






18
Mar
变分自编码器(一):原来是这么一回事
By 苏剑林 | 2018-03-18 | 1126371位读者 | 引用过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量Z生成目标数据X的模型,但是实现上有所不同。更准确地讲,它们是假设了Z服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型X=g(Z),这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
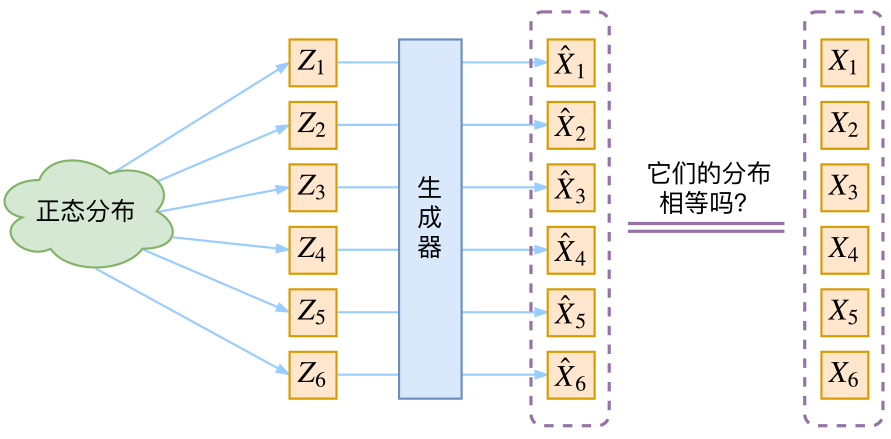
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
28
Mar
变分自编码器(二):从贝叶斯观点出发
By 苏剑林 | 2018-03-28 | 539359位读者 | 引用源起
前几天写了博文《变分自编码器(一):原来是这么一回事》,从一种比较通俗的观点来理解变分自编码器(VAE),在那篇文章的视角中,VAE跟普通的自编码器差别不大,无非是多加了噪声并对噪声做了约束。然而,当初我想要弄懂VAE的初衷,是想看看究竟贝叶斯学派的概率图模型究竟是如何与深度学习结合来发挥作用的,如果仅仅是得到一个通俗的理解,那显然是不够的。
所以我对VAE继续思考了几天,试图用更一般的、概率化的语言来把VAE说清楚。事实上,这种思考也能回答通俗理解中无法解答的问题,比如重构损失用MSE好还是交叉熵好、重构损失和KL损失应该怎么平衡,等等。
建议在阅读《变分自编码器(一):原来是这么一回事》后对本文进行阅读,本文在内容上尽量不与前文重复。
准备
在进入对VAE的描述之前,我觉得有必要把一些概念性的内容讲一下。
17
Sep
变分自编码器(四):一步到位的聚类方案
By 苏剑林 | 2018-09-17 | 400305位读者 | 引用由于VAE中既有编码器又有解码器(生成器),同时隐变量分布又被近似编码为标准正态分布,因此VAE既是一个生成模型,又是一个特征提取器。在图像领域中,由于VAE生成的图片偏模糊,因此大家通常更关心VAE作为图像特征提取器的作用。提取特征都是为了下一步的任务准备的,而下一步的任务可能有很多,比如分类、聚类等。本文来关心“聚类”这个任务。
一般来说,用AE或者VAE做聚类都是分步来进行的,即先训练一个普通的VAE,然后得到原始数据的隐变量,接着对隐变量做一个K-Means或GMM之类的。但是这样的思路的整体感显然不够,而且聚类方法的选择也让我们纠结。本文介绍基于VAE的一个“一步到位”的聚类思路,它同时允许我们完成无监督地完成聚类和条件生成。
理论
一般框架
回顾VAE的loss(如果没印象请参考《变分自编码器(二):从贝叶斯观点出发》):
KL(p(x,z)‖q(x,z))=∬p(z|x)˜p(x)lnp(z|x)˜p(x)q(x|z)q(z)dzdx
通常来说,我们会假设q(z)是标准正态分布,p(z|x),q(x|z)是条件正态分布,然后代入计算,就得到了普通的VAE的loss。
10
Oct
变分自编码器 = 最小化先验分布 + 最大化互信息
By 苏剑林 | 2018-10-10 | 138064位读者 | 引用这篇文章很简短,主要描述的是一个很有用、也不复杂、但是我居然这么久才发现的事实~
在《深度学习的互信息:无监督提取特征》一文中,我们通过先验分布和最大化互信息两个loss的加权组合来得到Deep INFOMAX模型最后的loss。在那篇文章中,虽然把故事讲完了,但是某种意义上来说,那只是个拼凑的loss。而本文则要证明那个loss可以由变分自编码器自然地导出来。
过程
不厌其烦地重复一下,变分自编码器(VAE)需要优化的loss是
KL(˜p(x)p(z|x)‖q(z)q(x|z))=∬˜p(x)p(z|x)log˜p(x)p(z|x)q(x|z)q(z)dzdx
相关的论述在本博客已经出现多次了。VAE中既包含编码器,又包含解码器,如果我们只需要编码特征,那么再训练一个解码器就显得很累赘了。所以重点是怎么将解码器去掉。
其实再简单不过了,把VAE的loss分开两部分
27
Nov
从变分编码、信息瓶颈到正态分布:论遗忘的重要性
By 苏剑林 | 2018-11-27 | 181405位读者 | 引用这是一篇“散文”,我们来谈一下有着千丝万缕联系的三个东西:变分自编码器、信息瓶颈、正态分布。
众所周知,变分自编码器是一个很经典的生成模型,但实际上它有着超越生成模型的含义;而对于信息瓶颈,大家也许相对陌生一些,然而事实上信息瓶颈在去年也热闹了一阵子;至于正态分布,那就不用说了,它几乎跟所有机器学习领域都有或多或少的联系。
那么,当它们三个碰撞在一块时,又有什么样的故事可说呢?它们跟“遗忘”又有什么关系呢?
变分自编码器
在本博客你可以搜索到若干几篇介绍VAE的文章。下面简单回顾一下。
理论形式回顾
简单来说,VAE的优化目标是:
KL(˜p(x)p(z|x)‖q(z)q(x|z))=∬˜p(x)p(z|x)log˜p(x)p(z|x)q(x|z)q(z)dzdx
其中q(z)是标准正态分布,p(z|x),q(x|z)是条件正态分布,分别对应编码器、解码器。具体细节可以参考《变分自编码器(二):从贝叶斯观点出发》。
10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 83403位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
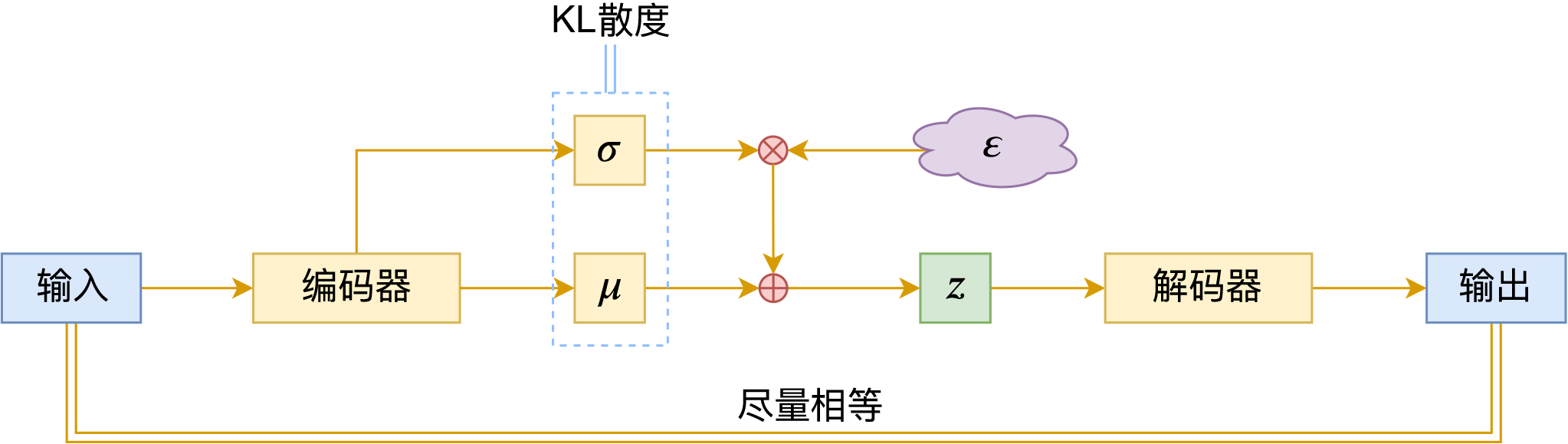
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
17
May
变分自编码器(七):球面上的VAE(vMF-VAE)
By 苏剑林 | 2021-05-17 | 162181位读者 | 引用在《变分自编码器(五):VAE + BN = 更好的VAE》中,我们讲到了NLP中训练VAE时常见的KL散度消失现象,并且提到了通过BN来使得KL散度项有一个正的下界,从而保证KL散度项不会消失。事实上,早在2018年的时候,就有类似思想的工作就被提出了,它们是通过在VAE中改用新的先验分布和后验分布,来使得KL散度项有一个正的下界。
该思路出现在2018年的两篇相近的论文中,分别是《Hyperspherical Variational Auto-Encoders》和《Spherical Latent Spaces for Stable Variational Autoencoders》,它们都是用定义在超球面的von Mises–Fisher(vMF)分布来构建先后验分布。某种程度上来说,该分布比我们常用的高斯分布还更简单和有趣~
KL散度消失
我们知道,VAE的训练目标是
L=Ex∼˜p(x)[Ez∼p(z|x)[−logq(x|z)]+KL(p(z|x)‖q(z))]
9
Dec
变分自编码器(八):估计样本概率密度
By 苏剑林 | 2021-12-09 | 76876位读者 | 引用在本系列的前面几篇文章中,我们已经从多个角度来理解了VAE,一般来说,用VAE是为了得到一个生成模型,或者是做更好的编码模型,这都是VAE的常规用途。但除了这些常规应用外,还有一些“小众需求”,比如用来估计x的概率密度,这在做压缩的时候通常会用到。
本文就从估计概率密度的角度来了解和推导一下VAE模型。
两个问题
所谓估计概率密度,就是在已知样本x1,x2,⋯,xN∼˜p(x)的情况下,用一个待定的概率密度簇qθ(x)去拟合这批样本,拟合的目标一般是最小化负对数似然:
Ex∼˜p(x)[−logqθ(x)]=−1NN∑i=1logqθ(xi)

最近评论