






10
Apr
分享一次专业领域词汇的无监督挖掘
By 苏剑林 | 2019-04-10 | 85746位读者 | 引用去年 Data Fountain 曾举办了一个“电力专业领域词汇挖掘”的比赛,该比赛有意思的地方在于它是一个“无监督”的比赛,也就是说它考验的是从大量的语料中无监督挖掘专业词汇的能力。
这个显然确实是工业界比较有价值的一个能力,又想着我之前也在无监督新词发现中做过一定的研究,加之“无监督比赛”的新颖性,所以当时毫不犹豫地参加了,然而最终排名并不靠前~
不管怎样,还是分享一下我自己的做法,这是一个真正意义上的无监督做法,也许会对部分读者有些参考价值。
基准对比
首先,新词发现部分,用到了我自己写的库nlp zero,基本思路是先分别对“比赛所给语料”、“自己爬的一部分百科百科语料”做新词发现,然后两者进行对比,就能找到一批“比赛所给语料”的特征词。
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 116911位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
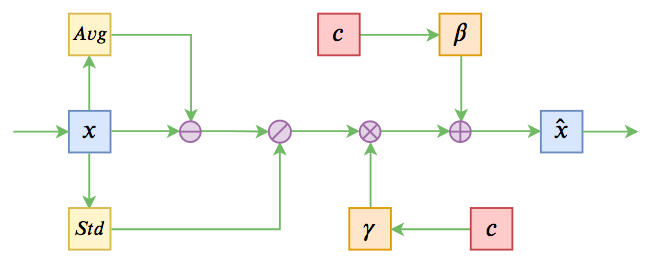
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。
18
Jul
日全食多路联合直播频道
By 苏剑林 | 2009-07-18 | 17290位读者 | 引用
29
Jul
生活中的趣味数学:同一天生日概率有多大
By 苏剑林 | 2009-07-29 | 29463位读者 | 引用
6
Aug
逻辑推理:拿了多少分(PuzzleUp)
By 苏剑林 | 2009-08-06 | 17857位读者 | 引用
31
Oct
“战神”升空看它到底有多神?
By 苏剑林 | 2009-10-31 | 22449位读者 | 引用
17
Jan
【竖直上抛】炮弹能够射多高(第二宇宙速度)?
By 苏剑林 | 2010-01-17 | 43237位读者 | 引用一枚炮弹以速度$v_0$向上射出,只考虑重力因素,请问炮弹到达多远的距离后就会开始自由下落?

大炮的发射
对于这个问题,我们首先采取的是高中生的做法。考虑地球重力,也就是说炮弹在做加速度为
此即炮弹能够走得最远距离。
但是看了这条式子,我们会发现,这个“距离”始终是有限的。换一句话说,只要$v_0$不趋于无穷大,s就不会无穷大。但是我们还听到过牛顿这样说过:假如炮弹以某个速度(就是我们现在所所说的第二宇宙速度)飞离地球,它就永远不会回来了。两者不是矛盾吗?
23
Jan


最近评论