






29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 399458位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
26
Jun
OCR技术浅探:7. 语言模型
By 苏剑林 | 2016-06-26 | 49344位读者 | 引用由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一.
转移概率
在我们分析实验结果的过程中,有出现这一案例.由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择.但是语言模型却可以很巧妙地解决这个问题.原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”.
从概率的角度来看,就是对于第一个字的区域的识别结果$s_1$,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率$W(s_1)$分别为0.99996、0.00004;第二个字的区域的识别结果$s_2$,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率$W(s_2)$分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”.
26
Jun
OCR技术浅探:9. 代码共享(完)
By 苏剑林 | 2016-06-26 | 67143位读者 | 引用
17
Aug
【中文分词系列】 1. 基于AC自动机的快速分词
By 苏剑林 | 2016-08-17 | 94940位读者 | 引用前言:这个暑假花了不少时间在中文分词和语言模型上面,碰了无数次壁,也得到了零星收获。打算写一个专题,分享一下心得体会。虽说是专题,但仅仅是一些笔记式的集合,并非系统的教程,请读者见谅。
中文分词
关于中文分词的介绍和重要性,我就不多说了,matrix67这里有一篇关于分词和分词算法很清晰的介绍,值得一读。在文本挖掘中,虽然已经有不少文章探索了不分词的处理方法,如本博客的《文本情感分类(三):分词 OR 不分词》,但在一般场合都会将分词作为文本挖掘的第一步,因此,一个有效的分词算法是很重要的。当然,中文分词作为第一步,已经被探索很久了,目前做的很多工作,都是总结性质的,最多是微弱的改进,并不会有很大的变化了。
目前中文分词主要有两种思路:查词典和字标注。首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。查词典的方法简单高效(得益于动态规划的思想),尤其是结合了语言模型的最大概率法,能够很好地解决歧义问题,但对于中文分词一大难度——未登录词(中文分词有两大难度:歧义和未登录词),则无法解决;为此,人们也提出了基于字标注的思路,所谓字标注,就是通过几个标记(比如4标注的是:single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾),把句子的正确分词法表示出来。这是一个序列(输入句子)到序列(标记序列)的过程,能够较好地解决未登录词的问题,但速度较慢,而且对于已经有了完备词典的场景下,字标注的分词效果可能也不如查词典方法。总之,各有优缺点(似乎是废话~),实际使用可能会结合两者,像结巴分词,用的是有向无环图的最大概率组合,而对于连续的单字,则使用字标注的HMM模型来识别。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 78970位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
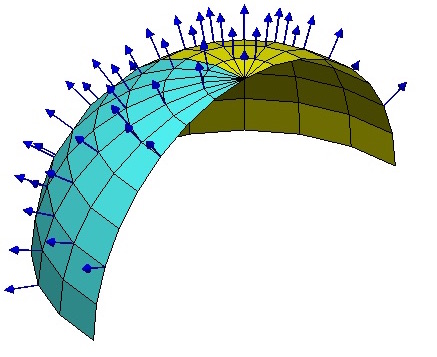
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 146674位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
14
Oct
【理解黎曼几何】1. 一条几何之路
By 苏剑林 | 2016-10-14 | 80223位读者 | 引用一个月没更新了,这个月花了不少时间在黎曼几何的理解方面,有一些体会,与大家分享。记得当初孟岩写的《理解矩阵》,和笔者所写的《新理解矩阵》,读者反响都挺不错的,这次沿用了这个名称,称之为《理解黎曼几何》。

生活在二维空间的蚂蚁
黎曼几何是研究内蕴几何的几何分支。通俗来讲,就是我们可能生活在弯曲的空间中,比如一只生活在二维球面的蚂蚁,作为生活在弯曲空间中的个体,我们并没有足够多的智慧去把我们的弯曲嵌入到更高维的空间中去研究,就好比蚂蚁只懂得在球面上爬,不能从“三维空间的曲面”这一观点来认识球面,因为球面就是它们的世界。因此,我们就有了内蕴几何,它告诉我们,即便是身处弯曲空间中,我们依旧能够测量长度、面积、体积等,我们依旧能够算微分、积分,甚至我们能够发现我们的空间是弯曲的!也就是说,身处球面的蚂蚁,只要有足够的智慧,它们就能发现曲面是弯曲的——跟哥伦布环球航行那样——它们朝着一个方向走,最终却回到了起点,这就可以断定它们自身所处的空间必然是弯曲的——这个发现不需要用到三维空间的知识。
15
Oct
【理解黎曼几何】3. 测地线
By 苏剑林 | 2016-10-15 | 55080位读者 | 引用测地线
黎曼度量应该是不难理解的,在微分几何的教材中,我们就已经学习过曲面的“第一基本形式”了,事实上两者是同样的东西,只不过看待问题的角度不同,微分几何是把曲面看成是三维空间中的二维子集,而黎曼几何则是从二维曲面本身内蕴地研究几何问题。
几何关心什么问题呢?事实上,几何关心的是与变换无关的“客观实体”(或者说是在变换之下不变的东西),这也是几何的定义。根据Klein提出的《埃尔朗根纲领》,几何就是研究在某种变换(群)下的不变性质的学科。如果把变换局限为刚性变换(平移、旋转、反射),那么就是欧式几何;如果变换为一般的线性变换,那就是仿射几何。而黎曼几何关心的是与一切坐标都无关的客观实体。比如说,我有一个向量,方向和大小都确定了,在直角坐标系是$(1, 1)$,在极坐标系是$(\sqrt{2}, \pi/4)$,虽然两个坐标系下的分量不同,但它们都是指代同一个向量。也就是说向量本身是客观存在的实体,跟所使用的坐标无关。从代数层面看,就是只要能够通过某种坐标变换相互得到的,我们就认为它们是同一个东西。
因此,在学习黎曼几何时,往“客观实体”方向思考,总是有益的。

平面上的测地线
有了度规,可以很自然地引入“测地线”这一实体。狭义来看,它就是两点间的最短线——是平直空间的直线段概念的推广(实际的测地线不一定是最短的,但我们先不纠结细节,而且这不妨碍我们理解它,因为测地线至少是局部最短的)。不难想到,只要两点确定了,那么不管使用什么坐标,两点间的最短线就已经确定了,因此这显然是一个客观实体。有一个简单的类比,就是不管怎么坐标变换,一个函数$f(x)$的图像极值点总是确定的——不管你变还是不变,它就在那儿,不偏不倚。

最近评论