






18
Nov
Adam的epsilon如何影响学习率的Scaling Law?
By 苏剑林 | 2024-11-18 | 23281位读者 | 引用上一篇文章《当Batch Size增大时,学习率该如何随之变化?》我们从多个角度讨论了学习率与Batch Size之间的缩放规律,其中对于Adam优化器我们采用了SignSGD近似,这是分析Adam优化器常用的手段。那么一个很自然的问题就是:用SignSGD来近似Adam究竟有多科学呢?
我们知道,Adam优化器的更新量分母会带有一个ϵ,初衷是预防除零错误,所以其值通常很接近于零,以至于我们做理论分析的时候通常选择忽略掉它。然而,当前LLM的训练尤其是低精度训练,我们往往会选择偏大的ϵ,这导致在训练的中、后期ϵ往往已经超过梯度平方大小,所以ϵ的存在事实上已经不可忽略。
因此,这篇文章我们试图探索ϵ如何影响Adam的学习率与Batch Size的Scaling Law,为相关问题提供一个参考的计算方案。
22
Nov
生成扩散模型漫谈(二十六):基于恒等式的蒸馏(下)
By 苏剑林 | 2024-11-22 | 29497位读者 | 引用继续回到我们的扩散系列。在《生成扩散模型漫谈(二十五):基于恒等式的蒸馏(上)》中,我们介绍了SiD(Score identity Distillation),这是一种不需要真实数据、也不需要从教师模型采样的扩散模型蒸馏方案,其形式类似GAN,但有着比GAN更好的训练稳定性。
SiD的核心是通过恒等变换来为学生模型构建更好的损失函数,这一点是开创性的,同时也遗留了一些问题。比如,SiD对损失函数的恒等变换是不完全的,如果完全变换会如何?如何从理论上解释SiD引入的λ的必要性?上个月放出的《Flow Generator Matching》(简称FGM)成功从更本质的梯度角度解释了λ=0.5的选择,而受到FGM启发,笔者则进一步发现了λ=1的一种解释。
接下来我们将详细介绍SiD的上述理论进展。
10
Dec
Muon优化器赏析:从向量到矩阵的本质跨越
By 苏剑林 | 2024-12-10 | 45872位读者 | 引用随着LLM时代的到来,学术界对于优化器的研究热情似乎有所减退。这主要是因为目前主流的AdamW已经能够满足大多数需求,而如果对优化器“大动干戈”,那么需要巨大的验证成本。因此,当前优化器的变化,多数都只是工业界根据自己的训练经验来对AdamW打的一些小补丁。
不过,最近推特上一个名为“Muon”的优化器颇为热闹,它声称比AdamW更为高效,且并不只是在Adam基础上的“小打小闹”,而是体现了关于向量与矩阵差异的一些值得深思的原理。本文让我们一起赏析一番。
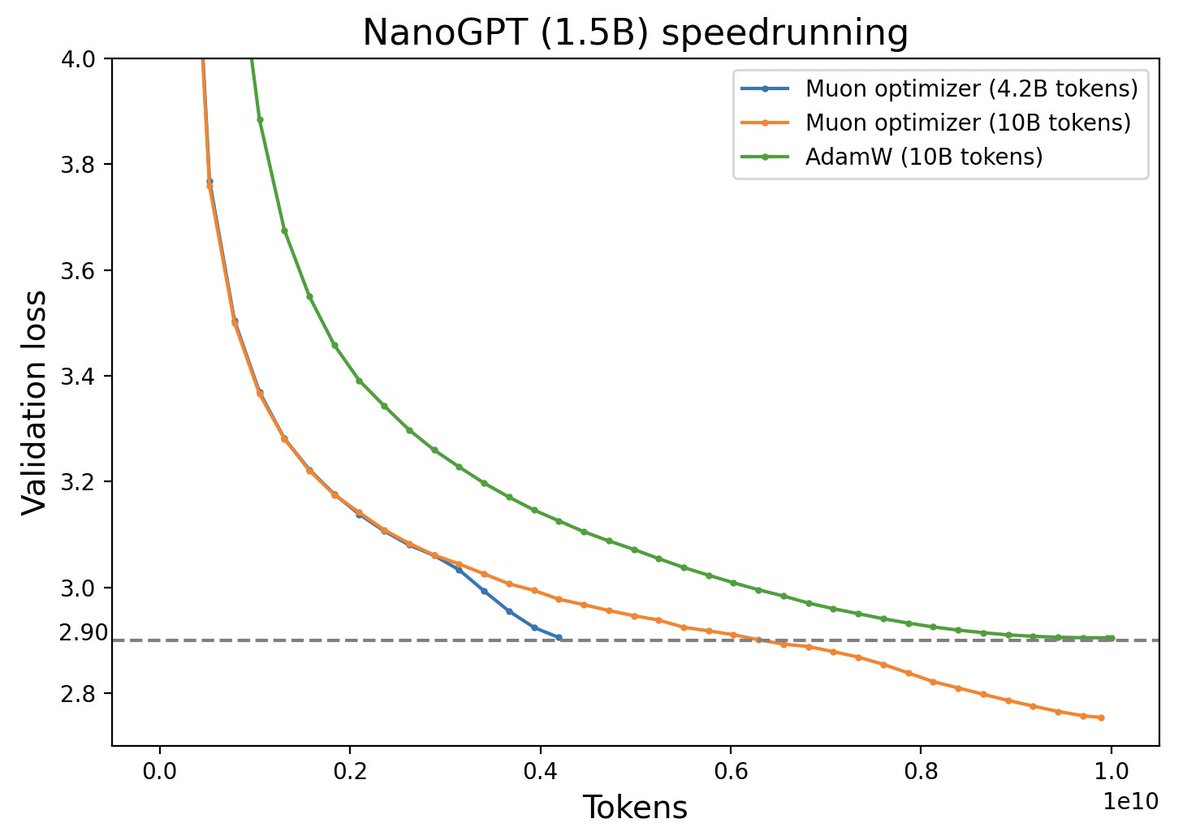
Muon与AdamW效果对比(来源:推特@Yuchenj_UW)
15
Dec
生成扩散模型漫谈(二十七):将步长作为条件输入
By 苏剑林 | 2024-12-15 | 32147位读者 | 引用这篇文章我们再次聚焦于扩散模型的采样加速。众所周知,扩散模型的采样加速主要有两种思路,一是开发更高效的求解器,二是事后蒸馏。然而,据笔者观察,除了上两篇文章介绍过的SiD外,这两种方案都鲜有能将生成步数降低到一步的结果。虽然SiD能做到单步生成,但它需要额外的蒸馏成本,并且蒸馏过程中用到了类似GAN的交替训练过程,总让人感觉差点意思。
本文要介绍的是《One Step Diffusion via Shortcut Models》,其突破性思想是将生成步长也作为扩散模型的条件输入,然后往训练目标中加入了一个直观的正则项,这样就能直接稳定训练出可以单步生成模型,可谓简单有效的经典之作。
ODE扩散
原论文的结论是基于ODE式扩散模型的,而对于ODE式扩散的理论基础,我们在本系列的(六)、(十二)、(十四)、(十五)、(十七)等博客中已经多次介绍,其中最简单的一种理解方式大概是(十七)中的ReFlow视角,下面我们简单重复一下。
2
Jan
为什么梯度裁剪的默认模长是1?
By 苏剑林 | 2025-01-02 | 42706位读者 | 引用我们知道,梯度裁剪(Gradient Clipping)是让模型训练更加平稳的常用技巧。常用的梯度裁剪是根据所有参数的梯度总模长来对梯度进行裁剪,其运算可以表示为
clip(g,τ)={g,‖g‖≤ττ‖g‖g,‖g‖>τ
这样一来,clip(g,τ)保持跟g相同的方向,但模长不超过τ。注意这里的‖g‖是整个模型所有的参数梯度放在一起视为单个向量所算的模长,也就是所谓的Global Gradient Norm。
不知道大家有没有留意到一个细节:不管是数百万参数还是数百亿参数的模型,τ的取值在很多时候都是1。这意味着什么呢?是单纯地复用默认值,还是背后隐含着什么深刻的原理呢?
28
Jan
三个球的交点坐标(三球交会定位)
By 苏剑林 | 2025-01-28 | 19423位读者 | 引用前几天笔者在思考一个问题时,联想到了三球交点问题,即给定三个球的球心坐标和半径,求这三个球的交点坐标。按理说这是一个定义清晰且简明的问题,并且具有鲜明的应用背景(比如卫星定位),应该早已有人给出“标准答案”才对。但笔者搜了一圈,发现不管是英文资料还是中文资料,都没有找到标准的求解流程。
当然,这并不是说这个问题有多难以至于没人能求解出来,事实上这是个早已被人解决的经典问题,笔者只是意外于似乎没有人以一种可读性比较好的方式将求解过程写到网上,所以本文试图补充这一点。
特殊情形
首先,设三个球的方程分别是
球1:(x−o1)2=r21球2:(x−o2)2=r22球3:(x−o3)2=r23
18
Dec
生成扩散模型漫谈(二十八):分步理解一致性模型
By 苏剑林 | 2024-12-18 | 31699位读者 | 引用书接上文,在《生成扩散模型漫谈(二十七):将步长作为条件输入》中,我们介绍了加速采样的Shortcut模型,其对比的模型之一就是“一致性模型(Consistency Models)”。事实上,早在《生成扩散模型漫谈(十七):构建ODE的一般步骤(下)》介绍ReFlow时,就有读者提到了一致性模型,但笔者总感觉它更像是实践上的Trick,理论方面略显单薄,所以兴趣寥寥。
不过,既然我们开始关注扩散模型加速采样方面的进展,那么一致性模型就是一个绕不开的工作。因此,趁着这个机会,笔者在这里分享一下自己对一致性模型的理解。
熟悉配方
还是熟悉的配方,我们的出发点依旧是ReFlow,因为它大概是ODE式扩散最简单的理解方式。设x0∼p0(x0)是目标分布的真实样本,x1∼p1(x1)是先验分布的随机噪声,xt=(1−t)x0+tx1是加噪样本,那么ReFlow的训练目标是:
25
Dec
从谱范数梯度到新式权重衰减的思考
By 苏剑林 | 2024-12-25 | 22960位读者 | 引用在文章《Muon优化器赏析:从向量到矩阵的本质跨越》中,我们介绍了一个名为“Muon”的新优化器,其中一个理解视角是作为谱范数正则下的最速梯度下降,这似乎揭示了矩阵参数的更本质的优化方向。众所周知,对于矩阵参数我们经常也会加权重衰减(Weight Decay),它可以理解为F范数平方的梯度,那么从Muon的视角看,通过谱范数平方的梯度来构建新的权重衰减,会不会能起到更好的效果呢?
那么问题来了,谱范数的梯度或者说导数长啥样呢?用它来设计的新权重衰减又是什么样的?接下来我们围绕这些问题展开。
基础回顾
谱范数(Spectral Norm),又称“2范数”,是最常用的矩阵范数之一,相比更简单的F范数(Frobenius Norm),它往往能揭示一些与矩阵乘法相关的更本质的信号,这是因为它定义上就跟矩阵乘法相关:对于矩阵参数W∈Rn×m,它的谱范数定义为

最近评论