






24
Jun
OCR技术浅探:4. 文字定位
By 苏剑林 | 2016-06-24 | 38605位读者 | 引用经过第一部分,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步:1、邻近搜索,目的是圈出单行文字;2、文本切割,目的是将单行文本切割为单字.
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字. 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元”这些字,由于不具有连通性,所以就被分拆开了,如图13. 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域.

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来. 如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了. 因此,我们只允许区域向单一的一个方向膨胀. 我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向.
既然涉及到了邻近,那么就需要有距离的概念. 下面给出一个比较合理的距离的定义.
距离
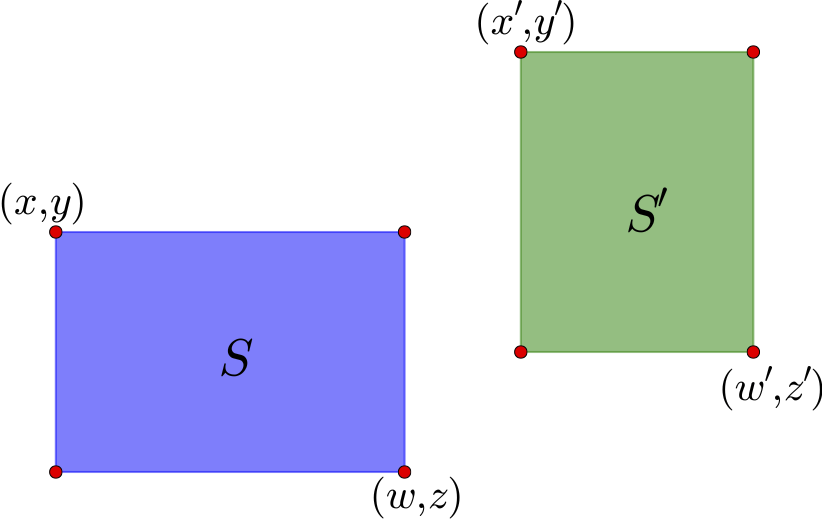
图14 两个示例区域
如上图,通过左上角坐标$(x,y)$和右下角坐标$(z,w)$就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的. 这个区域的中心是$\left(\frac{x+w}{2},\frac{y+z}{2}\right)$. 对于图中的两个区域$S$和$S'$,可以计算它们的中心向量差
$$(x_c,y_c)=\left(\frac{x'+w'}{2}-\frac{x+w}{2},\frac{y'+z'}{2}-\frac{y+z}{2}\right)\tag{10}$$
如果直接使用$\sqrt{x_c^2+y_c^2}$作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点. 因此,需要减去区域的长度:
$$(x'_c,y'_c)=\left(x_c-\frac{w-x}{2}-\frac{w'-x'}{2},y_c-\frac{z-y}{2}-\frac{z'-y'}{2}\right)\tag{11}$$
距离定义为
$$d(S,S')=\sqrt{[\max(x'_c,0)]^2+[\max(y'_c,0)]^2}\tag{12}$$
至于方向,由$(x_c,y_c)$的幅角进行判断即可.
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作.
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域. 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合.
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15.

图15 通过邻近搜索后,圈出的文字区域
24
Jun
OCR技术浅探:5. 文本切割
By 苏剑林 | 2016-06-24 | 43994位读者 | 引用

14
Mar
泰迪杯赛前培训之数据挖掘与建模“慢谈”
By 苏剑林 | 2017-03-14 | 30828位读者 | 引用
泰迪杯赛前培训
应广州泰迪科技公司之邀,给泰迪杯数据挖掘竞赛录制了赛前培训视频,内容基本上是各种常见的数学模型及入门用法,以一种比较独特的思路,将朴素贝叶斯、HMM、逻辑回归、组合模型、神经网络、深度学习等等串了起来。视频讲解难度为入门级,当然,真的要融合贯通所有内容,恐怕要骨灰级。
不管怎么样,简单分享一下,欢迎大家留言讨论、建议甚至批评。
PPT下载:泰迪杯赛前培训ppt.zip
24
Jul
基于Xception的腾讯验证码识别(样本+代码)
By 苏剑林 | 2017-07-24 | 89247位读者 | 引用去年的时候,有幸得到网友提供的一批腾讯验证码样本,因此也研究了一下,过程记录在《端到端的腾讯验证码识别(46%正确率)》中。
后来,这篇文章引起了不少读者的兴趣,有求样本的,有求模型的,有一起讨论的,让我比较意外。事实上,原来的模型做得比较粗糙,尤其是准确率难登大雅之台,参考价值不大。这几天重新折腾了一下,弄了个准确率高一点的模型,同时也把样本公开给大家。
模型的思路跟《端到端的腾讯验证码识别(46%正确率)》是一样的,只不过把CNN部分换成了现成的Xception结构,当然,读者也可以换VGG、Resnet50等玩玩,事实上对验证码识别来说,这些模型都能够胜任。我挑选Xception,是因为它层数不多,模型权重也较小,我比较喜欢而已。
代码
3
Jul
《交换代数导引》参考答案
By 苏剑林 | 2017-07-03 | 34477位读者 | 引用这学期我们的一门课是《交换代数》,是本科抽象代数的升级版。我们用的教材是Atiyah的《Introduction to Commutative Algebra》(交换代数导引),而且根据老师的上课安排,还需要我们把部分课后习题完成并讲解...不得不说这门课上得真累啊~
习题做到后面,我干脆懒得起草稿了,直接把做的答案用LaTeX录入了,既方便排版也方便修改。在这里分享给有需要的读者~答案是用中文写的,注释比较详细,适合刚学这门课的同学~
笔者所做的部分:《交换代数导引》参考答案.pdf
当然这份答案只包括老师对我们的要求的那部分习题,下面是网上搜索到的完整的习题解答,英文版的:
网上找到的答案:Jeffrey Daniel Kasik Carlson - Exercises to Atiya.pdf
如果答案有问题,欢迎留言指出。
27
Oct
什么时候多进程的加速比可以大于1?
By 苏剑林 | 2019-10-27 | 55266位读者 | 引用多进程或者多线程等并行加速目前已经不是什么难事了,相信很多读者都体验过。一般来说,我们会有这样的结论:多进程的加速比很难达到1。换句话说,当你用10进程去并行跑一个任务时,一般只能获得不到10倍的加速,而且进程越多,这个加速比往往就越低。
要注意,我们刚才说“很难达到1”,说明我们的潜意识里就觉得加速比最多也就是1。理论上确实是的,难不成用10进程还能获得20倍的加速?这不是天上掉馅饼吗?不过我前几天确实碰到了一个加速比远大于1的例子,所以在这里跟大家分享一下。
词频统计
我的原始任务是统计词频:我有很多文章,然后我们要对这些文章进行分词,最后汇总出一个词频表出来。一般的写法是这样的:
tokens = {}
for text in read_texts():
for token in tokenize(text):
tokens[token] = tokens.get(token, 0) + 1这种写法在我统计THUCNews全部文章的词频时,大概花了20分钟。
29
Dec
SquarePlus:可能是运算最简单的ReLU光滑近似
By 苏剑林 | 2021-12-29 | 36567位读者 | 引用ReLU函数,也就是$\max(x,0)$,是最常见的激活函数之一,然而它在$x=0$处的不可导通常也被视为一个“槽点”。为此,有诸多的光滑近似被提出,比如SoftPlus、GeLU、Swish等,不过这些光滑近似无一例外地至少都使用了指数运算$e^x$(SoftPlus还用到了对数),从“精打细算”的角度来看,计算量还是不小的(虽然当前在GPU加速之下,我们很少去感知这点计算量了)。最近有一篇论文《Squareplus: A Softplus-Like Algebraic Rectifier》提了一个更简单的近似,称为SquarePlus,我们也来讨论讨论。
需要事先指出的是,笔者是不建议大家花太多时间在激活函数的选择和设计上的,所以虽然分享了这篇论文,但主要是提供一个参考结果,并充当一道练习题来给大家“练练手”。
定义
SquarePlus的形式很简单,只用到了加、乘、除和开方:
\begin{equation}\text{SquarePlus}(x)=\frac{x+\sqrt{x^2+b}}{2}\end{equation}
10
May
logsumexp运算的几个不等式
By 苏剑林 | 2022-05-10 | 20481位读者 | 引用$\text{logsumexp}$是机器学习经常遇到的运算,尤其是交叉熵的相关实现和推导中都会经常出现,同时它还是$\max$的光滑近似(参考《寻求一个光滑的最大值函数》)。设$x=(x_1,x_2,\cdots,x_n)$,$\text{logsumexp}$定义为
\begin{equation}\text{logsumexp}(x)=\log\sum_{i=1}^n e^{x_i}\end{equation}
本文来介绍$\text{logsumexp}$的几个在理论推导中可能用得到的不等式。
基本界
记$x_{\max} = \max(x_1,x_2,\cdots,x_n)$,那么显然有
\begin{equation}e^{x_{\max}} < \sum_{i=1}^n e^{x_i} \leq \sum_{i=1}^n e^{x_{\max}} = ne^{x_{\max}}\end{equation}
各端取对数即得
\begin{equation}x_{\max} < \text{logsumexp}(x) \leq x_{\max} + \log n\end{equation}

最近评论