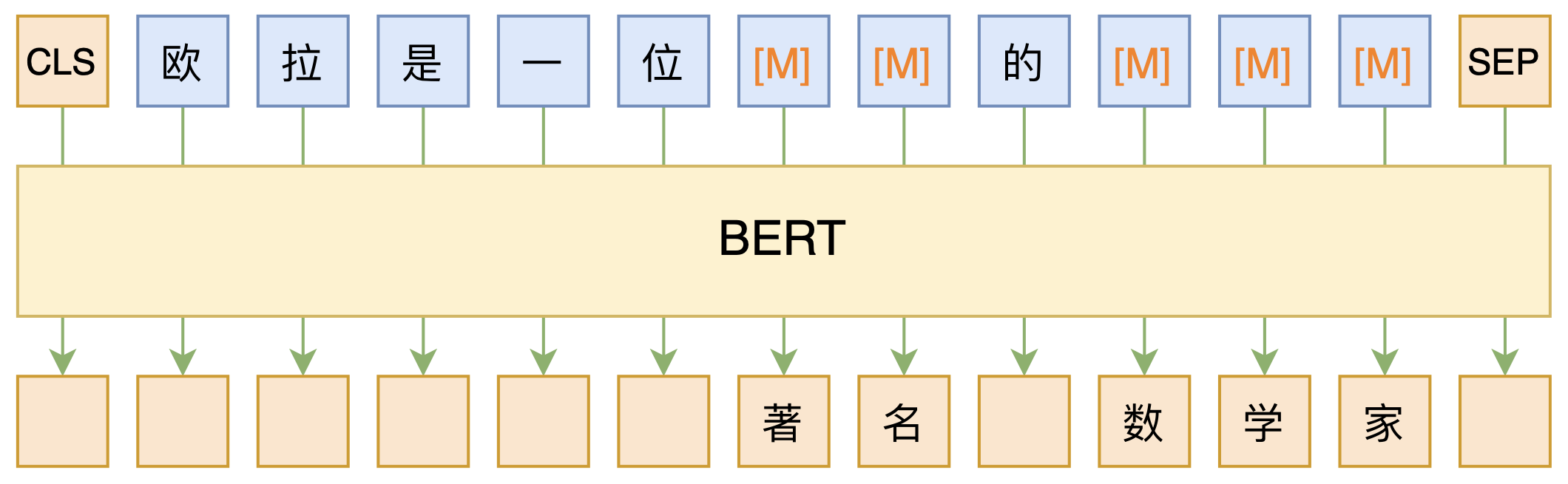
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。

最近评论