






10
Sep
变分自编码器(六):从几何视角来理解VAE的尝试
By 苏剑林 | 2020-09-10 | 71985位读者 | 引用前段时间公司组织技术分享,轮到笔者时,大家希望我讲讲VAE。鉴于之前笔者也写过变分自编码器系列,所以对笔者来说应该也不是特别难的事情,因此就答应了下来,后来仔细一想才觉得犯难:怎么讲才好呢?
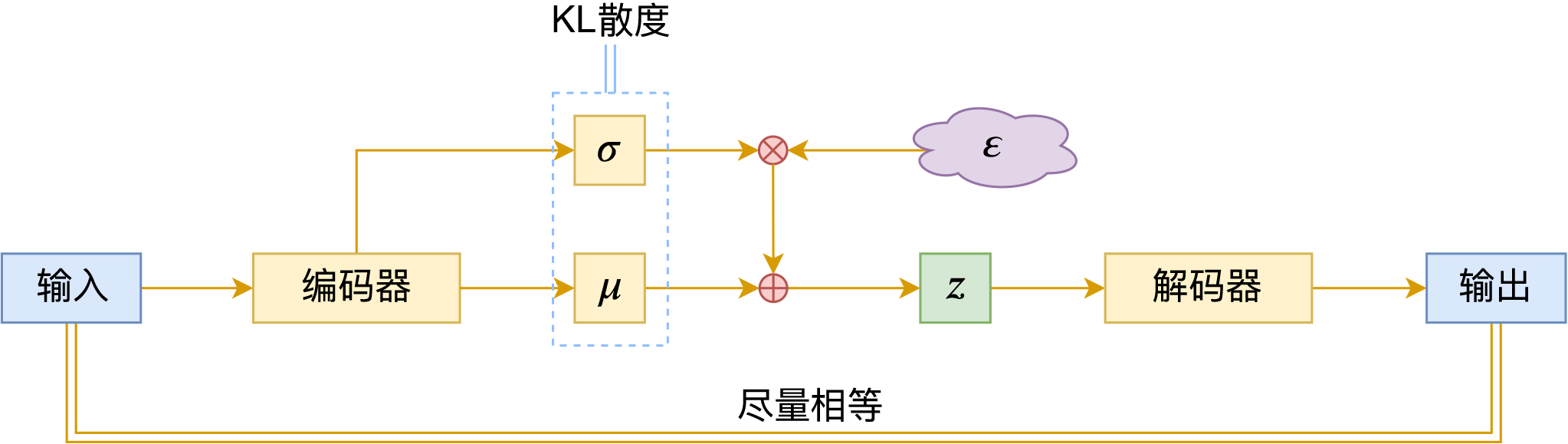
变分自编码器示意图
对于VAE来说,之前笔者有两篇比较系统的介绍:《变分自编码器(一):原来是这么一回事》和《变分自编码器(二):从贝叶斯观点出发》。后者是纯概率推导,对于不做理论研究的人来说其实没什么意义,也不一定能看得懂;前者虽然显浅一点,但也不妥,因为它是从生成模型的角度来讲的,并没有说清楚“为什么需要VAE”(说白了,VAE可以带来生成模型,但是VAE并不一定就为了生成模型),整体风格也不是特别友好。
笔者想了想,对于大多数不了解但是想用VAE的读者来说,他们应该只希望大概了解VAE的形式,然后想要知道“VAE有什么作用”、“VAE相比AE有什么区别”、“什么场景下需要VAE”等问题的答案,对于这种需求,上面两篇文章都无法很好地满足。于是笔者尝试构思了VAE的一种几何图景,试图从几何角度来描绘VAE的关键特性,在此也跟大家分享一下。
10
Jul
强大的NVAE:以后再也不能说VAE生成的图像模糊了
By 苏剑林 | 2020-07-10 | 113858位读者 | 引用昨天早上,笔者在日常刷arixv的时候,然后被一篇新出来的论文震惊了!论文名字叫做《NVAE: A Deep Hierarchical Variational Autoencoder》,顾名思义是做VAE的改进工作的,提出了一个叫NVAE的新模型。说实话,笔者点进去的时候是不抱什么希望的,因为笔者也算是对VAE有一定的了解,觉得VAE在生成模型方面的能力终究是有限的。结果,论文打开了,呈现出来的画风是这样的:

NVAE的人脸生成效果
然后笔者的第一感觉是这样的:
W!T!F! 这真的是VAE生成的效果?这还是我认识的VAE么?看来我对VAE的认识还是太肤浅了啊,以后再也不能说VAE生成的图像模糊了...
15
Sep
殊途同归的策略梯度与零阶优化
By 苏剑林 | 2020-09-15 | 57933位读者 | 引用深度学习如此成功的一个巨大原因就是基于梯度的优化算法(SGD、Adam等)能有效地求解大多数神经网络模型。然而,既然是基于梯度,那么就要求模型是可导的,但随着研究的深入,我们时常会有求解不可导模型的需求,典型的例子就是直接优化准确率、F1、BLEU等评测指标,或者在神经网络里边加入了不可导模块(比如“跳读”操作)。

Gradient
本文将简单介绍两种求解不可导的模型的有效方法:强化学习的重要方法之一策略梯度(Policy Gradient),以及干脆不需要梯度的零阶优化(Zeroth Order Optimization)。表面上来看,这是两种思路完全不一样的优化方法,但本文将进一步证明,在一大类优化问题中,其实两者基本上是等价的。
10
Oct
从动力学角度看优化算法(五):为什么学习率不宜过小?
By 苏剑林 | 2020-10-10 | 56698位读者 | 引用本文的主题是“为什么我们需要有限的学习率”,所谓“有限”,指的是不大也不小,适中即可,太大容易导致算法发散,这不难理解,但为什么太小也不好呢?一个容易理解的答案是,学习率过小需要迭代的步数过多,这是一种没有必要的浪费,因此从“节能”和“加速”的角度来看,我们不用过小的学习率。但如果不考虑算力和时间,那么过小的学习率是否可取呢?Google最近发布在Arxiv上的论文《Implicit Gradient Regularization》试图回答了这个问题,它指出有限的学习率隐式地给优化过程带来了梯度惩罚项,而这个梯度惩罚项对于提高泛化性能是有帮助的,因此哪怕不考虑算力和时间等因素,也不应该用过小的学习率。
对于梯度惩罚,本博客已有过多次讨论,在文章《对抗训练浅谈:意义、方法和思考(附Keras实现)》和《泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练》中,我们就分析了对抗训练一定程度上等价于对输入的梯度惩罚,而文章《我们真的需要把训练集的损失降低到零吗?》介绍的Flooding技巧则相当于对参数的梯度惩罚。总的来说,不管是对输入还是对参数的梯度惩罚,都对提高泛化能力有一定帮助。
21
Dec
从动力学角度看优化算法(七):SGD ≈ SVM?
By 苏剑林 | 2020-12-21 | 37600位读者 | 引用众所周知,在深度学习之前,机器学习是SVM(Support Vector Machine,支持向量机)的天下,曾经的它可谓红遍机器学习的大江南北,迷倒万千研究人员,直至今日,“手撕SVM”仍然是大厂流行的面试题之一。然而,时过境迁,当深度学习流行起来之后,第一个革的就是SVM的命,现在只有在某些特别追求效率的场景以及大厂的面试题里边,才能看到SVM的踪迹了。
峰回路转的是,最近Arxiv上的一篇论文《Every Model Learned by Gradient Descent Is Approximately a Kernel Machine》做了一个非常“霸气”的宣言:
任何由梯度下降算法学出来的模型,都是可以近似看成是一个SVM!
这结论真不可谓不“霸气”,因为它已经不只是针对深度学习了,而是只要你用梯度下降优化的,都不过是一个SVM(的近似)。笔者看了一下原论文的分析,感觉确实挺有意思也挺合理的,有助于加深我们对很多模型的理解,遂跟大家分享一下。
7
Jan
【搜出来的文本】⋅(一)从文本生成到搜索采样
By 苏剑林 | 2021-01-07 | 65446位读者 | 引用最近,笔者入了一个新坑:基于离散优化的思想做一些文本生成任务。简单来说,就是把我们要生成文本的目标量化地写下来,构建一个分布,然后搜索这个分布的最大值点或者从这个分布中进行采样,这个过程通常不需要标签数据的训练。由于语言是离散的,因此梯度下降之类的连续函数优化方法不可用,并且由于这个分布通常没有容易采样的形式,直接采样也不可行,因此需要一些特别设计的采样算法,比如拒绝采样(Rejection Sampling)、MCMC(Markov Chain Monte Carlo)、MH采样(Metropolis-Hastings Sampling)、吉布斯采样(Gibbs Sampling),等等。
有些读者可能会觉得有些眼熟,似乎回到了让人头大的学习LDA(Latent Dirichlet Allocation)的那些年?没错,上述采样算法其实也是理解LDA模型的必备基础。本文我们就来回顾这些形形色色的采样算法,它们将会出现在后面要介绍的丰富的文本生成应用中。
14
Jan
【搜出来的文本】⋅(二)从MCMC到模拟退火
By 苏剑林 | 2021-01-14 | 53439位读者 | 引用在上一篇文章中,我们介绍了“受限文本生成”这个概念,指出可以通过量化目标并从中采样的方式来无监督地完成某些带条件的文本生成任务。同时,上一篇文章还介绍了“重要性采样”和“拒绝采样”两个方法,并且指出对于高维空间而言,它们所依赖的易于采样的分布往往难以设计,导致它们难以满足我们的采样需求。
此时,我们就需要引入采样界最重要的算法之一“Markov Chain Monte Carlo(MCMC)”方法了,它将马尔可夫链和蒙特卡洛方法结合起来,使得(至少理论上是这样)我们从很多高维分布中进行采样成为可能,也是后面我们介绍的受限文本生成应用的重要基础算法之一。本文试图对它做一个基本的介绍。
马尔可夫链
马尔可夫链实际上就是一种“无记忆”的随机游走过程,它以转移概率$p(\boldsymbol{y}\leftarrow\boldsymbol{x})$为基础,从一个初始状态$\boldsymbol{x}_0$出发,每一步均通过该转移概率随机选择下一个状态,从而构成随机状态列$\boldsymbol{x}_0, \boldsymbol{x}_1, \boldsymbol{x}_2, \cdots, \boldsymbol{x}_t, \cdots $,我们希望考察对于足够大的步数$t$,$\boldsymbol{x}_t$所服从的分布,也就是该马尔可夫链的“平稳分布”。
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 46831位读者 | 引用标准Attention的$\mathcal{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
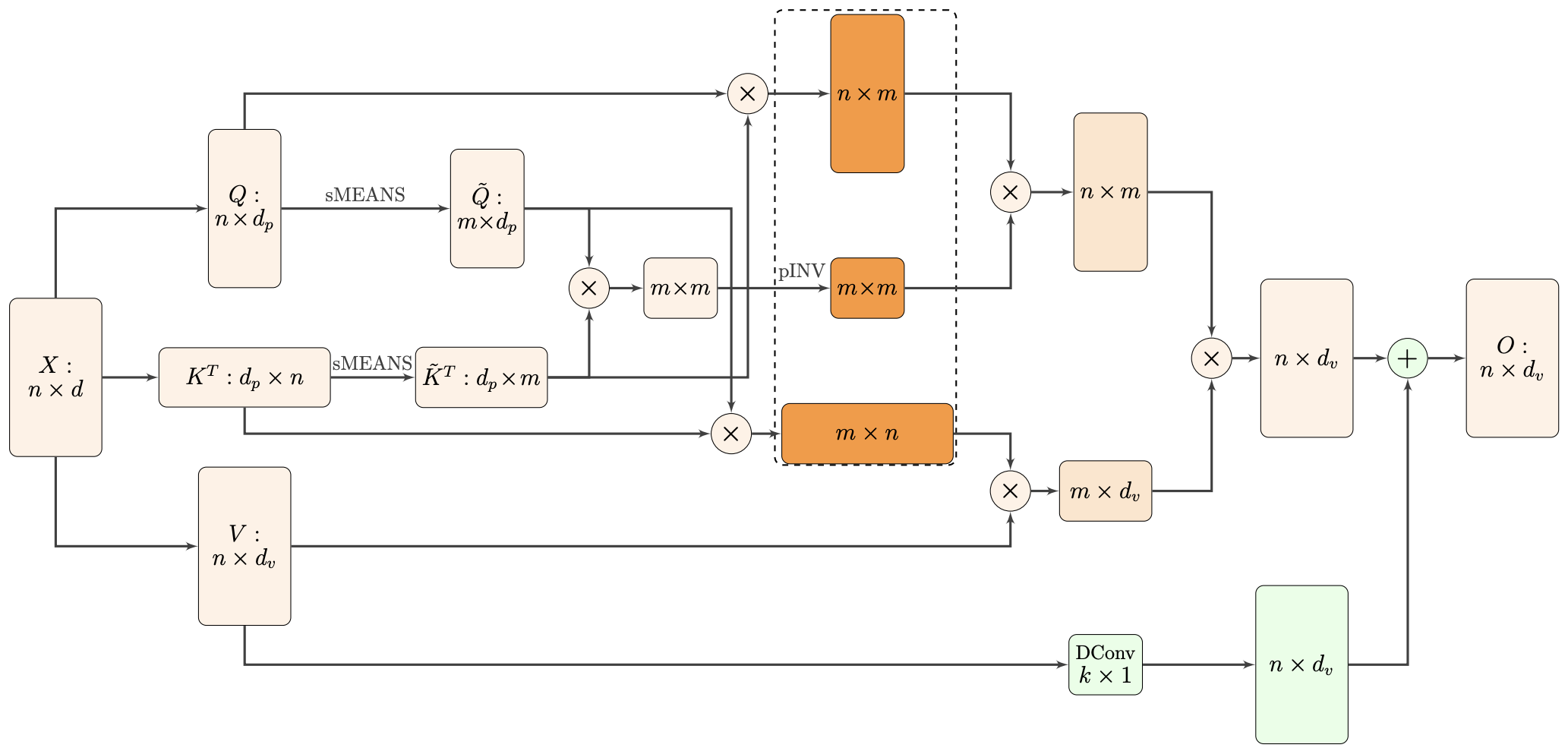
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。

最近评论