






26
Apr
中文任务还是SOTA吗?我们给SimCSE补充了一些实验
By 苏剑林 | 2021-04-26 | 321989位读者 |今年年初,笔者受到BERT-flow的启发,构思了成为“BERT-whitening”的方法,并一度成为了语义相似度的新SOTA(参考《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》,论文为《Whitening Sentence Representations for Better Semantics and Faster Retrieval》)。然而“好景不长”,在BERT-whitening提交到Arxiv的不久之后,Arxiv上出现了至少有两篇结果明显优于BERT-whitening的新论文。
第一篇是《Generating Datasets with Pretrained Language Models》,这篇借助模板从GPT2_XL中无监督地构造了数据对来训练相似度模型,个人认为虽然有一定的启发而且效果还可以,但是复现的成本和变数都太大。另一篇则是本文的主角《SimCSE: Simple Contrastive Learning of Sentence Embeddings》,它提出的SimCSE在英文数据上显著超过了BERT-flow和BERT-whitening,并且方法特别简单~
那么,SimCSE在中文上同样有效吗?能大幅提高中文语义相似度的效果吗?本文就来做些补充实验。
SimCSE #
首先,简单对SimCSE做个介绍。事实上,SimCSE可以看成是SimBERT的简化版(关于SimBERT请阅读《鱼与熊掌兼得:融合检索和生成的SimBERT模型》),它简化的部分如下:
1、SimCSE去掉了SimBERT的生成部分,仅保留检索模型;
2、由于SimCSE没有标签数据,所以把每个句子自身视为相似句传入。
说白了,本质上来说就是(自己,自己)作为正例、(自己,别人)作为负例来训练对比学习模型。当然,事实上还没那么简单,如果仅仅是完全相同的两个样本作为正例,那么泛化能力会大打折扣。一般来说,我们会使用一些数据扩增手段,让正例的两个样本有所差异,但是在NLP中如何做数据扩增本身又是一个难搞的问题,SimCSE则提出了一个极为简单的方案:直接把Dropout当作数据扩增!
具体来说,$N$个句子经过带Dropout的Encoder得到向量$\boldsymbol{h}^{(0)}_1,\boldsymbol{h}^{(0)}_2,\cdots,\boldsymbol{h}^{(0)}_N$,然后让这批句子再重新过一遍Encoder(这时候是另一个随机Dropout)得到向量$\boldsymbol{h}^{(1)}_1,\boldsymbol{h}^{(1)}_2,\cdots,\boldsymbol{h}^{(1)}_N$,我们可以将$(\boldsymbol{h}^{(0)}_i,\boldsymbol{h}^{(1)}_i)$视为一对(略有不同的)正例了,那么训练目标为:
\begin{equation}-\sum_{i=1}^N\sum_{\alpha=0,1}\log \frac{e^{\cos(\boldsymbol{h}^{(\alpha)}_i, \boldsymbol{h}^{(1-\alpha)}_i)/\tau}}{\sum\limits_{j=1,j\neq i}^N e^{\cos(\boldsymbol{h}^{(\alpha)}_i, \boldsymbol{h}^{(\alpha)}_j)/\tau} + \sum\limits_j^N e^{\cos(\boldsymbol{h}^{(\alpha)}_i, \boldsymbol{h}^{(1-\alpha)}_j)/\tau}}\end{equation}
英文效果 #
原论文的(英文)实验还是颇为丰富的,读者可以仔细阅读原文。但是要注意的是,原论文正文表格的评测指标跟BERT-flow、BERT-whitening的不一致,指标一致的表格在附录:
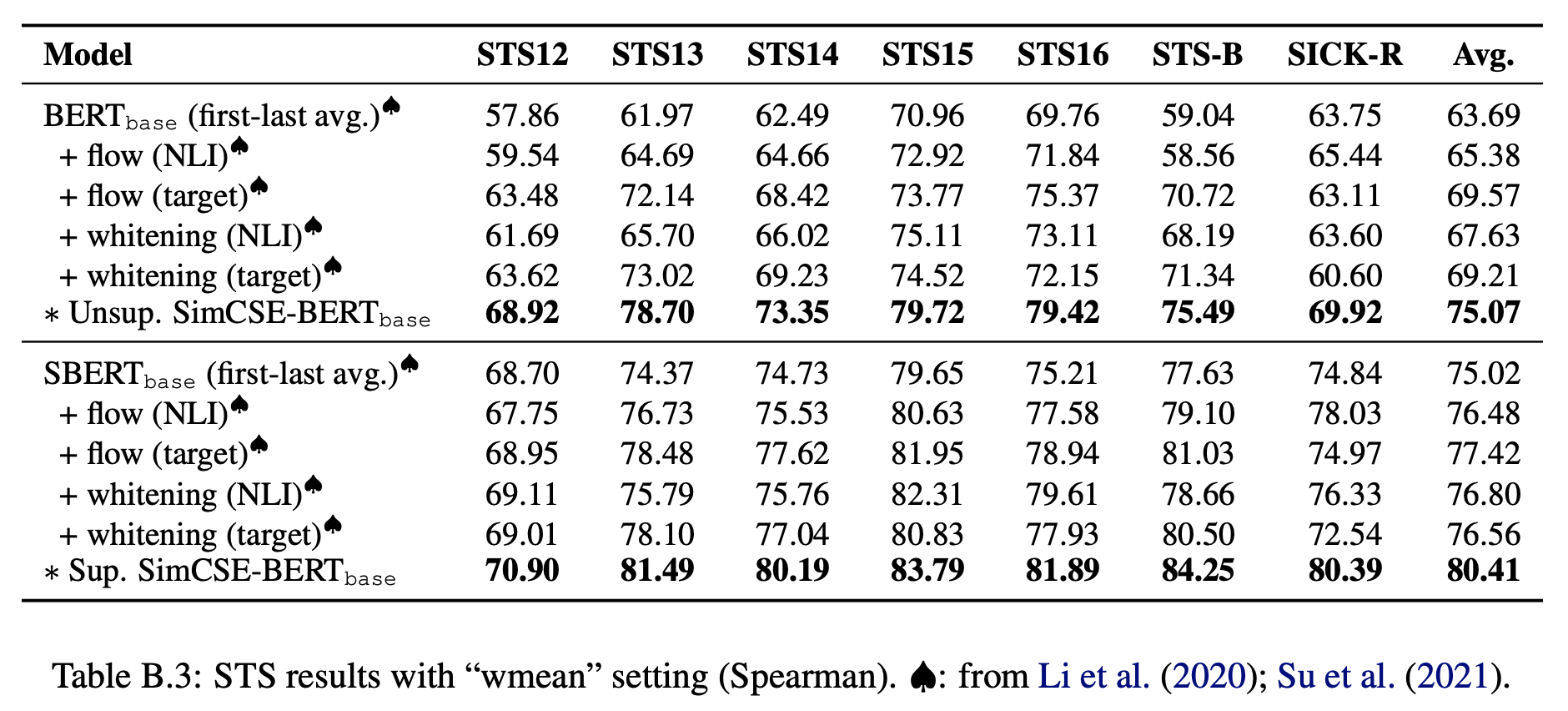
SimCSE与BERT-flow、BERT-whitening的效果对比
不管怎样比,SimCSE还是明显优于BERT-flow和BERT-whitening的。那么SimCSE的这个优势是不是普遍的呢?在中文上有没有这个优势呢?我们马上就来做实验。
实验配置 #
我们的中文实验基本与《无监督语义相似度哪家强?我们做了个比较全面的评测》对齐,包括之前测试的5个任务、4中Pooling以及所有base、small、tiny版的模型,large没有跑是因为相同配置下large模型OOM了。
经过调参,笔者发现中文任务上SimCSE的最优参数跟原论文中的不完全一致,具体区别如下:
1、原论文batch_size=512,这里是batch_size=64(实在跑不起这么壕的batch_size);
2、原论文的学习率是5e-5,这里是1e-5;
3、原论文的最优dropout比例是0.1,这里是0.3;
4、原论文的无监督SimCSE是在额外数据上训练的,这里直接随机选了1万条任务数据训练;
5、原文无监督训练的时候还带了个MLM任务,这里只有SimCSE训练。
最后一点再说明一下,原论文的无监督SimCSE是从维基百科上挑了100万个句子进行训练的,至于中文实验,为了实验上的方便以及对比上的公平,直接用任务数据训练(只用了句子,没有用标签,还是无监督的)。不过除了PAWSX之外,其他4个任务都不需要全部数据都拿来训练,经过测试,只需要随机选1万个训练样本训练一个epoch即可训练到最优效果(更多样本更少样本效果都变差)。
中文效果 #
SimCSE的所有中文实验结果如下:
$$\small{\begin{array}{l|ccccc}
\hline
& \text{ATEC} & \text{BQ} & \text{LCQMC} & \text{PAWSX} & \text{STS-B} \\
\hline
\text{BERT}\text{-P1} & 16.59 / 20.61 / \color{green}{33.14} & 29.35 / 25.76 / \color{green}{50.67} & 41.71 / 48.92 / \color{green}{69.99} & 15.15 / 17.03 / \color{red}{12.95} & 34.65 / 61.19 / \color{green}{69.04} \\
\text{BERT}\text{-P2} & 9.46 / 22.16 / \color{green}{25.18} & 16.97 / 18.97 / \color{green}{41.19} & 28.42 / 49.61 / \color{green}{56.45} & 13.93 / 16.08 / \color{red}{12.46} & 21.66 / 60.75 / \color{red}{57.63} \\
\text{BERT}\text{-P3} & 20.79 / 18.27 / \color{green}{32.89} & 33.08 / 22.58 / \color{green}{49.58} & 59.22 / 60.12 / \color{green}{71.83} & 16.68 / 18.37 / \color{red}{14.47} & 57.48 / 63.97 / \color{green}{70.08} \\
\text{BERT}\text{-P4} & 24.51 / 27.00 / \color{green}{31.96} & 38.81 / 32.29 / \color{green}{48.40} & 64.75 / 64.75 / \color{green}{71.49} & 15.12 / 17.80 / \color{red}{16.01} & 61.66 / 69.45 / \color{green}{70.03} \\
\hline
\text{RoBERTa}\text{-P1} & 24.61 / 29.59 / \color{green}{32.23} & 40.54 / 28.95 / \color{green}{50.61} & 70.55 / 70.82 / \color{green}{74.22} & 16.23 / 17.99 / \color{red}{12.25} & 66.91 / 69.19 / \color{green}{71.13} \\
\text{RoBERTa}\text{-P2} & 20.61 / 28.91 / \color{red}{20.07} & 31.14 / 27.48 / \color{green}{39.92} & 65.43 / 70.62 / \color{red}{62.65} & 15.71 / 17.30 / \color{red}{12.00} & 59.50 / 70.77 / \color{red}{61.49} \\
\text{RoBERTa}\text{-P3} & 26.94 / 29.94 / \color{green}{32.66} & 40.71 / 30.95 / \color{green}{51.03} & 66.80 / 68.00 / \color{green}{73.15} & 16.08 / 19.01 / \color{red}{16.47} & 61.67 / 66.19 / \color{green}{70.14} \\
\text{RoBERTa}\text{-P4} & 27.94 / 28.33 / \color{green}{32.40} & 43.09 / 33.49 / \color{green}{49.78} & 68.43 / 67.86 / \color{green}{72.74} & 15.02 / 17.91 / \color{red}{16.39} & 64.09 / 69.74 / \color{green}{70.11} \\
\hline
\text{NEZHA}\text{-P1} & 17.39 / 18.83 / \color{green}{32.14} & 29.63 / 21.94 / \color{green}{46.08} & 40.60 / 50.52 / \color{green}{60.38} & 14.90 / 18.15 / \color{red}{16.60} & 35.84 / 60.84 / \color{green}{68.50} \\
\text{NEZHA}\text{-P2} & 10.96 / 23.08 / \color{red}{15.70} & 17.38 / 28.81 / \color{green}{32.20} & 22.66 / 49.12 / \color{red}{21.07} & 13.45 / 18.05 / \color{red}{12.68} & 21.16 / 60.11 / \color{red}{43.35} \\
\text{NEZHA}\text{-P3} & 23.70 / 21.93 / \color{green}{31.47} & 35.44 / 22.44 / \color{green}{46.69} & 60.94 / 62.10 / \color{green}{69.65} & 18.35 / 21.72 / \color{red}{18.17} & 60.35 / 68.57 / \color{green}{70.68} \\
\text{NEZHA}\text{-P4} & 27.72 / 25.31 / \color{green}{30.26} & 44.18 / 31.47 / \color{green}{46.57} & 65.16 / 66.68 / \color{green}{67.21} & 13.98 / 16.66 / \color{red}{14.41} & 61.94 / 69.55 / \color{red}{68.18} \\
\hline
\text{WoBERT}\text{-P1} & 23.88 / 22.45 / \color{green}{32.66} & 43.08 / 32.52 / \color{green}{49.13} & 68.56 / 67.89 / \color{green}{72.99} & 18.15 / 19.92 / \color{red}{12.36} & 64.12 / 66.53 / \color{green}{70.00} \\
\text{WoBERT}\text{-P2} & \text{-} & \text{-} & \text{-} & \text{-} & \text{-} \\
\text{WoBERT}\text{-P3} & 24.62 / 22.74 / \color{green}{34.03} & 40.64 / 28.12 / \color{green}{49.77} & 64.89 / 65.22 / \color{green}{72.44} & 16.83 / 20.56 / \color{red}{14.55} & 59.43 / 66.57 / \color{green}{70.96} \\
\text{WoBERT}\text{-P4} & 25.97 / 27.24 / \color{green}{33.67} & 42.37 / 32.34 / \color{green}{49.09} & 66.53 / 65.62 / \color{green}{71.74} & 15.54 / 18.85 / \color{red}{14.00} & 61.37 / 68.11 / \color{green}{70.00} \\
\hline
\text{RoFormer}\text{-P1} & 24.29 / 26.04 / \color{green}{32.33} & 41.91 / 28.13 / \color{green}{49.13} & 64.87 / 60.92 / \color{green}{71.61} & 20.15 / 23.08 / \color{red}{15.25} & 59.91 / 66.96 / \color{green}{69.45} \\
\text{RoFormer}\text{-P2} & \text{-} & \text{-} & \text{-} & \text{-} & \text{-} \\
\text{RoFormer}\text{-P3} & 24.09 / 28.51 / \color{green}{34.23} & 39.09 / 34.92 / \color{green}{50.01} & 63.55 / 63.85 / \color{green}{72.01} & 16.53 / 18.43 / \color{red}{15.25} & 58.98 / 55.30 / \color{green}{71.44} \\
\text{RoFormer}\text{-P4} & 25.92 / 27.38 / \color{green}{34.10} & 41.75 / 32.36 / \color{green}{49.58} & 66.18 / 65.45 / \color{green}{71.84} & 15.30 / 18.36 / \color{red}{15.17} & 61.40 / 68.02 / \color{green}{71.40} \\
\hline
\text{SimBERT}\text{-P1} & 38.50 / 23.64 / \color{green}{36.98} & 48.54 / 31.78 / \color{green}{51.47} & 76.23 / 75.05 / \color{red}{74.87} & 15.10 / 18.49 / \color{red}{12.66} & 74.14 / 73.37 / \color{green}{75.12} \\
\text{SimBERT}\text{-P2} & 38.93 / 27.06 / \color{green}{37.00} & 49.93 / 35.38 / \color{green}{50.33} & 75.56 / 73.45 / \color{red}{72.61} & 14.52 / 18.51 / \color{green}{19.72} & 73.18 / 73.43 / \color{green}{75.13} \\
\text{SimBERT}\text{-P3} & 36.50 / 31.32 / \color{green}{37.81} & 45.78 / 29.17 / \color{green}{51.24} & 74.42 / 73.79 / \color{green}{73.85} & 15.33 / 18.39 / \color{red}{12.48} & 67.31 / 70.70 / \color{green}{73.18} \\
\text{SimBERT}\text{-P4} & 33.53 / 29.04 / \color{green}{36.93} & 45.28 / 34.70 / \color{green}{50.09} & 73.20 / 71.22 / \color{green}{73.42} & 14.16 / 17.32 / \color{red}{16.59} & 66.98 / 70.55 / \color{green}{72.64} \\
\hline
\text{SimBERT}_{\text{small}}\text{-P1} & 30.68 / 27.56 / \color{green}{31.16} & 43.41 / 30.89 / \color{green}{44.80} & 74.73 / 73.21 / \color{green}{74.32} & 15.89 / 17.96 / \color{red}{14.69} & 70.54 / 71.39 / \color{red}{69.85} \\
\text{SimBERT}_{\text{small}}\text{-P2} & 31.00 / 29.14 / \color{green}{30.76} & 43.76 / 36.86 / \color{green}{45.50} & 74.21 / 73.14 / \color{green}{74.55} & 16.17 / 18.12 / \color{red}{15.18} & 70.10 / 71.40 / \color{red}{69.18} \\
\text{SimBERT}_{\text{small}}\text{-P3} & 30.03 / 21.24 / \color{green}{30.07} & 43.72 / 31.69 / \color{green}{44.27} & 72.12 / 70.27 / \color{green}{71.21} & 16.93 / 21.68 / \color{red}{12.10} & 66.55 / 66.11 / \color{red}{64.95} \\
\text{SimBERT}_{\text{small}}\text{-P4} & 29.52 / 28.41 / \color{green}{28.56} & 43.52 / 36.56 / \color{green}{43.38} & 70.33 / 68.75 / \color{red}{68.35} & 15.39 / 21.57 / \color{red}{14.47} & 64.73 / 68.12 / \color{red}{63.23} \\
\hline
\text{SimBERT}_{\text{tiny}}\text{-P1} & 30.51 / 24.67 / \color{green}{30.04} & 44.25 / 31.75 / \color{green}{43.89} & 74.27 / 72.25 / \color{green}{73.47} & 16.01 / 18.07 / \color{red}{12.51} & 70.11 / 66.39 / \color{green}{70.11} \\
\text{SimBERT}_{\text{tiny}}\text{-P2} & 30.01 / 27.66 / \color{green}{29.37} & 44.47 / 37.33 / \color{green}{44.04} & 73.98 / 72.31 / \color{green}{72.93} & 16.55 / 18.15 / \color{red}{13.73} & 70.35 / 70.88 / \color{red}{69.63} \\
\text{SimBERT}_{\text{tiny}}\text{-P3} & 28.47 / 19.68 / \color{green}{28.08} & 42.04 / 29.49 / \color{green}{41.21} & 69.16 / 66.99 / \color{green}{69.85} & 16.18 / 20.11 / \color{red}{12.21} & 64.41 / 66.72 / \color{red}{64.62} \\
\text{SimBERT}_{\text{tiny}}\text{-P4} & 27.77 / 27.67 / \color{red}{26.25} & 41.76 / 37.02 / \color{green}{41.62} & 67.55 / 65.66 / \color{green}{67.34} & 15.06 / 20.49 / \color{red}{13.87} & 62.92 / 66.77 / \color{red}{60.80} \\
\hline
\end{array}}$$
其中每个单元的数据是“a/b/c”的形式,a是不加任何处理的原始结果,b是BERT-whitening的结果(没有降维),c则是SimCSE的结果,如果c > b,那么c显示为绿色,否则为红色,也就是说绿色越多,说明SimCSE比BERT-whitening好得越多。关于其他实验细节,可以看原代码以及《无监督语义相似度哪家强?我们做了个比较全面的评测》。
注意由于又有Dropout,训练时又是随机采样1万个样本,因此结果具有一定的随机性,重跑代码指标肯定会有波动,请读者知悉。
一些结论 #
从实验结果可以看出,除了PAWSX这个“异类”外,SimCSE相比BERT-whitening确实有压倒性优势,有些任务还能好10个点以上,在BQ上SimCSE还比有监督训练过的SimBERT要好,而且像SimBERT这种已经经过监督训练的模型还能获得进一步的提升,这些都说明确实强大。(至于PAWSX为什么“异”,文章《无监督语义相似度哪家强?我们做了个比较全面的评测》已经做过简单分析。)
同时,我们还可以看出在SimCSE之下,在BERT-flow和BERT-whitening中表现较好的first-last-avg这种Pooling方式已经没有任何优势了,反而较好的是直接取[CLS]向量,但让人意外的是,Pooler(取[CLS]的基础上再加个Dense)的表现又比较差,真让人迷惘~
由于BERT-whiteing只是一个线性变换,所以笔者还实验了单靠SimCSE是否能复现这个线性变换的效果。具体来说,就是固定Encoder的权重,然后接一个不加激活函数的Dense层,然后以SimCSE为目标,只训练最后接的Dense层。结果发现这种情况下的SimCSE并不如BERT-whitening。那就意味着,SimCSE要有效必须要把Encoder微调才行,同时也说明BERT-whitening可能包含了SimCSE所没有东西的,也许两者以某种方式进行结合会取得更好的效果(构思中...)。
相关工作 #
简单调研了一下,发现“自己与自己做正样本”这个思想的工作,最近都出现好几篇论文了,除了SimCSE之外,还有《Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks》、《Semantic Re-tuning with Contrastive Tension》都是极度相似的。其实类似的idea笔者也想过,只不过没想到真的能work(就没去做实验了),也没想到关键点是Dropout,看来还是得多多实验啊~
本文小结 #
本文分享了笔者在SimCSE上的中文实验,结果表明不少任务上SimCSE确实相当优秀,能明显优于BERT-whiteining。
转载到请包括本文地址:https://spaces.ac.cn/archives/8348
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Apr. 26, 2021). 《中文任务还是SOTA吗?我们给SimCSE补充了一些实验 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8348
@online{kexuefm-8348,
title={中文任务还是SOTA吗?我们给SimCSE补充了一些实验},
author={苏剑林},
year={2021},
month={Apr},
url={\url{https://spaces.ac.cn/archives/8348}},
}

April 26th, 2021
苏神效率好高啊 赞赞
另外有个问题再跟苏神确认,实验配置第4点中直接选用任务数据,那正例不是数据自身,而是监督标签为正的数据对是吧?
肯定不是啊,用了任务数据中的句子,没有用标签。
哦哦 了解了~
April 26th, 2021
苏神,最后一段错别字 浮现 hhh
谢谢,已经修正。
April 26th, 2021
苏神,问个问题,你一个样本过两遍encoder, 训练的时候是怎么实现的呀?
一个batch内出现两次不就行了?
April 26th, 2021
simcse_loss 实现的实在是,妙啊,学习了。
simcse_loss 里的: y_true 是 batch 样本(idxs_1) 和 batch 打乱(idxs_2) 做相似计算,而 y_pred 计算相似时是 y_pred * transpose(y_pred) ,为啥这儿没有像 idxs_2 那样将 transpose(y_pred) 变换顺序呢?
认真理解y_true最终结果是什么。
直接看看simbert的那篇博文里样本的label,就明白了y_true到底是什么了,y_pred应该就是计算的各个句子的CLS向量
y_pred是两两的相似度构成的相似度矩阵。
同佩服这个simcse_loss的实现,充分利用了已有的交叉熵实现
April 28th, 2021
苏神,写的非常棒,有两个疑问,(1)一个batch内,dropout不是一样的吗?不同batch,dropout才可能不一样.(2)loss计算的时候,同一句话放两次,那计算得到的similarities矩阵对角线就是自身和自身,那这个样本对的loss是怎么理解,看代码是减去了一个1e12,后面又乘以了个20?期待苏神解答,非常感谢@苏剑林|comment-16236
回答下第一个问题,一个batch内的dropout是不一样的,这个自己可以做下实验试试
(1)默认情况下,同一个batch内,不同样本的dropout是不一样的,相当于:
x * np.random.binomial(1, p=1-p, size=x.shape) / (1 - p)
(2)你认真看$(1)$式,有个$\tau$,原论文也有,默认是$\tau=0.05$,相当于乘以20。不scale是不行的,因为cos的范围是-1~1,直接softmax的话loss会降不下去。
明白了,非常感谢
April 29th, 2021
你好,请问一下,“直接用任务数据训练(只用了句子,没有用标签,还是无监督的)”,SimBERT过程也是这样的吗?是先用百度知道带标签的数据训练得到了SimBERT(https://github.com/ZhuiyiTechnology/simbert)模型,然后在此基础上再进行“直接用任务数据训练(只用了句子,没有用标签,还是无监督的)”,我的理解正确吗?
是的
有个问题,标签是相似、不相似这些吧,SimBERT可以不要这个信息训练吗?
SimBERT只要相似标签,也就是说相似句组来训练。
那这样的话SimBERT是有监督的吧,难道无监督的SimCSE比有监督的SimBERT效果还好?是我哪里理解有问题吗?
SimBERT一直都是有监督的,或者说弱监督的。
如果你说的是本文中SimBERT那几行结果,比如“48.54/31.78/51.47”,这里SimCSE比SimBERT好是指“在SimBERT的基础上进行SimCSE训练后的效果”比不加改动的SimBERT好。
懂了,感谢苏神
April 29th, 2021
苏神,有尝试过先SimCSE再whitening的效果吗,毕竟whitening降维的功能太实用了
粗暴地试了下(直接加), 在 ATEC 上
\begin{array} {|r|r|}
\hline Data & simcse & +whitening-Dim768 & +whitening-Dim384 \\
\hline ATEC-train & 0.2938195925 & 0.2571858094 & 0.3123321760 \\
\hline ATEC-valid & 0.3081254900 & 0.2611324475 & 0.3071958990 \\
\hline ATEC-test & 0.2846038101 & 0.2502007229 & 0.3042017528 \\
\hline avg & 0.2955162975 & 0.2561729932 & 0.3079099426 \\
\hline w-avg & 0.2948130086 & 0.2565928083 & 0.3097429706 \\
\hline
\end{array}
感谢你的实验,不过你这个simcse有点低呀~
我还没测过,直接上可能没作用。
看了你的白化操作(https://kexue.fm/archives/8069)那篇,我的理解是這個操作就是把Bert 輸出的句向量轉換成平均為0,標準差為1的向量,那麼可不可以用 Batch Normalization 達到這個目標呢?就是在Bert 的輸出接上BN層,讓他近似的輸出平均為0,標準差為1的向量?
然後再用EAE這篇(https://kexue.fm/archives/7343)中的最大化k鄰近樣本熵的技巧,對batch中的每個樣本計算第二鄰近的樣本熵,為什麼是第二?因為在SimCSE中第一鄰近理論上是自己跟自己(兩次dropout產生的差異),這個差異取決於dropout的大小,每次dropout 就好像一次 sample 一樣,我們不希望同一句話的兩次sample差太多;但是若是不同句話,我們希望它們的差別儘量大,在這裡就是跟第二鄰近的樣本拉得越開越好。這樣鼓勵網路產生的句向量越均勻越好,結合上面的BN層,就得到了近乎是各向同性的向量分布。
我認為,在PAWSX的實驗中,白化之所以優於SimCSE是因為白化操作把詞彙上相似但不同的句子的距離拉開了,而語意上相似的句子並沒有受到白化太多影響,所以相對起來比沒有白化之前好;而SimCSE效果較差並不是因為沒有學到語義信息,而是因為「自己跟自己比」這個操作,很容易讓詞彙上相似的句子也被視為相似(因為自己跟自己就是完全的詞彙重疊)。因此,為了避免因詞彙高度重疊就判定為相似的情況,再透過最大化k鄰近樣本熵這個技巧,讓詞彙高度重疊的句子能產生更多樣化的句向量,藉此就能區別出詞彙高度重疊但語義不同的情況。
此外,我認為訓練過程中可以加上「動態dropout」。意思是,從訓練一開始dropout為0,慢慢調升到某個上限(如0.5),然後再降回目標值(如0.3),這個過程類似模擬退火。
當dropout慢慢上升時,會增加系統的隨機性,隨機性越大,即使同一句子也有可能產生非常不同的句向量,不同句子間更有可能產生差異很大的句向量,這有助於讓句向量更均勻的分佈在向量空間中,讓神經網路探索整個空間極大的範圍。
當dropout到達上限後,由於同一個句子的句向量必須相似的限制,神經網路會傾向用不完整的資訊來建構一個句子的表徵,使得相同的句子能有相似的表徵。這個「利用不完整資訊」的過程,就是一個語義概念化的過程,因為它必須要在極小的訊噪比中抓出關鍵訊號,這就放大了語義的重要性,而降低了個別字符的重要性。因此它學到更多語義訊息,更少字符級別的訊息。
當dropout慢慢下降時,所學到的資訊開始固化,神經網路將"習慣"採用語義訊息來為句子產生表徵。這對於同一個句子,將產生相似的句向量,而對不同的句子,也能根據語義產生對應的句向量。由於先前dropout上升的探索過程及「最大化k鄰近樣本熵」,讓一些字面上相似但語意上極為不同的句子(例如:「今天天氣很好」與「今天天氣不好」),能夠有機會跳到向量空間中的不同區域,並在這一步從語義層面將表徵慢慢固化,從而得到具有更佳語義代表性的句向量。
如果沒有「最大化k鄰近樣本熵」,那麼當遇到「今天天氣很好」與「今天天氣不好」這兩個字面上相似但完全反義的句子,結果可能不會更好。SimCSE的自己比自己可能會把這兩句話視為相似,雖然也有自己跟其他句子比的loss項,但是「今天天氣很好」與「今天天氣不好」的距離跟「今天天氣很好」與「我喜歡遛狗」的距離並沒有任何限制,非常有可能前者大於後者,但從語義上來看,前者應小於後者,而「最大化k鄰近樣本熵」就是試圖最大化前者句向量的多樣性,讓「今天天氣不好」有可能產生與「今天天氣很好」相差很大的句向量,讓結果更加符合語義上的期待,而非字面上的相似。
修正:但是「今天天氣很好」與「今天天氣不好」的距離跟「今天天氣很好」與「我喜歡遛狗」的距離並沒有任何限制,非常有可能前者小於後者,但從語義上來看,前者應大於後者,
1、BN不能代替whitening,但是BN+最大熵或许可以代替whitening;
2、跟EAE联系起来这个视角很不错,值得细细品味,非常感谢你的有启发的思考;
3、动态Dropout的做法,有效的可能性是很大的,毕竟不管怎么样也算多了一个超参数,不过这应该交给喜欢炼丹的朋友尝试了;
4、关于语义,本身就是很虚很玄的内容,首先不管是whitening还是simcse,本身就依赖于预训练模型,没有预训练就啥也不是;但预训练本身,如何得到一个“不上不下”的句向量的,这个逻辑本身就很难想清楚,更不用说建立在此之上的whitening或simcse了;
5、所以,这些东西都只能去尝试,然后确认结果,也许你提供的做法是有效的,但即便如此,也是有效的原因跟你分析的原理完全无关也说不准,我一般倾向于不去深入思考这类问题;
6、一旦深入思考,其实归根结底的问题是:如何给“相似”或“同义”总结出一个在一定程度上可以量化的指标,而不是纯粹说“我(人)觉得相似才相似”,这样争议就是无穷无尽了;
7、到了这个程度,我们最终可能感觉到,这种指标是很难量化出来的,拼命搞无监督语义,还不如标点数据,通过有监督数据告诉模型什么是相似。
謝謝指教!
我也覺得語義這東西,應該是看目標任務來定義的...。就如我舉的例子:「今天天氣很好」、「今天天氣不好」和「我喜歡遛狗」,如果目標任務是天氣相關的句子,那前兩句話應該更相似;但如果目標任務是跟戶外活動相關的句子,那「今天天氣很好」跟「我喜歡遛狗」可能更接近。若是這樣,作為預訓練模型,應該盡可能不要多做假設才是合理的。所以不論是最大熵或是各向同性,都是往這方向邁進沒錯。
但我又想到一個問題,那些用來評價無監督模型優劣的資料集,其本身對任務是否已經隱含了某些假設,例如怎樣算相似、怎樣算不相似,很可能在蒐集資料時就已經隱含了,所以某個方法在這個資料集好,另個方法在另個資料集好,單看分數似乎也不是那麼準確....。或許應該要看一些獨立指標,如SimCSE論文中提到的 alignment 與 uniformity之類的了。
能意识到“根据目标任务来定义”,已经超越了90%的做相似的的人了,不至于总是问“我喜欢北京”跟“我不喜欢北京”相似度怎么这么高的问题了。说白了,“根据目标任务来定义”,就是“相不相似人说了算”,就是“不客观的人乱定义的”,所以就是“只能靠标数据有监督训练”,不能靠客观的无监督学习。
May 12th, 2021
苏神,你训练目标分母比原论文多了一项同dropout_mask的,是为了增多负样本吗
没为啥,就是觉得这样做简单直接一点~(能直接调用之前simbert的代码)
至于去掉会更好还是更差,我也不知道...
好的,感谢
May 14th, 2021
苏神,您好,看完您的代码有个问题想咨询一下, 在数据预测处理的时候,我们是将所有的数据打乱,假设输入['你好吗', '今天吃了馒头', ’我爱上你了‘, '马上毕业了'], 则模型输入为 4×768, 接下来就是计算损失, 这里将损失计算最终转化为分类问题,针对刚才那个数据,label应该是[[False, True, False, False], [True, False, False, False], [False, False, False, True], [False, False, True, False], 在损失计算时,我们还会将模型输出进行自己和自己矩阵乘,变为4x4的相关性矩阵。接着计算分类损失。 看样子,在一个batch内,应该第一个和第二个数据是相似的,第三个和第四个数据相似 依次类推才是,为啥代码中的数据预处理是随机组织的。
难道输入的时候,句子的组织形式是: ['你好吗','你好吗', '今天吃了馒头','今天吃了馒头', ’我爱上你了‘, ’我爱上你了‘, '马上毕业了','马上毕业了']?
是的
我这块也是有点迷
May 25th, 2021
苏神,这个思想用来优化文本分类的任务会不会有效果呢,比如我有大量的无标数据集,用这种思想来构建预训练任务,来优化bert的embedding表示呢,还是说对于分类任务不如直接用mlm的预训练方式来训练更加有效
我没试过。我倾向于没什么帮助,因为SimCSE其实非常弱,没训练几步就收敛了~