






27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 224461位读者 |大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
冉冉升起的MLM #
MLM,全称“Masked Language Model”,可以翻译为“掩码语言模型”,实际上就是一个完形填空任务,随机Mask掉文本中的某些字词,然后要模型去预测被Mask的字词,示意图如下:
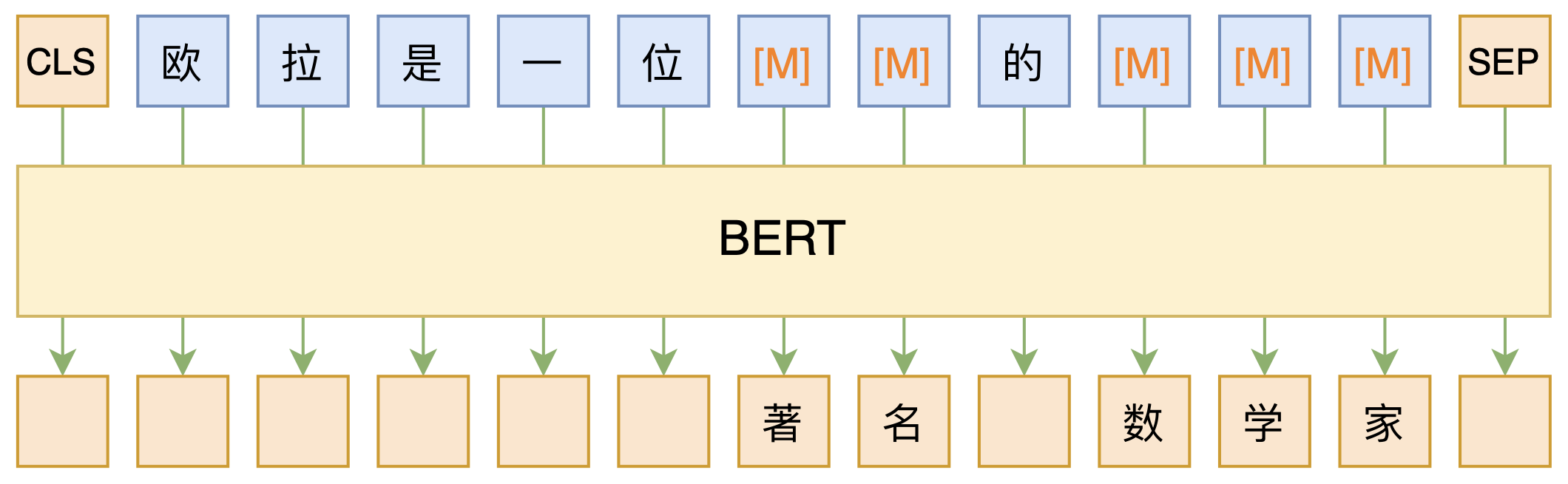
BERT的MLM模型简单示意图
其中被Mask掉的部分,可以是直接随机选择的Token,也可以是随机选择连续的能组成一整个词的Token,后者称为WWM(Whole Word Masking)。
开始,MLM仅被视为BERT的一个预训练任务,训练完了就可以扔掉的那种,因此有一些开源的模型干脆没保留MLM部分的权重,比如brightmart版和clue版的RoBERTa,而哈工大开源的RoBERTa-wwm-ext-large则不知道出于什么原因随机初始化了MLM部分的权重,因此如果要复现本文后面的结果,这些版本是不可取的。
然而,随着研究的深入,研究人员发现不止BERT的Encoder很有用,预训练用的MLM本身也很有用。比如论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》指出MLM可以作为一般的生成模型用,论文《Spelling Error Correction with Soft-Masked BERT》则将MLM用于文本纠错,笔者之前在《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》的实验也表明MLM的预训练权重也可以当作UniLM来用做Seq2Seq任务,还有《无监督分词和句法分析!原来BERT还可以这样用》一文将MLM的思想用于无监督分词和句法分析了。可以说MLM已经是大放异彩了。
将任务转成完形填空 #
在本文里,我们再学习MLM的一个精彩应用:用于小样本学习或半监督学习,某些场景下甚至能做到零样本学习。
怎么将我们要做的任务跟MLM结合起来呢?很简单,给任务一个文本描述,然后转换为完形填空问题即可。举个例子,假如给定句子“这趟北京之旅我感觉很不错。”,那么我们补充个描述,构建如下的完形填空:
______满意。这趟北京之旅我感觉很不错。
进一步地,我们限制空位处只能填一个“很”或“不”,问题就很清晰了,就是要我们根据上下文一致性判断是否满意,如果“很”的概率大于“不”的概率,说明是正面情感倾向,否则就是负面的,这样我们就将情感分类问题转换为一个完形填空问题了,它可以用MLM模型给出预测结果,而MLM模型的训练可以不需要监督数据,因此理论上这能够实现零样本学习了。
多分类问题也可以做类似转换,比如新闻主题分类,输入句子为“八个月了,终于又能在赛场上看到女排姑娘们了。”,那么就可以构建
下面报导一则______新闻。八个月了,终于又能在赛场上看到女排姑娘们了。
这样我们就将新闻主题分类也转换为完形填空问题了,一个好的MLM模型应当能预测出“体育”二字来。
还有一些简单的推理任务也可以做这样的转换,常见的是给定两个句子,判断这两个句子是否相容,比如“我去了北京”跟“我去了上海”就是矛盾的,“我去了北京”跟“我在天安门广场”是相容的,常见的做法就是将两个句子拼接起来输入到模型做,作为一个二分类任务。如果要转换为完形填空,那该怎么构造呢?一种比较自然的构建方式是:
我去了北京?______,我去了上海。
我去了北京?______,我在天安门广场。
其中空位之处的候选词为$\{\text{是的}, \text{不是}\}$。
Pattern-Exploiting #
读到这里,读者应该不难发现其中的规律了,就是给输入的文本增加一个前缀或者后缀描述,并且Mask掉某些Token,转换为完形填空问题,这样的转换在原论文中称为Pattern,这个转换要尽可能与原来的句子组成一句自然的话,不能过于生硬,因为预训练的MLM模型就是在自然语言上进行的。显然同一个问题可以有很多不同的Pattern,比如情感分类的例子,描述可以放最后,变成“这趟北京之旅我感觉很不错。____满意。”;也可以多加几个字,比如“觉得如何?____满意。这趟北京之旅我感觉很不错。”。
然后,我们需要构建预测Token的候选空间,并且建立Token到实际类别的映射,这在原论文中称为Verbalizer,比如情感分类的例子,我们的候选空间是$\{\text{很}, \text{不}\}$,映射关系是$\text{很}\to\text{正面},\text{不}\to\text{负面}$,候选空间与实际类别之间不一定是一一映射,比如我们还可以加入“挺”、“太”、“难”字,并且认为$\{\text{很},\text{挺},\text{太}\}\to\text{正面}$以及$\{\text{不},\text{难}\}\to\text{负面}$,等等。不难理解,不少NLP任务都有可能进行这种转换,但显然这种转换一般只适用于候选空间有限的任务,说白了就是只用来做选择题,常见任务的就是文本分类。
刚才说了,同一个任务可以有多种不同的Pattern,原论文是这样处理的:
1、对于每种Pattern,单独用训练集Finetune一个MLM模型出来;
2、然后将不同Pattern对应的模型进行集成,得到融合模型;
3、用融合模型预测未标注数据的伪标签;
4、用伪标签数据Finetune一个常规的(非MLM的)模型。
具体的集成方式大家自己看论文就行,这不是重点。这种训练模式被称为Pattern-Exploiting Training(PET),它首先出现在论文《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》,本文要介绍的这篇论文则进一步肯定和完善了Pattern-Exploiting Training的价值和结果,并整合了多任务学习,使得它在SuperGLUE榜单上的小样本学习效果超过了GPT3。两篇论文的作者是相同的,是一脉相承的作品。
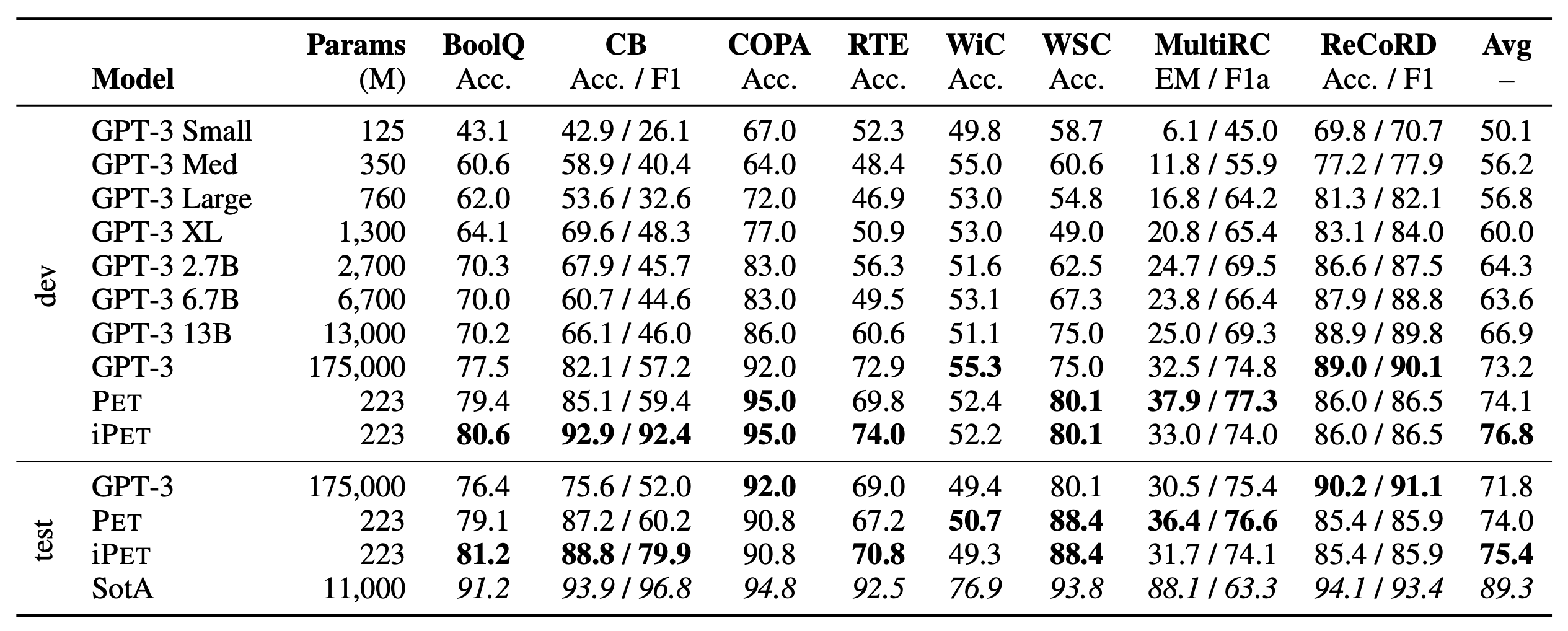
PET在SuperGLUE上的小样本学习的结果
不过要吐槽一个点是,上图中PET的223M参数,所用的模型是ALBERT-xxlarge-v2,事实上称ALBERT为“小模型”是一种很耍流氓的行为,因为它前向计算的速度并没有得到任何提升。ALBERT-xxlarge共有12层,层与层之间参数是共享的,就前向计算而言,它应该等价于约2700M(12倍)参数的GPT才对。
中文实践,检验效果 #
要真正确认一个方法或模型的价值,看论文的实验表格是不够的,论文给出的实验结果谁都不好说能否复现,其次就算英文上能复现也不代表中文上有价值,因此最实际的还是亲自动手做实验验证。下面是笔者的实验代码,供读者参考:
我们将从以下几个角度来探讨PET的可行性:
1、直接利用现成的MLM模型效果如何?(零样本学习1)
2、用“大量无标签数据”微调现成的MLM模型效果如何?(零样本学习2)
3、用“小量标签数据”微调现成的MLM模型效果如何?(小样本学习)
4、用“小量标签数据+大量无标签数据”微调现成的MLM模型效果如何?(半监督学习)
下面主要给出情感二分类的实验结果。另外还有一个新闻主题的多分类,代码也放到Github了,其结果是类似的,就不重复陈述了。
零样本学习1 #
这里主要探索的是给输入文本补上对应的Pattern后,直接基于现成的MLM模型进行预测,预测的准确率。由于构建模型的整个过程都不涉及到标签数据监督训练,因此这算是一种“零样本学习”。我们需要比较的是不同Pattern、不同MLM模型上的效果:
下面是实验的几个Pattern,其中空位处候选词语都为“很”和“不”:
P1:____满意。这趟北京之旅我感觉很不错。
P2:这趟北京之旅我感觉很不错。____满意。
P3:____好。这趟北京之旅我感觉很不错。
P4:____理想。这趟北京之旅我感觉很不错。
P5:感觉如何?____满意。这趟北京之旅我感觉很不错。
至于MLM模型,则是下面几个:
M1:Google开源的中文版BERT Base(链接);
M2:哈工大开源的RoBERTa-wwm-ext Base(链接):
M3:腾讯UER开源的BERT Base(链接);
M4:腾讯UER开源的BERT Large(链接)。
实验结果如下表(验证集/测试集):
$$\begin{array}{c}
\text{不同模型不同Pattern的零样本学习效果}
\\
{\begin{array}{c|ccccc}
\hline
& \text{P1} & \text{P2} & \text{P3} & \text{P4} & \text{P5} \\
\hline
\text{M1} & 66.94\,/\,67.60 & 57.56\,/\,56.13 & 58.83\,/\,59.69 & 83.70\,/\,83.33 & 75.98\,/\,76.13\\
\text{M2} & 85.17\,/\,84.27 & 70.63\,/\,68.69 & 58.55\,/\,59.12 & 81.81\,/\,82.28 & 80.25\,/\,81.62\\
\text{M3} & 66.75\,/\,68.64 & 50.45\,/\,50.97 & 68.97\,/\,70.11 & 81.95\,/\,81.48 & 61.49\,/\,62.58\\
\text{M4} & 83.56\,/\,85.08 & 72.52\,/\,72.10 & 76.46\,/\,77.03 & 88.25\,/\,87.45 & 82.43\,/\,83.56\\
\hline
\end{array}}
\end{array}$$
最好的效果居然可以达到88%!也就是说,加载现成的MLM,配合适当的Pattern,不需要任何标注数据,就可以正确识别大部分样本情感倾向了。这不得不让我们对MLM模型的潜力刮目相看了。
可以观察到,不同的Pattern、不同的预训练模型之间还是有一定的差异的,整体而言Large版本的效果要明显好于Base版本的模型,说明像GPT到GPT2再到GPT3一样,还是把模型做得更大会更好。此外,这还有可能说明实际上MLM还没有被充分训练好,或许是因为BERT这种Mask掉一部分的训练方式过于低效了,可能用《修改Transformer结构,设计一个更快更好的MLM模型》一文提到的改进版MLM会更好。
零样本学习2 #
看完上述结果,读者可能会想到:如果我用领域内的数据继续预训练MLM模型,那么能不能提升效果呢?答案是:能!下面是我们的实验结果,算力有限,我们只在RoBERTa-wwm-ext(上述的M2,继续预训练后的模型我们称为M2+无监督)的基础上做了比较:
$$\begin{array}{c}
\text{继续MLM预训练的零样本学习效果}
\\
{\begin{array}{c|ccccc}
\hline
& \text{P1} & \text{P2} & \text{P3} & \text{P4} & \text{P5} \\
\hline
\text{M2} & 85.17\,/\,84.27 & 70.63\,/\,68.69 & 58.55\,/\,59.12 & 81.81\,/\,82.28 & 80.25\,/\,81.62\\
\text{M2}^{+\text{无监督}} & 88.05\,/\,87.53 & 71.01\,/\,68.78 & 81.05\,/\,81.24 & 86.40\,/\,85.65 & 87.26\,/\,87.40\\
\hline
\end{array}}
\end{array}$$
要注意的是,这里我们只是用领域内的数据继续做MLM训练,这个过程是无监督的,也不需要标注信号,因此也算是“零样本学习”。同时,从到目前为止的结果我们可以看出,给输入本文加入“前缀”的效果比“后缀”更有优势一些。
小样本学习 #
刚才我们讨论了无标签数据继续预训练MLM的提升,如果回到PET的目标场景,直接用小量的标签数据配合特定的Pattern训练MLM又如何呢?这也就是真正的“小样本学习”训练了,这里我们保留约200个标注样本,构造样本的时候,我们先给每个句子补上Pattern,除了Pattern自带的Mask位置之外,我们还随机Mask其他一部分,以增强对模型的正则。最终实验结果如下:
$$\begin{array}{c}
\text{小样本学习效果}
\\
{\begin{array}{c|ccccc}
\hline
& \text{P1} & \text{P2} & \text{P3} & \text{P4} & \text{P5} \\
\hline
\text{M2} & 85.17\,/\,84.27 & 70.63\,/\,68.69 & 58.55\,/\,59.12 & 81.81\,/\,82.28 & 80.25\,/\,81.62\\
\text{M2}^{+\text{小样本}} & 89.29\,/\,89.18 & 84.71\,/\,82.76 & 88.91\,/\,89.05 & 89.31\,/\,89.13 & 89.07\,/\,88.75\\
\hline
\end{array}}
\end{array}$$
结论就是除了“后缀式”的P2之外,其它结果都差不多,这进一步说明了“前缀式”的Pattern会比“后缀式”更有竞争力一些。在效果上,直接用同样的数据用常规的方法去微调一个BERT模型,大概的结果是88.93左右,所以基于“MLP+Pattern”的小样本学习方法可能带来轻微的性能提升。
半监督学习 #
无监督的零样本学习和有监督的小样本学习都说完了,自然就轮到把标注数据和非标注数据都结合起来的“半监督学习”了。还是同样的任务,标注数据和非标注数据的比例大约是1:99,标注数据带Pattern,非标注数据不带Pattern,大家都Mask掉一部分Token进行MLM预训练,最终测出来的效果如下:
$$\begin{array}{c}
\text{半监督学习效果}
\\
{\begin{array}{c|ccccc}
\hline
& \text{P1} & \text{P2} & \text{P3} & \text{P4} & \text{P5} \\
\hline
\text{M2} & 85.17\,/\,84.27 & 70.63\,/\,68.69 & 58.55\,/\,59.12 & 81.81\,/\,82.28 & 80.25\,/\,81.62\\
\text{M2}^{+\text{半监督}} & 90.09\,/\,89.76 & 79.58\,/\,79.35 & 90.19\,/\,88.96 & 90.05\,/\,89.54 & 89.88\,/\,89.23\\
\hline
\end{array}}
\end{array}$$
还是同样的,“后缀”明显比“前缀”差,“前缀”的效果差不多。具体效果上,则是肯定了额外的无标注数据也是有作用的。直觉上来看,“前缀”比“后缀”要好,大体上是因为“前缀”的Mask位置比较固定,微弱的监督信号得以叠加增强?但这也不能解释为什么零样本学习的情况下也是“前缀”更好,估计还跟模型的学习难度有关系,可能句子前面部分的规律更加明显,相对来说更加容易学一些,所以前面部分就学习得更加充分?这一切都还只是猜测。
汇总与结论 #
将上述结果汇总如下:
$$\begin{array}{c}
\text{结果汇总比较}
\\
{\begin{array}{c|ccccc}
\hline
& \text{P1} & \text{P2} & \text{P3} & \text{P4} & \text{P5} \\
\hline
\text{M2} & 85.17\,/\,84.27 & 70.63\,/\,68.69 & 58.55\,/\,59.12 & 81.81\,/\,82.28 & 80.25\,/\,81.62\\
\text{M2}^{+\text{无监督}} & 88.05\,/\,87.53 & 71.01\,/\,68.78 & 81.05\,/\,81.24 & 86.40\,/\,85.65 & 87.26\,/\,87.40\\
\text{M2}^{+\text{小样本}} & 89.29\,/\,89.18 & 84.71\,/\,82.76 & 88.91\,/\,89.05 & 89.31\,/\,89.13 & 89.07\,/\,88.75\\
\text{M2}^{+\text{半监督}} & 90.09\,/\,89.76 & 79.58\,/\,79.35 & 90.19\,/\,88.96 & 90.05\,/\,89.54 & 89.88\,/\,89.23\\
\hline
\end{array}}
\end{array}$$
读者还可以对比我们之前在文章《泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练》中用虚拟对抗训练(VAT)做半监督学习的结果,可以看到不管是零样本学习、小样本学习还是半监督学习,基于MLM模型的方式都能媲美基于VAT的半监督学习的结果。我们在做短新闻多分类实验时的结果也是相似的。因此,这说明了MLM模型确实也可以作为一个优秀的零样本/小样本/半监督学习器来使用。
当然,基于MLM模型的缺点还是有的,比如MLM所使用的独立假设限制了它对更长文本的预测能力(说白了空位处的文字不能太长),以及无法预测不定长的答案也约束了它的场景(所以当前只能用于做选择题,不能做生成)。我们期待有更强的MLM模型出现,那时候就有可能在所有任务上都能与GPT3一较高下了。
又到了说小结的时候 #
本文介绍了BERT的MLM模型的一个新颖应用:配合特定的描述将任务转化为完形填空,利用MLM模型做零样本学习、小样本学习和半监督学习。在原论文的SuperGLUE实验里边,它能达到媲美GPT3的效果,而笔者也在中文任务上做了一些实验,进一步肯定了该思路的有效性。整个思路颇为别致,给人一种“原来还可以这样做”的恍然大悟感,推荐大家学习一下。
转载到请包括本文地址:https://spaces.ac.cn/archives/7764
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 27, 2020). 《必须要GPT3吗?不,BERT的MLM模型也能小样本学习 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7764
@online{kexuefm-7764,
title={必须要GPT3吗?不,BERT的MLM模型也能小样本学习},
author={苏剑林},
year={2020},
month={Sep},
url={\url{https://spaces.ac.cn/archives/7764}},
}

October 25th, 2022
[...]必须要 GPT3 吗?不,BERT 的 MLM 模型也能小样本学习[...]
October 30th, 2022
[...]转载自《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》和《P-tuning:自动构建模版,释放语言模型潜能》,作者:苏剑林,部分内容有修改。[...]
May 23rd, 2023
苏神你好,GPT-3中提到的小样本学习是通过提供一些任务示例作为prompt,引导GPT输出。例如机器翻译任务,输入为:“将英语翻译成中文:apple->苹果;orange->橘子;banana->”,让GPT接续输出。本质上不需要训练,而是直接推理。
在您这个博客里提到的第三个实验:用“小量标签数据”微调现成的MLM模型效果如何?(小样本学习)
这里的小样本学习需要对模型用少量数据进行训练。那么GPT-3提到的小样本学习不需要训练,直接推理就可以,但是这个需要训练。我对此有些疑惑,想问我们通常所说的小样本学习究竟是哪种形式呢?
都是少样本学习。只要是只用到了少量标注样本作为监督信号的方案,都叫做少样本学习,不拘泥于形式,或者说它们是实现少样本学习的不同方式。
September 3rd, 2023
"因此有一些开源的模型干脆没保留MLM部分的权重",这里的权重是Mask token embedding么?
BERT是tied embedding,最后的embedding跟输入是共享的,但最后一层transformer layer与tied embedding之间,还有一个tanh函数激活的dense层,指的是这个dense层。