






11
Dec
从动力学角度看优化算法(六):为什么SimSiam不退化?
By 苏剑林 | 2020-12-11 | 125608位读者 |自SimCLR以来,CV中关于无监督特征学习的工作层出不穷,让人眼花缭乱。这些工作大多数都是基于对比学习的,即通过适当的方式构造正负样本进行分类学习的。然而,在众多类似的工作中总有一些特立独行的研究,比如Google的BYOL和最近的SimSiam,它们提出了单靠正样本就可以完成特征学习的方案,让人觉得耳目一新。但是没有负样本的支撑,模型怎么不会退化(坍缩)为一个没有意义的常数模型呢?这便是这两篇论文最值得让人思考和回味的问题了。
其中SimSiam给出了让很多人都点赞的答案,但笔者觉得SimSiam也只是把问题换了种说法,并没有真的解决这个问题。笔者认为,像SimSiam、GAN等模型的成功,很重要的原因是使用了基于梯度的优化器(而非其他更强或者更弱的优化器),所以不结合优化动力学的答案都是不完整的。在这里,笔者尝试结合动力学来分析SimSiam不会退化的原因。
SimSiam #
在看SimSiam之前,我们可以先看看BYOL,来自论文《Bootstrap your own latent: A new approach to self-supervised Learning》,其学习过程很简单,就是维护两个编码器Student和Teacher,其中Teacher是Student的滑动平均,Student则又反过来向Teacher学习,有种“左脚踩右脚”就可以飞起来的感觉。示意图如下:
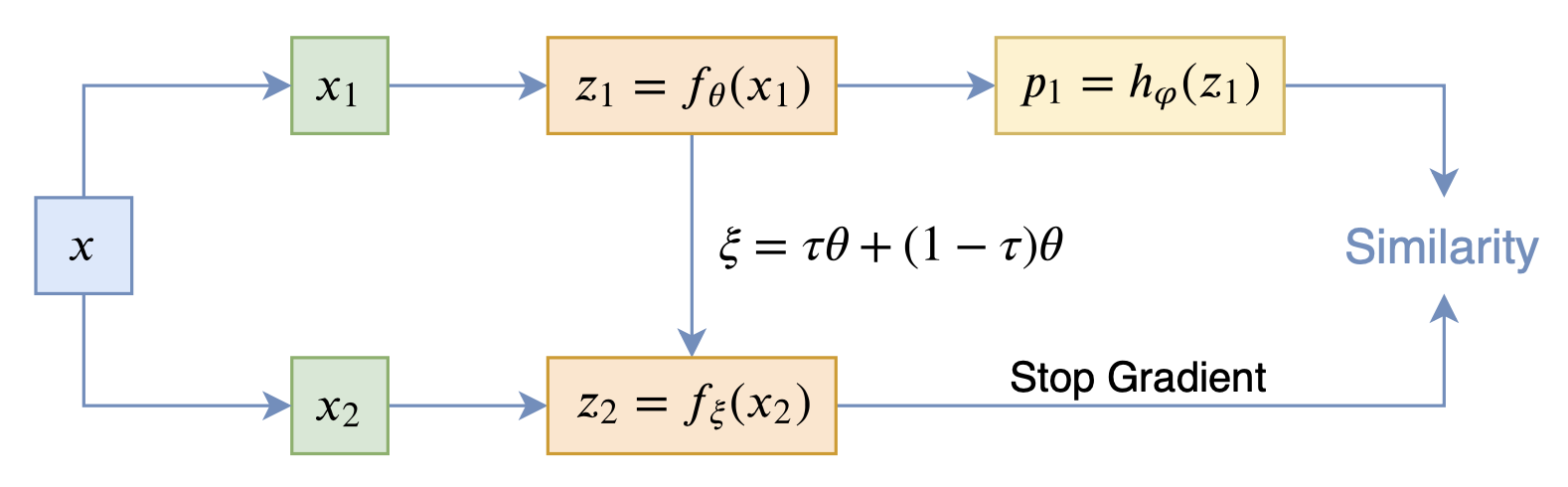
BYOL示意图
而SimSiam则来自论文《Exploring Simple Siamese Representation Learning》,它更加简单,直接把BYOL的滑动平均去掉了:
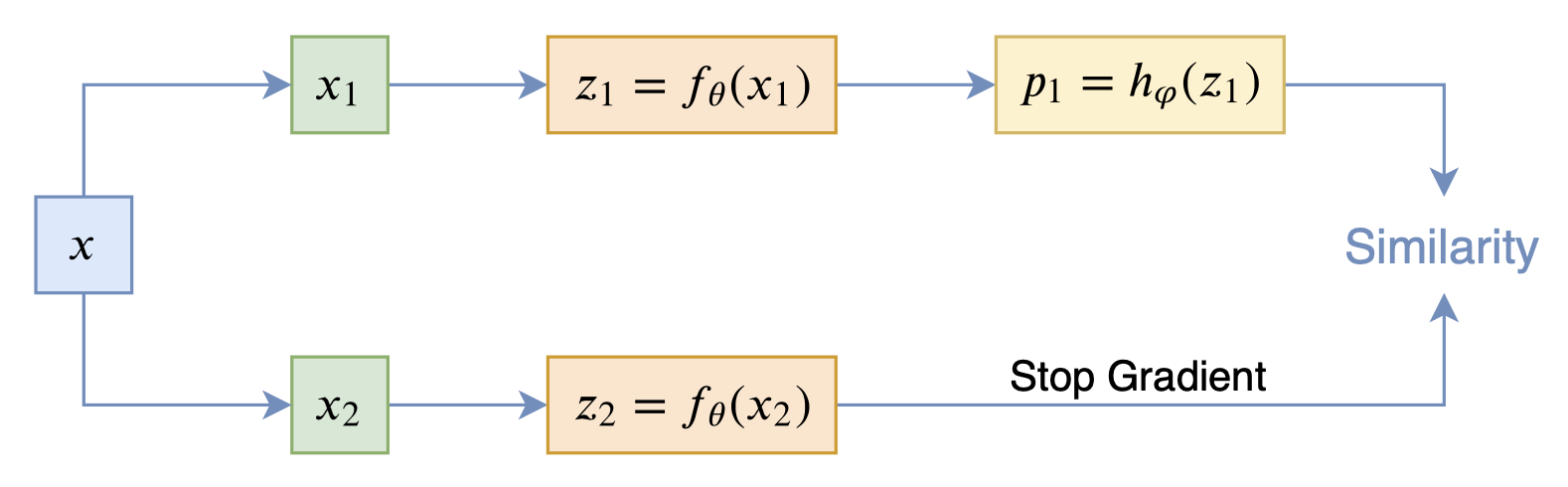
SimSiam示意图
事实上,SimSiam相当于将BYOL的滑动平均参数$\tau$设置为0了,这说明BYOL的滑动平均不是必须的。为了找出算法中的关键部分,SimSiam还做了很多对比实验,证实了stop_gradient算子以及predictor模块$h_{\varphi}(z)$是SimSiam不退化的关键。为了解释这个现象,SimSiam提出了该优化过程实际上相当于在交替优化
\begin{equation}\mathcal{L}(\theta, \eta)=\mathbb{E}_{x, \mathcal{T}}\left[\left\Vert\mathcal{F}_{\theta}(\mathcal{T}(x))-\eta_{x}\right\Vert^2\right]\label{eq:simsiam}\end{equation}
其中$x$代表训练样本而$\mathcal{T}$代表数据扩增。这部分内容网上已有不少解读,直接读原论文也不困难,因此就不详细展开了。
动力学分析 #
然而,笔者认为,将SimSiam算法的理解转换成$\mathcal{L}(\theta, \eta)$的交替优化的理解,只不过是换了种说法,并没有作出什么实质的回答。因为很明显,目前$\mathcal{L}(\theta, \eta)$也存在退化解,模型完全可以让所有的$\eta_{x}$都等于同一个向量,然后$\mathcal{F}_{\theta}$输出同一个常数向量。不回答$\mathcal{L}(\theta, \eta)$的交替优化为什么不退化,那也等于没有回答问题。
下面笔者将列举出自认为是SimSiam不退化的关键因素,并且通过一个简单的例子表明回答不退化的原因需要跟动力学结合起来。当然,笔者这部分的论述其实也是不完整的,甚至是不严谨的,只是抛砖引玉地给出一个新的视角。
深度图像先验 #
首先,很早之前人们就发现一个随机初始化的CNN模型就可以直接用来提取视觉特征,效果也不会特别差,该结论可以追溯到2009年的论文《What is the best multi-stage architecture for object recognition?》,这可以理解为CNN天然具有处理图像的能力。后来这个特性被起了一个高大上的名字,称为“深度图像先验”,出自论文《Deep Image Prior》,里边做了一些实验,表明从一个随机初始化的CNN模型出发,不需要任何监督学习,就可以完成图像补全、去噪等任务,进一步确认了CNN天然具有处理图像的能力这个特性。
按照笔者的理解,“深度图像先验”源于三点:
1、图像的连续性,是指图像本身就可以直接视为一个连续型向量,而不需要像NLP那样要学习出Embedding层出来,这意味着我们用“原始图像+K邻近”这样简单粗暴的方法就可以做很多任务了;
2、CNN的架构先验,指的是CNN的局部感知设计确实很好地模拟了肉眼的视觉处理过程,而我们所给出的视觉分类结果也都是基于我们的肉眼所下的结论,因此两者是契合的;
3、良好的初始化,这不难理解,再好的模型配上全零初始化了估计都不会work,之前的文章《从几何视角来理解模型参数的初始化策略》也简单讨论过初始化方法,从几何意义上来看,主流的初始化方法都是一种近似的“正交变换”,能尽量地保留输入特征的信息。
不退化的动力学 #
还是那句话,深度图像先验意味着一个随机化的CNN模型就是一个不是特别差的编码器了,于是我们接下来要做的事情无非可以归结为两点:往更好地方向学、不要向常数退化。
往更好地方向学,就是通过人为地设计一些先验信号,让模型更好地融入这些先验知识。SimSiam、BYOL等让同一张图片做两种不同的数据扩增,然后两者对应的特征向量尽量地相似,这便是一种好的信号引导,告诉模型简单的变换不应当影响我们对视觉理解,事实上,这也是所有对比学习方法所用的设计之一。
不同的则是在“不要向常数退化”这一点上,一般的对比学习方法是通过构造负样本来告诉模型哪些图片的特征不该相近,从而让模型不退化;但是SimSiam、BYOL不一样,它们没有负样本,实际上它们是通过将模型的优化过程分解为两个同步的、但是快慢不一样的模块来防止退化的。还是以SimSiam为例,它的优化目标可以写为
\begin{equation}\mathcal{L}(\varphi, \theta)=\mathbb{E}_{x, \mathcal{T}_1,\mathcal{T}_2}\Big[l\left(h_{\varphi}(f_{\theta}(\mathcal{T}_1(x))), f_{\theta}(\mathcal{T}_2(x))\right)\Big]\end{equation}
然后用梯度下降来优化,对应的动力学方程组是
\begin{equation}\begin{aligned}
\frac{d\varphi}{dt} = - \frac{\partial\mathcal{L}}{\partial \varphi} =& -\mathbb{E}_{x, \mathcal{T}_1,\mathcal{T}_2}\bigg[\frac{\partial l}{\partial h}\frac{\partial h}{\partial \varphi}\bigg]\\
\frac{d\theta}{dt} = - \frac{\partial\mathcal{L}}{\partial \theta} =& -\mathbb{E}_{x, \mathcal{T}_1,\mathcal{T}_2}\bigg[\frac{\partial l}{\partial h}\frac{\partial h}{\partial f}\frac{\partial f}{\partial \theta} \color{skyblue}{\,+\underbrace{\frac{\partial l}{\partial f}\frac{\partial f}{\partial \theta}}_{\begin{aligned}\text{SimSiam}\\\text{去掉了它}\end{aligned}}}\bigg]
\end{aligned}\end{equation}
上式已经注明了有无stop_gradient算子所带来的差别。简单来说,如果添加了stop_gradient算子,那么$\frac{d\theta}{dt}$就少了第二项,这时候$\frac{d\varphi}{dt}$和$\frac{d\theta}{dt}$都共同包含因子$\frac{\partial l}{\partial h}$,由于$h_{\varphi}$更靠近输出层,并且初始化的$f_{\theta}$也是一个不差的编码器,因此开始学习的时候,$h_{\varphi}$会被优化得更快,越靠近输入层的优化得越慢。也就是说,$\frac{d\varphi}{dt}$是快动力学部分,$\frac{d\theta}{dt}$则是慢动力学部分,那么相对而言,$\frac{d\varphi}{dt}$会更快速地收敛到0,这意味着$\frac{\partial l}{\partial h}$会很快地变得很小,由于$\frac{d\theta}{dt}$也包含$\frac{\partial l}{\partial h}$这一项,所以$\frac{d\theta}{dt}$跟着变得小,在它退化之前,推动它退化的力都已经微乎其微了,也就不会退化了。相反,如果有第二项$\frac{\partial l}{\partial f}\frac{\partial f}{\partial \theta}$(不管是补充上它还是只保留它),那么就相当于添加了一个“快速通道”,使得它变为快速项,就算$\frac{\partial l}{\partial h}=0$,但由于第二项在,还会继续推动着它退化。
举个简单的具体例子,我们考虑
\begin{equation}l = \frac{1}{2}(\varphi\theta - \theta)^2\end{equation}
简单起见这里的$\varphi,\theta$都是标量,对应动力学方程是
\begin{equation}\frac{d\varphi}{dt}=-(\varphi\theta - \theta)\theta, \quad\frac{d\theta}{dt}=-(\varphi\theta - \theta) \varphi \color{skyblue}{+ \underbrace{(\varphi\theta - \theta)}_{\begin{aligned}\text{SimSiam}\theta\\ \text{去掉了它}\end{aligned}}}\end{equation}
假设$\varphi(0)=0.6, \theta(0)=0.1$(随便选的),那么两者的演变是:
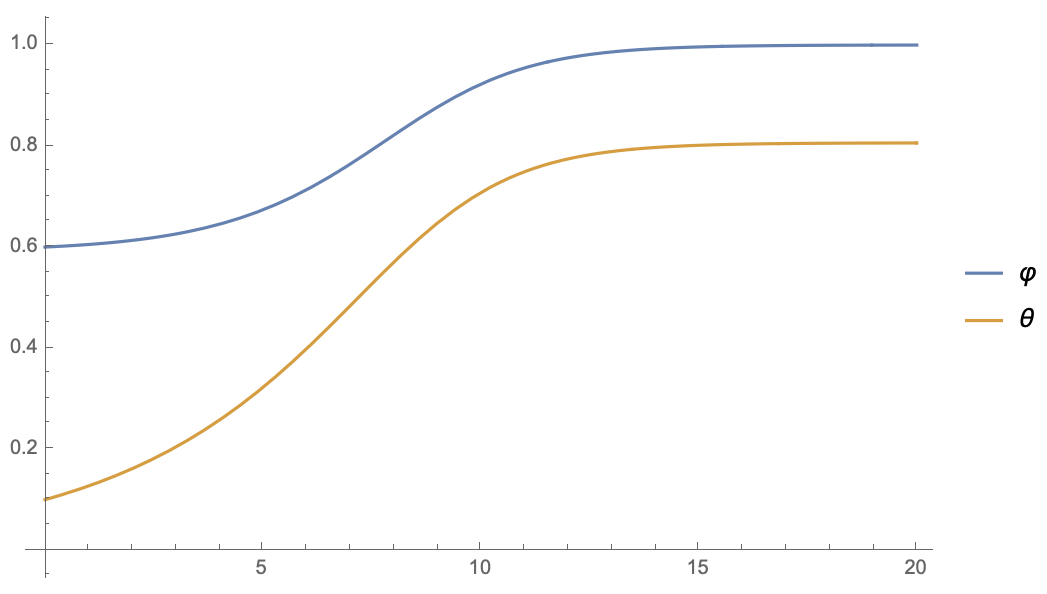
停掉第二个θ的梯度
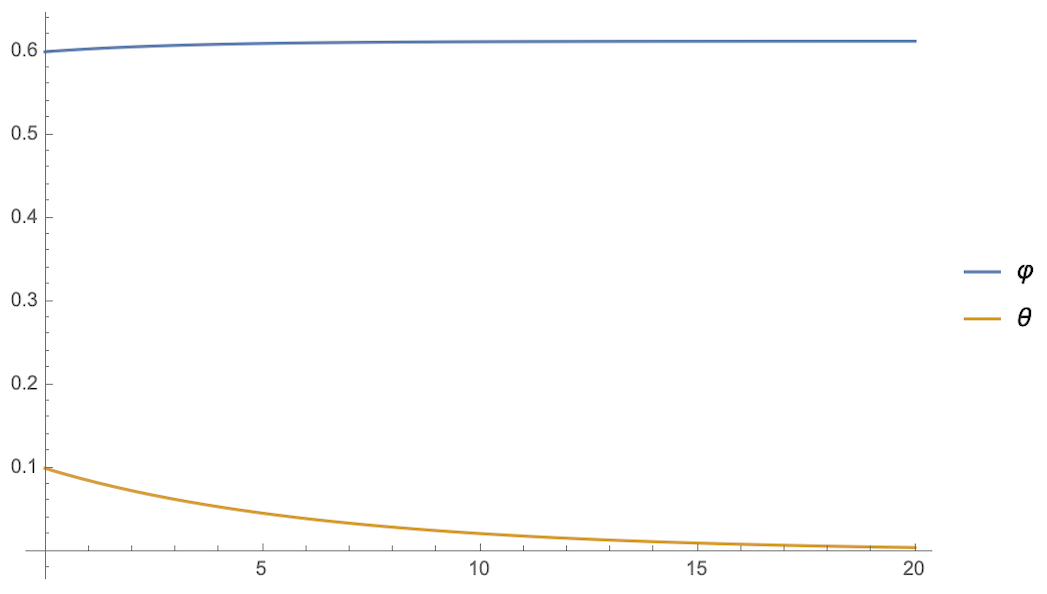
不停掉第二个θ的梯度
可以看到,停掉第二个$\theta$的梯度后,$\varphi$和$\theta$的方程是相当一致的,$\varphi$迅速趋于1,同时$\theta$稳定到了一个非0值(意味着没退化)。相当,如果补充上$\frac{d\theta}{dt}$的第二项,或者干脆只保留第二项,结果都是$\theta$迅速趋于0,而$\varphi$则无法趋于1了,这意味着主导权被$\theta$占据了。
这个例子本身没多大说服力,但是它简单地揭示了动力学的变化情况:
predictor($\varphi$)的引入使得模型的动力学分为了两大部分,stop_gradient算子的引入则使得encoder部分($\theta$)的动力学变慢,并且增强了encoder与predictor的同步性,这样一来,predictor以“迅雷不及掩耳之势”拟合了目标,使得encoder还没来得及退化,优化过程就停止了。
看近似展开 #
当然,诠释千万种,皆是“马后炮”,真正牛的还是发现者,我们充其量也就是蹭掉热度而已。这里再多蹭一下,分享笔者从另外一个视角看的SimSiam。文章开头说了,SimSiam论文提出了通过目标$\eqref{eq:simsiam}$的交替优化来解释SimSiam,这个视角就是从目标$\eqref{eq:simsiam}$出发,进一步深究一下它不退化的原因。
如果固定$\theta$,那么对于目标$\eqref{eq:simsiam}$来说,很容易解出$\eta_x$的最优值为
\begin{equation}\eta_x=\mathbb{E}_{\mathcal{T}}\left[\mathcal{F}_{\theta}(\mathcal{T}(x))\right]\end{equation}
代入$\eqref{eq:simsiam}$,就得到优化目标为
\begin{equation}\mathcal{L}(\theta)=\mathbb{E}_{x, \mathcal{T}}\bigg[\Big\Vert\mathcal{F}_{\theta}(\mathcal{T}(x))-\mathbb{E}_{\mathcal{T}}\left[\mathcal{F}_{\theta}(\mathcal{T}(x))\right]\Big\Vert^2\bigg]\end{equation}
我们假定$\mathcal{T}(x)-x$是“小”的向量,那么在$x$处做一阶展开得到
\begin{equation}\mathcal{L}(\theta)\approx\mathbb{E}_{x, \mathcal{T}}\bigg[\left\Vert\frac{\partial \mathcal{F}_{\theta}(x)}{\partial x}\big(\mathcal{T}(x)-\bar{x}\big)\right\Vert^2\bigg]\label{eq:em-sim}\end{equation}
其中$\bar{x}=\mathbb{E}_{\mathcal{T}}\left[\mathcal{T}(x)\right]$是同一张图片在所有数据扩增手段下的平均结果,注意它通常不等于$x$。类似地,如果是不加stop_gradient也不加predictor的SimSiam,那么损失函数近似为
\begin{equation}\mathcal{L}(\theta)\approx\mathbb{E}_{x, \mathcal{T}_1, \mathcal{T}_2}\bigg[\left\Vert\frac{\partial \mathcal{F}_{\theta}(x)}{\partial x}\big(\mathcal{T}_2(x)-\mathcal{T}_1(x)\big)\right\Vert^2\bigg]\label{eq:em-sim-2}\end{equation}
在式$\eqref{eq:em-sim}$中,每个$\mathcal{T}(x)$减去了$\bar{x}$,可以证明这个选择能使得损失函数最小;而在式$\eqref{eq:em-sim-2}$中,每个$\mathcal{T}_1(x)$减去的是另一个扩增结果$\mathcal{T}_2(x)$,会导致损失函数本身和估计的方差都大大增大。
那是不是意味着,不加stop_gradient、不加predictor会失败的原因,是因为它的损失函数以及方差过大呢?注意到在一阶近似下有$\eta_x\approx \mathcal{F}_{\theta}(\bar{x})$,那如果优化目标换成
\begin{equation}\mathcal{L}(\theta)=\mathbb{E}_{x, \mathcal{T}}\bigg[\Big\Vert\mathcal{F}_{\theta}(\mathcal{T}(x))-\mathcal{F}_{\theta}(\bar{x})\Big\Vert^2\bigg]\end{equation}
是不是就不会退化了?笔者也没有验证过,不得而知,正在研究相关内容的读者不妨验证一下。这里还引申出一个相关的问题,经过这样训练好的编码器,究竟用$\mathcal{F}_{\theta}(x)$还是$\mathcal{F}_{\theta}(\bar{x})$作为特征好呢?
当然,这部分的讨论都是建立在“$\mathcal{T}(x)-x$是小的向量”这个假设的基础上的,如果它不成立,那么这一节内容就是白说了。
总文末小结 #
本文试图从动力学角度给出笔者对BYOL、SimSiam算法不退化的理解,很遗憾,写到一半的时候发现之前头脑中构思的一些分析无法自圆其说了,于是删减了一些内容,并补充了一个新的角度,尽量让文章不“烂尾”,至于求精,那是说不上了。权当笔记分享在此,如有不当之处,还望读者海涵斧正。
转载到请包括本文地址:https://spaces.ac.cn/archives/7980
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Dec. 11, 2020). 《从动力学角度看优化算法(六):为什么SimSiam不退化? 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7980
@online{kexuefm-7980,
title={从动力学角度看优化算法(六):为什么SimSiam不退化?},
author={苏剑林},
year={2020},
month={Dec},
url={\url{https://spaces.ac.cn/archives/7980}},
}

December 18th, 2020
苏神,这种孪生网络以及参数更新方式有机会应用到NLP 中吗?比如说句子相似度?句向量?
对比学习可以,这种没有负样本的估计很难。
感谢苏神的回复
做过一些实验:
1.只使用正例来训练这种网络(两个意思相同,但句式不同的句子),在训练过程中用 1- 余弦相似度做loss,loss 趋于0,在eval 过程中两个句子的余弦相似度趋于1.但是在现实场景中是类似与FAQ的任务,需要输入与库里所有的句子做比较,得到的结果往往会出现与很多的句子都匹配(没法使用,是不是应为训练过程中没有出现负例导致的?)。
2.但是使用类似于DSSM的结构,加入负例使用triple loss,效果就会改善很多。
3.对比这两组实验结果,1中同样的参数,训练不同次数得到的匹配正确率浮动很大。
最后:还是觉得这种online 与target 的网络结构以及更新参数的方式很新奇,想用到NLP中,不过好像失败了。苏神有什么建议或者想法吗?
我不是说了没有负样本的方式在NLP中很难成功吗?哪还有什么建议...
对于SimSiam的成功,本文已经列举了自己认为的关键因素,这些关键因素在NLP中基本都不成立,所以我没有什么建议...
December 20th, 2020
苏神你好,请教下,keras可以实现单机多卡的预测吗:
如下代码貌似只能实现keras的多卡训练:
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
......
那么如何实现keras的多卡预测呢?因为我预测的文本量巨大,单卡预测太费时间了。
希望苏神给我解答下。
好像没有单机多卡的预测,你可以每张卡跑一个脚本,每个脚本跑不同的输入啊~
毕竟还是想要优雅一点的代码来自动化实现一个问题,昨天想了下把数据切分成若干份,用不同的GPU处理然后再拼接,但是貌似在最后的数据处理维度上出了点问题,我再尝试改一下吧。多谢苏神回答。
February 18th, 2021
苏神,按照你这个解释,不光是不容易退化,也不容易优化吧。
就是希望越靠近输入层,优化程度越小,防止严重退化。
March 12th, 2021
有个地方还是不大理解请点拨一下:为什么fθ(T(x))拟合得慢能阻止退化。退化就意味着∂fθ(x)/∂x=0,θ变化的快意味着越容易达成∂fθ(x)/∂x=0,有什么例子或推导能详细说明一下吗?
没看懂你要我举什么例子。如果直观来看的话,就是$x$是输入,根据链式法则$\frac{\partial f_{\theta}(x)}{\partial x}$等于它对每一层梯度的连乘,而$\frac{\partial f_{\theta}(x)}{\partial \theta}$实际上也涉及到每一层的梯度,要控制$\frac{\partial f_{\theta}(x)}{\partial x}\neq 0$,某种意义上也是控制$\frac{\partial f_{\theta}(x)}{\partial \theta}$不要过度退化。
不知道这么理解是否正确:这里的“退化”能否简单地理解为θ=0,控制θ变化慢,也就抑制了θ趋向0。这里又产生几个问题:
1 似乎这有个先天假设——优化是直奔平凡解而去(所以才需要θ变慢阻止),难道神经网络天生就爱走“捷径”,有一篇论文Shortcut learning in deep neural networks讨论捷径问题。
2 由于θ变化慢,优化loss的任务主要由φ承担,但这样是否会导致优化停止时θ没得到充分的训练,此时用fθ(x)做特征“火候”是否足够?
可以这么理解。
1、不是神经网络天生走捷径,可能是梯度下降的原因;
2、这个部分本来就很玄学,比如predictor($\varphi$)多大才适合?特别简单行不?特别复杂行不?我目前目前成功的SimSiam,本身就是调了个适当的predictor,使得encoder得到适当程度的训练。
确实很玄学
1 从简单例子(4)看到θ原先是奔0现在是奔大于0.1去了,方向完全相反,像是θ变慢之后有助于跳出某些不好的local minuma。
2 关于φ的控制,还以(4)为例,其实φ=1时,θ有无穷个非零最优解,当训练使得φ=1(epoch≈11),θ≈0.75就几乎停止了这能不能也算是一种“退化”呢,θ=10或100就不是一个好的encoder参数了?。
省掉了负样本会不会引入新问题,如φθ协调控制变难了。毕竟负样本能排除掉某些不必要的优化方向,完全去掉信息损失太大。
2、所以说,初始化很重要,DIP很重要,训练过程只是调优。
March 25th, 2021
您好,我第一次看到从动力学的角度解释问题。最开始的动力学方程没有看懂,可以解释一下吗?
建议先看完本系列前五篇。
May 16th, 2021
您好,想问问那个t是什么..........
没有学过相关的动力学
你可以理解为训练步数。
其实你这里是想说theta和h都是关于时间t的函数对吧,可以告诉我想看懂您这个分析需要学什么知识嘛,我现在刚刚phd入学比较菜嘿嘿
常微分方程。
May 21st, 2021
为什么需要假设T(x)-x是小的向量,这个小指的的模吗?
因为“小”才能用泰勒展开近似。“小”可以用模长来度量。
July 25th, 2021
这篇博文和tian yuandong最近ICML那篇论文讨论的问题完全一样,苏神怎么看那篇论文呢
Understanding Self-supervised Learning Dynamics without Contrastive Pairs这篇?感觉思想上跟本文也差不多,但做的更加深入细致,作者的数学功底也很深厚。不过后来我也不大关心这个问题了,没仔细研究,所以没法过多评论。
December 23rd, 2021
How Does SimSiam Avoid Collapse Without Negative Samples? Towards a Unified Understanding of Progress in SSL
这篇ICLR 2022在审稿的论文好像是最新相关的文章?
苏神有没有兴趣看看啊?感觉没啥公式但是看不懂。
像3.1里 Za is a dummy term because the loss −Za · Za = −1 is a constant having zero gradient on the encoder f.Za是dummy term但是这个理由为什么成立啊,明明−Zb · Zb = −1,照这么说Zb也是dummy term?
3.2节里 Since rb comes from the same positive sample as ra, it is expected that rb also increases mr, however, this effect is expected to be smaller than that of ra, thus causing collapse. 凭什么说小就小呢,3.3节里$L_{triplet}$ baseline,按作者的说法梯度是$r_b-r_e$,形式都是一致的,但是输出没有模式坍塌这不是和向量方向相关么。
第一个问题我懂了
好像之前刷到过了,提不起兴趣~(捂脸)
December 28th, 2021
其实我好奇的是,为什么 simsiam 没有负样本性能也这么好?对比学习没负样本,有点难以理解。
这个问题,很难