






26
Dec
【学习清单】最近比较重要的GAN进展论文
By 苏剑林 | 2018-12-26 | 56613位读者 | 引用这篇文章简单列举一下我认为最近这段时间中比较重要的GAN进展论文,这基本也是我在学习GAN的过程中主要去研究的论文清单。
生成模型之味
GAN是一个大坑,尤其像我这样的业余玩家,一头扎进去很久也很难有什么产出,尤其是各个大公司拼算力搞出来一个个大模型,个人几乎都没法玩了。但我总觉得,真的去碰了生成模型,才觉得自己碰到了真正的机器学习。这一点,不管在图像中还是文本中都是如此。所以,我还是愿意去关注生成模型。
当然,GAN不是生成模型的唯一选择,却是一个非常有趣的选择。在图像中至少有GAN、flow、pixelrnn/pixelcnn这几种选择,但要说潜力,我还是觉得GAN才是最具前景的,不单是因为效果,主要是因为它那对抗的思想。而在文本中,事实上seq2seq机制就是一个概率生成模型了,而pixelrnn这类模型,实际上就是模仿着seq2seq来做的,当然也有用GAN做文本生成的研究(不过基本上都涉及到了强化学习)。也就是说,其实在NLP中,生成模型也有很多成果,哪怕你主要是研究NLP的,也终将碰到生成模型。
好了,话不多说,还是赶紧把清单列一列,供大家参考,也作为自己的备忘。
20
Jun
《虚拟的实在(3)》——相对论动力学
By 苏剑林 | 2013-06-20 | 21915位读者 | 引用半个多月没有写文章了,一是因为接近期末考了,比较忙,当然最主要的原因还是人变懒了,呵呵,别人是忙里偷闲,我是闲里偷懒了。
这篇文章主要跟大家分享一下相对论动力学的知识。我们之前已经接触过相对论的坐标变换了,接下来的任务应该是把经典力学的动力学定律改成为相对论版本的,这显然也是学习场论的必经之路——懂得如何构造力学定律的相对版版本,是懂得构造相对论性场的基础。和朗道的《力学》与《场论》一样,我们的主线就是“最小作用量原理”。让我们回忆一下,在经典力学中,一个自由粒子的作用量是
$$S_m=\int Ldt=\int \frac{1}{2} m v^2dt$$
18
Dec
迟到一年的建模:再探碎纸复原
By 苏剑林 | 2014-12-18 | 66917位读者 | 引用前言:一年前国赛的时候,很初级地做了一下B题,做完之后还写了个《碎纸复原:一个人的数学建模》。当时就是对题目很有兴趣,然后通过一天的学习,基本完成了附件一二的代码,对附件三也只是有个概念。而今年我们上的数学建模课,老师把这道题作为大作业让我们做,于是我便再拾起了一年前的那份激情,继续那未完成的一个人的数学建模...
与去年不同的是,这次将所有代码用Python实现了,更简洁,更清晰,甚至可能更高效~~以下是论文全文。
研究背景
2011年10月29日,美国国防部高级研究计划局(DARPA)宣布了一场碎纸复原挑战赛(Shredder Challenge),旨在寻找到高效有效的算法,对碎纸机处理后的碎纸屑进行复原。[1]该竞赛吸引了全美9000支参赛队伍参与角逐,经过一个多月的时间,有一支队伍成功完成了官方的题目。
近年来,碎纸复原技术日益受到重视,它显示了在碎片中“还原真相”的可能性,表明我们可以从一些破碎的片段中“解密”出原始信息来。另一方面,该技术也和照片处理领域中的“全景图拼接技术”有一定联系,该技术是指通过若干张不同侧面的照片,合成一张完整的全景图。因此,分析研究碎纸复原技术,有着重要的意义。
12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 131045位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
23
Jan
揭开迷雾,来一顿美味的Capsule盛宴
By 苏剑林 | 2018-01-23 | 390972位读者 | 引用
Geoffrey Hinton在谷歌多伦多办公室
由深度学习先驱Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,无疑是去年深度学习界最热点的消息之一。得益于各种媒体的各种吹捧,Capsule被冠以了各种神秘的色彩,诸如“抛弃了梯度下降”、“推倒深度学习重来”等字眼层出不穷,但也有人觉得Capsule不外乎是一个新的炒作概念。
本文试图揭开让人迷惘的云雾,领悟Capsule背后的原理和魅力,品尝这一顿Capsule盛宴。同时,笔者补做了一个自己设计的实验,这个实验能比原论文的实验更有力说明Capsule的确产生效果了。
菜谱一览:
1、Capsule是什么?
2、Capsule为什么要这样做?
3、Capsule真的好吗?
4、我觉得Capsule怎样?
5、若干小菜。
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 193104位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
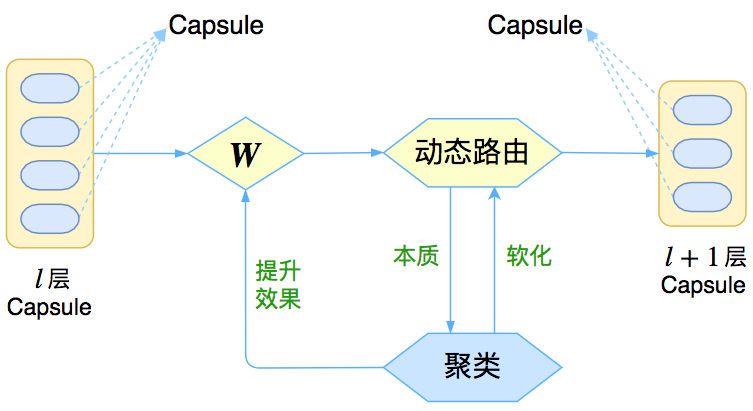
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 114057位读者 | 引用在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
![P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
24
May
也来盘点一些最近的非Transformer工作
By 苏剑林 | 2021-05-24 | 49256位读者 | 引用大家最近应该多多少少都被各种MLP相关的工作“席卷眼球”了。以Google为主的多个研究机构“奇招频出”,试图从多个维度“打击”Transformer模型,其中势头最猛的就是号称是纯MLP的一系列模型了,让人似乎有种“MLP is all you need”时代到来的感觉。
这一顿顿让人眼花缭乱的操作背后,究竟是大道至简下的“返璞归真”,还是江郎才尽后的“冷饭重炒”?让我们也来跟着这股热潮,一起盘点一些最近的相关工作。
五月人倍忙
怪事天天有,五月特别多。这个月以来,各大机构似乎相约好了一样,各种非Transformer的工作纷纷亮相,仿佛“忽如一夜春风来,千树万树梨花开”。单就笔者在Arxiv上刷到的相关论文,就已经多达七篇(一个月还没过完,七篇方向极其一致的论文),涵盖了NLP和CV等多个任务,真的让人应接不暇:

最近评论