






7
Dec
【龟鱼记】全陶粒的同程底滤生态缸
By 苏剑林 | 2020-12-07 | 66985位读者 | 引用
19
Jul
用开源的人工标注数据来增强RoFormer-Sim
By 苏剑林 | 2021-07-19 | 164314位读者 | 引用大家知道,从SimBERT到SimBERTv2(RoFormer-Sim),我们算是为中文文本相似度任务建立了一个还算不错的基准模型。然而,SimBERT和RoFormer-Sim本质上都只是“弱监督”模型,跟“无监督”类似,我们不能指望纯弱监督的模型能达到完美符合人的认知效果。所以,为了进一步提升RoFormer-Sim的效果,我们尝试了使用开源的一些标注数据来辅助训练。本文就来介绍我们的探索过程。
有的读者可能想:有监督有啥好讲的?不就是直接训练么?说是这么说,但其实并没有那么“显然易得”,还是有些“雷区”的,所以本文也算是一份简单的“扫雷指南”吧。
前情回顾
笔者发现,自从SimBERT发布后,读者问得最多的问题大概是:
为什么“我喜欢北京”跟“我不喜欢北京”相似度这么高?它们不是意思相反吗?
10
Sep
曾被嫌弃的预训练任务NSP,做出了优秀的Zero Shot效果
By 苏剑林 | 2021-09-10 | 61199位读者 | 引用在五花八门的预训练任务设计中,NSP通常认为是比较糟糕的一种,因为它难度较低,加入到预训练中并没有使下游任务微调时有明显受益,甚至RoBERTa的论文显示它会带来负面效果。所以,后续的预训练工作一般有两种选择:一是像RoBERTa一样干脆去掉NSP任务,二是像ALBERT一样想办法提高NSP的难度。也就是说,一直以来NSP都是比较“让人嫌弃”的。
不过,反转来了,NSP可能要“翻身”了。最近的一篇论文《NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task--Next Sentence Prediction》(下面简称NSP-BERT)显示NSP居然也可以做到非常不错的Zero Shot效果!这又是一个基于模版(Prompt)的Few/Zero Shot的经典案例,只不过这一次的主角是NSP。
背景回顾
曾经我们认为预训练纯粹就是预训练,它只是为下游任务的训练提供更好的初始化,像BERT的预训练任务有MLM(Masked Language Model和NSP(Next Sentence Prediction),在相当长的一段时间内,大家都不关心这两个预训练任务本身,而只是专注于如何通过微调来使得下游任务获得更好的性能。哪怕是T5将模型参数训练到了110亿,走的依然是“预训练+微调”这一路线。
29
Dec
SquarePlus:可能是运算最简单的ReLU光滑近似
By 苏剑林 | 2021-12-29 | 44161位读者 | 引用ReLU函数,也就是max(x,0),是最常见的激活函数之一,然而它在x=0处的不可导通常也被视为一个“槽点”。为此,有诸多的光滑近似被提出,比如SoftPlus、GeLU、Swish等,不过这些光滑近似无一例外地至少都使用了指数运算ex(SoftPlus还用到了对数),从“精打细算”的角度来看,计算量还是不小的(虽然当前在GPU加速之下,我们很少去感知这点计算量了)。最近有一篇论文《Squareplus: A Softplus-Like Algebraic Rectifier》提了一个更简单的近似,称为SquarePlus,我们也来讨论讨论。
需要事先指出的是,笔者是不建议大家花太多时间在激活函数的选择和设计上的,所以虽然分享了这篇论文,但主要是提供一个参考结果,并充当一道练习题来给大家“练练手”。
定义
SquarePlus的形式很简单,只用到了加、乘、除和开方:
SquarePlus(x)=x+√x2+b2
10
May
logsumexp运算的几个不等式
By 苏剑林 | 2022-05-10 | 27287位读者 | 引用logsumexp是机器学习经常遇到的运算,尤其是交叉熵的相关实现和推导中都会经常出现,同时它还是max的光滑近似(参考《寻求一个光滑的最大值函数》)。设x=(x1,x2,⋯,xn),logsumexp定义为
logsumexp(x)=logn∑i=1exi
本文来介绍logsumexp的几个在理论推导中可能用得到的不等式。
基本界
记xmax=max(x1,x2,⋯,xn),那么显然有
exmax<n∑i=1exi≤n∑i=1exmax=nexmax
各端取对数即得
xmax<logsumexp(x)≤xmax+logn
20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 83214位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 23990位读者 | 引用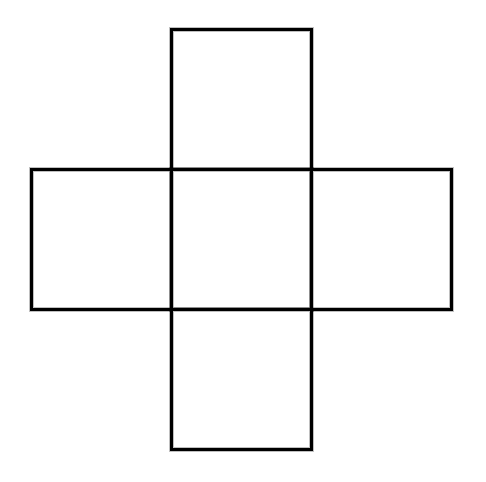
13
Nov
【生活杂记】炒锅的尽头是铁锅
By 苏剑林 | 2023-11-13 | 66303位读者 | 引用
铁锅(网络图)
很多会下厨的同学估计都纠结过一件事情,那就是炒锅的选择。
对于炒锅的纠结,归根结底是不粘与方便的权衡。最简单的不粘锅自然是带涂层的不粘锅,如果家里的热源只有电磁炉,并且炒菜习惯比较温和,那么涂层不粘锅往往是最佳选择了。不过,一旦有了明火的燃气灶,又或者是比较喜欢爆炒,那么涂层锅可能就不是那么适合了,毕竟温度过高涂层总有脱落的风险,此时一般就考虑无涂层不粘锅。
无涂层不粘锅也有五花八门的选择,比如朴素的铁锅、带蜂窝纹的不锈钢锅、有钛锅、纯钛锅等等,价格大体上也单调递增。不过用到最后,我觉得大部分人都会回归到朴素的铁锅。

最近评论