






24
Apr
【语料】2500万中文三元组!
By 苏剑林 | 2017-04-24 | 97679位读者 | 引用闲聊
这两年,知识图谱、问答系统、聊天机器人等领域是越来越火了。知识图谱是一个很泛化的概念,在我看来,涉及到知识库的构建、检索、利用等机器学习相关的内容,都算知识图谱。当然,这也不是个什么定义,只是个人的直观感觉。
做知识图谱的读者都知道,三元组是结构化知识的一种方法,是做知识型问答系统的重要组成部分。对于英文领域,已经有一些较大的开源的三元组语料库,而很显然,中文目前还没有这样的语料库共享(哪怕有人爬取到了,也珍藏起来了)。笔者前段时间写了个百度百科的爬虫,爬了一段时间,抓了几百万个百度百科的词条。其中不少词条含有一些结构化的信息,直接抽取出来,就是有效的“三元组”了,可以用来做知识图谱。本文分享的三元组语料正是由此而来,共有2500万个三元组。

百度百科的三元组
7
Jun
通用爬虫探索(三):效果展示与代码
By 苏剑林 | 2017-06-07 | 61099位读者 | 引用
19
Nov
更别致的词向量模型(三):描述相关的模型
By 苏剑林 | 2017-11-19 | 131684位读者 | 引用几何词向量
上述“月老”之云虽说只是幻想,但所面临的问题却是真实的。按照传统NLP的手段,我们可以统计任意两个词的共现频率以及每个词自身的频率,然后去算它们的相关度,从而得到一个“相关度矩阵”。然而正如前面所说,这个共现矩阵太庞大了,必须压缩降维,同时还要做数据平滑,给未出现的词对的相关度赋予一个合理的估值。
在已有的机器学习方案中,我们已经有一些对庞大的矩阵降维的经验了,比如SVD和pLSA,SVD是对任意矩阵的降维,而pLSA是对转移概率矩阵P(j|i)的降维,两者的思想是类似的,都是将一个大矩阵A分解为两个小矩阵的乘积A≈BC,其中B的行数等于A的行数,C的列数等于A的列数,而它们本身的大小则远小于A的大小。如果对B,C不做约束,那么就是SVD;如果对B,C做正定归一化约束,那就是pLSA。
但是如果是相关度矩阵,那么情况不大一样,它是正定的但不是归一的,我们需要为它设计一个新的压缩方案。借鉴矩阵分解的经验,我们可以设想把所有的词都放在n维空间中,也就是用n维空间中的一个向量来表示,并假设它们的相关度就是内积的某个函数(为什么是内积?因为矩阵乘法本身就是不断地做内积):
P(wi,wj)P(wi)P(wj)=f(⟨vi,vj⟩)
其中加粗的vi,vj表示词wi,wj对应的词向量。从几何的角度看,我们就是把词语放置到了n维空间中,用空间中的点来表示一个词。
因为几何给我们的感觉是直观的,而语义给我们的感觉是复杂的,因此,理想情况下我们希望能够通过几何关系来反映语义关系。下面我们就根据我们所希望的几何特性,来确定待定的函数f。事实上,glove词向量的那篇论文中做过类似的事情,很有启发性,但glove的推导实在是不怎么好看。请留意,这里的观点是新颖的——从我们希望的性质,来确定我们的模型,而不是反过来有了模型再推导性质。
机场-飞机+火车=火车站
25
Nov
果壳中的条件随机场(CRF In A Nutshell)
By 苏剑林 | 2017-11-25 | 126338位读者 | 引用本文希望用尽可能简短的语言把CRF(条件随机场,Conditional Random Field)的原理讲清楚,这里In A Nutshell在英文中其实有“导论”、“科普”等意思(霍金写过一本《果壳中的宇宙》,这里东施效颦一下)。
网上介绍CRF的文章,不管中文英文的,基本上都是先说一些概率图的概念,然后引入特征的指数公式,然后就说这是CRF。所谓“概率图”,只是一个形象理解的说法,然而如果原理上说不到点上,你说太多形象的比喻,反而让人糊里糊涂,以为你只是在装逼。(说到这里我又想怼一下了,求解神经网络,明明就是求一下梯度,然后迭代一下,这多好理解,偏偏还弄个装逼的名字叫“反向传播”,如果不说清楚它的本质是求导和迭代求解,一下子就说反向传播,有多少读者会懂?)
好了,废话说完了,来进入正题。
逐标签Softmax
CRF常见于序列标注相关的任务中。假如我们的模型输入为Q,输出目标是一个序列a1,a2,…,an,那么按照我们通常的建模逻辑,我们当然是希望目标序列的概率最大
P(a1,a2,…,an|Q)
不管用传统方法还是用深度学习方法,直接对完整的序列建模是比较艰难的,因此我们通常会使用一些假设来简化它,比如直接使用朴素假设,就得到
P(a1,a2,…,an|Q)=P(a1|Q)P(a2|Q)…P(an|Q)
31
May
基于最小熵原理的NLP库:nlp zero
By 苏剑林 | 2018-05-31 | 113376位读者 | 引用陆陆续续写了几篇最小熵原理的博客,致力于无监督做NLP的一些基础工作。为了方便大家实验,把文章中涉及到的一些算法封装为一个库,供有需要的读者测试使用。
由于面向的是无监督NLP场景,而且基本都是NLP任务的基础工作,因此命名为nlp zero。
地址
Github: https://github.com/bojone/nlp-zero
Pypi: https://pypi.org/project/nlp-zero/
可以直接通过
pip install nlp-zero==0.1.6进行安装。整个库纯Python实现,没有第三方调用,支持Python2.x和3.x。
26
Mar
科学空间浏览指南(FAQ)
By 苏剑林 | 2019-03-26 | 147535位读者 | 引用事实上,除了写博客内容,在这几年里,笔者是花了相当一部分时间来做科学空间的“表面功夫”,为此还专门学了一点php、css和js。虽然不敢说精益求精,但总体来说网站的浏览体验应该比前几年要好得多。
考虑到有些读者可能需要的功能,但一时半会未必能留意到,遂来整理一些站内技巧。
文章篇
什么环境阅读文章最佳?
两年前科学空间就已经加入了响应式设计,自动适应不同分辨率的屏幕。因此,不管哪个分辨率的环境应该都能看清文字内容,唯一的问题是,在小屏幕手机下公式可能会显示不全或者错位。为了较好地阅读公式,最好在7寸以上的屏幕上阅读。如果一定要用小屏幕的手机,可以考虑横屏阅读。
21
Feb
GPLinker:基于GlobalPointer的事件联合抽取
By 苏剑林 | 2022-02-21 | 89182位读者 | 引用大约两年前,笔者在百度的“2020语言与智能技术竞赛”中首次接触到了事件抽取任务,并在文章《bert4keras在手,baseline我有:百度LIC2020》中分享了一个转化为BERT+CRF做NER的简单baseline。不过,当时的baseline更像是一个用来凑数的半成品,算不上一个完整的事件抽取模型。而这两年来,关系抽取的模型层见迭出,SOTA一个接一个,但事件抽取似乎没有多亮眼的设计。
最近笔者重新尝试了事件抽取任务,在之前的关系抽取模型GPLinker的基础上,结合完全子图搜索,设计一个比较简单但相对完备的事件联合抽取模型,依然称之为GPLinker,在此请大家点评一番。
任务简介
事件抽取是一个比较综合的任务。一个标准的事件抽取样本如下:
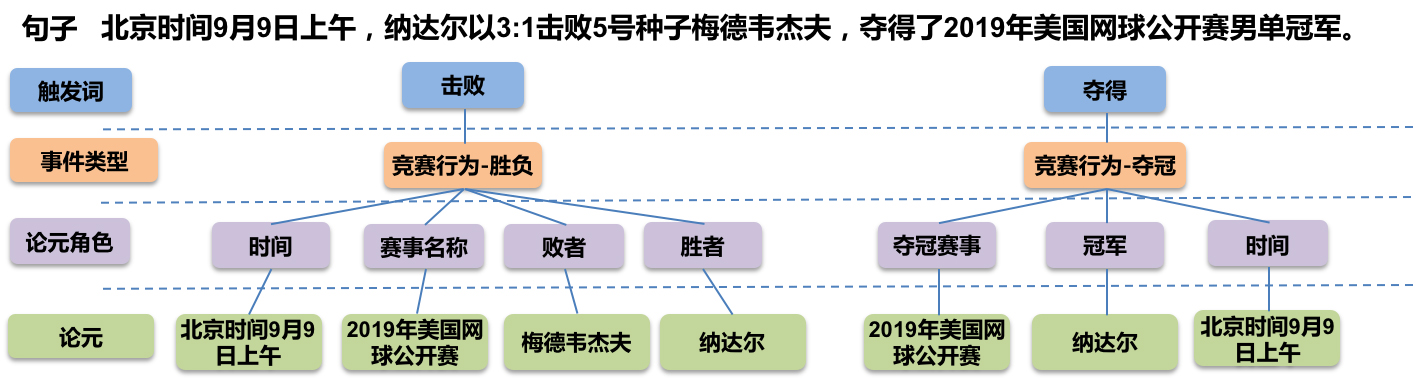
标准的事件抽取样本(图片来自百度DuEE的GitHub)
21
Mar
RoFormerV2:自然语言理解的极限探索
By 苏剑林 | 2022-03-21 | 71029位读者 | 引用大概在1年前,我们提出了旋转位置编码(RoPE),并发布了对应的预训练模型RoFormer。随着时间的推移,RoFormer非常幸运地得到了越来越多的关注和认可,比如EleutherAI新发布的60亿和200亿参数的GPT模型中就用上了RoPE位置编码,Google新提出的FLASH模型论文中则明确指出了RoPE对Transformer效果有明显的提升作用。
与此同时,我们也一直在尝试继续加强RoFormer模型,试图让RoFormer的性能“更上一层楼”。经过近半年的努力,我们自认为取得了还不错的成果,因此将其作为“RoFormerV2”正式发布:

最近评论