






14
Aug
L2正则没有想象那么好?可能是“权重尺度偏移”惹的祸
By 苏剑林 | 2020-08-14 | 50771位读者 |L2正则是机器学习常用的一种防止过拟合的方法(应该也是一道经常遇到的面试题)。简单来说,它就是希望权重的模长尽可能小一点,从而能抵御的扰动多一点,最终提高模型的泛化性能。但是读者可能也会发现,L2正则的表现通常没有理论上说的那么好,很多时候加了可能还有负作用。最近的一篇文章《Improve Generalization and Robustness of Neural Networks via Weight Scale Shifting Invariant Regularizations》从“权重尺度偏移”这个角度分析了L2正则的弊端,并提出了新的WEISSI正则项。整个分析过程颇有意思,在这里与大家分享一下。
相关内容 #
这一节中我们先简单回顾一下L2正则,然后介绍它与权重衰减的联系以及与之相关的AdamW优化器。
L2正则的理解 #
为什么要添加L2正则?这个问题可能有多个答案。有从Ridge回归角度回答的,有从贝叶斯推断角度回答的,这里给出从扰动敏感性的角度的理解。
对于两个(列)向量$\boldsymbol{w},\boldsymbol{x}$,我们有柯西不等式$\left|\boldsymbol{w}^{\top}\boldsymbol{x}\right|\leq \Vert\boldsymbol{w}\Vert_2\Vert\boldsymbol{x}\Vert_2$。根据这个结果,我们就可以证明
\begin{equation}\Vert\boldsymbol{W}(\boldsymbol{x}_2 - \boldsymbol{x}_1)\Vert_2\leq \Vert\boldsymbol{W}\Vert_2\Vert\boldsymbol{x}_2 - \boldsymbol{x}_1\Vert_2\end{equation}
这里的$\Vert\boldsymbol{W}\Vert_2^2$等于矩阵$\boldsymbol{W}$的所有元素的平方和。证明并不困难,有兴趣的读者自行完成。这个结果告诉我们:$\boldsymbol{W}\boldsymbol{x}$的变化量,可以被$\Vert\boldsymbol{W}\Vert_2$和$\Vert\boldsymbol{x}_2 - \boldsymbol{x}_1\Vert_2$控制住,因此如果我们希望$\Vert\boldsymbol{x}_2 - \boldsymbol{x}_1\Vert_2$很小时$\boldsymbol{W}\boldsymbol{x}$的变化量也尽可能小,那么我们可以降低$\Vert\boldsymbol{W}\Vert_2$,这时候就可以往任务目标$\mathcal{L}_{task}$里边加入一个正则项$\mathcal{L}_{reg}=\Vert\boldsymbol{W}\Vert_2^2$。不难发现,这其实就是L2正则。这个角度的相关讨论还可以参考《深度学习中的Lipschitz约束:泛化与生成模型》(不过要注意两篇文章的记号略有不同)。
AdamW优化器 #
在使用SGD进行优化时,假设原来的迭代为$\boldsymbol{\theta}_{t}=\boldsymbol{\theta}_{t-1} - \varepsilon\boldsymbol{g}_{t}$,那么不难证明加入L2正则$\Vert\boldsymbol{\theta}\Vert_2^2$后变成了
\begin{equation}\boldsymbol{\theta}_{t}=(1-\varepsilon\lambda)\boldsymbol{\theta}_{t-1} - \varepsilon\boldsymbol{g}_{t}\end{equation}
由于$0 < 1-\varepsilon\lambda < 1$,所以这会使得整个优化过程中参数$\boldsymbol{\theta}$有“收缩”到0的倾向,这样的改动称为“权重衰减(Weight Decay)”。
不过,L2正则与权重衰减的等价性仅仅是在SGD优化器下成立,如果用了自适应学习率优化器如Adagrad、Adam等,那么两者不等价,在自适应学习率优化器中,L2正则的作用约等于往优化过程里边加入$-\varepsilon\lambda\text{sign}(\boldsymbol{\theta}_{t-1})$而不是$-\varepsilon\lambda\boldsymbol{\theta}_{t-1}$,也就是说每个元素的惩罚都很均匀,而不是绝对值更大的元素惩罚更大,这部分抵消了L2正则的作用。论文《Decoupled Weight Decay Regularization》首次强调了这个问题,并且提出了改进的AdamW优化器。
新的正则 #
在这一节中,我们将指出常见的深度学习模型中往往存在“权重尺度偏移(Weight Scale Shif)”现象,这个现象可能会导致了L2正则的作用没那么明显。进一步地,我们可以构建一个新的正则项,它具有跟L2类似的作用,但是与权重尺度偏移现象更加协调,理论上来说会更加有效。
权重尺度偏移 #
我们知道深度学习模型的基本结构就是“线性变换+非线性激活函数”,而现在最常用的激活函数之一是$\text{relu}(x)=\max(x,0)$。有意思的是,这两者都满足“正齐次性”,也就是对于$\varepsilon \geq 0$,我们有$\varepsilon\phi(x)=\phi(\varepsilon x)$恒成立。对于其他的激活函数如SoftPlus、GELU、Swish等,其实它们都是$\text{relu}$的光滑近似,因此可以认为它们是近似满足“正齐次性”。
“正齐次性”使得深度学习模型对于权重尺度偏移具有一定的不变性。具体来说,假设一个$L$层的模型:
\begin{equation}\begin{aligned}
\boldsymbol{h}_L =& \phi(\boldsymbol{W}_L \boldsymbol{h}_{L-1} + \boldsymbol{b}_L) \\
=& \phi(\boldsymbol{W}_L \phi(\boldsymbol{W}_{L-1} \boldsymbol{h}_{L-2} + \boldsymbol{b}_{L-1}) + \boldsymbol{b}_L) \\
=& \cdots\\
=& \phi(\boldsymbol{W}_L \phi(\boldsymbol{W}_{L-1} \phi(\cdots\phi(\boldsymbol{W}_1\boldsymbol{x} + \boldsymbol{b}_1)\cdots) + \boldsymbol{b}_{L-1}) + \boldsymbol{b}_L)
\end{aligned}\end{equation}
假设每个参数引入偏移$\boldsymbol{W}_l = \gamma_l\tilde{\boldsymbol{W}}_l,\boldsymbol{b}_l = \gamma_l\tilde{\boldsymbol{b}}_l$,那么根据正齐次性可得
\begin{equation}\begin{aligned}
\boldsymbol{h}_L =& \left(\prod_{l=1}^L \gamma_l\right)\phi(\tilde{\boldsymbol{W}}_L \boldsymbol{h}_{L-1} + \tilde{\boldsymbol{b}}_L) \\
=& \cdots\\
=& \left(\prod_{l=1}^L \gamma_l\right) \phi(\tilde{\boldsymbol{W}}_L \phi(\tilde{\boldsymbol{W}}_{L-1} \phi(\cdots\phi(\tilde{\boldsymbol{W}}_1\boldsymbol{x} + \tilde{\boldsymbol{b}}_1)\cdots) + \tilde{\boldsymbol{b}}_{L-1}) + \tilde{\boldsymbol{b}}_L)
\end{aligned}\end{equation}
如果$\prod\limits_{l=1}^L \gamma_l = 1$,那么参数为$\{\boldsymbol{W}_l,\boldsymbol{b}_l\}$就跟参数为$\{\tilde{\boldsymbol{W}}_l,\tilde{\boldsymbol{b}}_l\}$的模型完全等价了。换句话说,模型对于$\prod\limits_{l=1}^L \gamma_l = 1$的权重尺度偏移具有不变性(WEIght-Scale-Shift-Invariance,WEISSI)。
与L2正则不协调 #
刚才我们说只要尺度偏移满足$\prod\limits_{l=1}^L \gamma_l = 1$,那么两组参数对应的模型就等价了,但问题是它们对应的L2正则却不等价:
\begin{equation}\sum_{l=1}^L \Vert\boldsymbol{W}_l\Vert_2^2=\sum_{l=1}^L \gamma_l^2\Vert\tilde{\boldsymbol{W}}_l\Vert_2^2\neq \sum_{l=1}^L
\Vert\tilde{\boldsymbol{W}}_l\Vert_2^2\end{equation}
并且可以证明,如果固定$\Vert\boldsymbol{W}_1\Vert_2,\Vert\boldsymbol{W}_2\Vert_2,\dots,\Vert\boldsymbol{W}_L\Vert_2$,并且保持约束$\prod\limits_{l=1}^L \gamma_l = 1$,那么$\sum\limits_{l=1}^L
\Vert\tilde{\boldsymbol{W}}_l\Vert_2^2$的最小值在
\begin{equation}\Vert\tilde{\boldsymbol{W}_1}\Vert_2=\Vert\tilde{\boldsymbol{W}}_2\Vert_2=\dots=\Vert\tilde{\boldsymbol{W}}_L\Vert_2=\left(\prod_{l=1}^L \Vert\boldsymbol{W}_l\Vert_2\right)^{1/L}\end{equation}
事实上,这就体现了L2正则的低效性。试想一下,假如我们已经训练得到一组参数$\{\boldsymbol{W}_l,\boldsymbol{b}_l\}$,这组参数泛化性能可能不大好,于是我们希望L2正则能帮助优化器找到一组更好参数(牺牲一点$\mathcal{L}_{task}$,降低一点$\mathcal{L}_{reg}$)。但是,上述结果告诉我们,由于权重尺度偏移不变性的存在,模型完全可以找到一组新的参数$\{\tilde{\boldsymbol{W}}_l,\tilde{\boldsymbol{b}}_l\}$,它跟原来参数的模型完全等价(没有提升泛化性能),但是L2正则还更小(L2正则起作用了)。说白了,就是L2正则确实起作用了,但没有提升模型泛化性能,没有达到使用L2正则的初衷。
WEISSI正则 #
上述问题的根源在于,模型对权重尺度偏移具有不变性,但是L2正则对权重尺度偏移没有不变性。如果我们能找到一个新的正则项,它有类似的作用,同时还对权重尺度偏移不变,那么就能解决这个问题了。个人感觉原论文对这部分的讲解并不够清晰,下面的推导以笔者的个人理解为主。
我们考虑如下的一般形式的正则项
\begin{equation}\mathcal{L}_{reg}=\sum_{l=1}^L \varphi(\Vert\boldsymbol{W}_l\Vert_2)\end{equation}
对于L2正则来说,$\varphi(x)=x^2$,只要$\varphi(x)$是关于$x$在$[0,+\infty)$上的单调递增函数,那么就能保证优化目标是缩小$\Vert\boldsymbol{W}_l\Vert$。要注意我们希望正则项具有尺度偏移不变性,并不需要$\varphi(\gamma x) = \varphi(x)$,而只需要
\begin{equation}\frac{d}{dx}\varphi(\gamma x)=\frac{d}{dx}\varphi(x)\label{eq:varphi}\end{equation}
因为优化过程只需要用到它的梯度。可能有的读者都能直接看出它的一个解了,其实就是对数函数$\varphi(x) = \log x$。所以新提出来的正则项就是
\begin{equation}\mathcal{L}_{reg}=\sum_{l=1}^L \log\Vert\boldsymbol{W}_l\Vert_2=\log \left(\prod_{l=1}^L \Vert\boldsymbol{W}_l\Vert_2\right)\end{equation}
除此之外,原论文可能担心上述正则项惩罚力度还不够,还对参数方向加了个L1的惩罚,总的形式为:
\begin{equation}\mathcal{L}_{reg}=\lambda_1\sum_{l=1}^L \log\Vert\boldsymbol{W}_l\Vert_2 + \lambda_2\sum_{l=1}^L \big\Vert\boldsymbol{W}_l\big/\Vert\boldsymbol{W}_l\Vert_2\big\Vert_1\end{equation}
实验效果简述 #
按惯例展示一下原论文的是实验结果,当然既然作者都整理成文了,显然说明是有正面结果的:
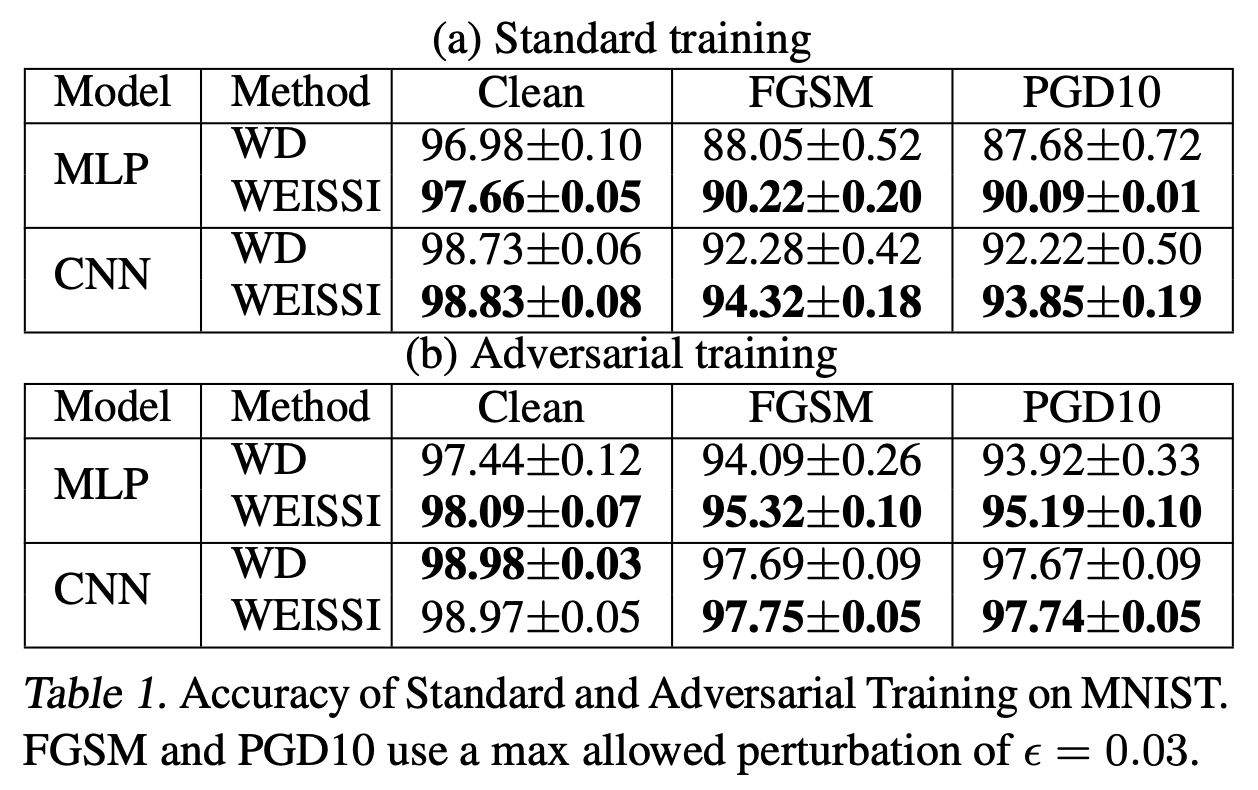
原论文对WEISSI正则的实验结果之一
对于我们来说,无非就是知道有这么个新的选择,炼丹的时候多一种尝试罢了。毕竟正则项这种东西,没有什么理论能保证它一定能起作用,还是用了才能知道结果,别人说得再漂亮也不一定有用。
文章小结 #
本文介绍了神经网络模型中的权重尺度偏移不变性的现象,并指出它与L2正则的不协调性,继而提出了作用类似但能够解决不协调性的正则项。
转载到请包括本文地址:https://spaces.ac.cn/archives/7681
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Aug. 14, 2020). 《L2正则没有想象那么好?可能是“权重尺度偏移”惹的祸 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7681
@online{kexuefm-7681,
title={L2正则没有想象那么好?可能是“权重尺度偏移”惹的祸},
author={苏剑林},
year={2020},
month={Aug},
url={\url{https://spaces.ac.cn/archives/7681}},
}

August 15th, 2020
你好,苏神,请问WEISSI正则会有类似与L2正则与自适应学习率优化器如Adagrad、Adam等的耦合效应吗?
会,根据$\log$的梯度形式,可以得到WEISSI正则对应的权重衰减项应该为$-\varepsilon\lambda\frac{\boldsymbol{\theta}_{t-1}}{\Vert\boldsymbol{\theta}_{t-1}\Vert}$。
多谢苏神
August 31st, 2020
苏神你好,请问 权重尺度偏移具有不变性 需要所有的权重的尺度变化的乘积为1,但是我们应用了L2正则的话,能保证权重的尺度变化的乘积为1吗?不应该是所有的权重都变小吗,或者说一层的权重变小另一层变大,但是怎么保证权重的尺度变化的乘积为1呢?
你没理解它的逻辑,你再认真读读“与L2正则不协调”一节。
一般情况下,训练到一定程度后,$\mathcal{L}_{reg}$降低,$\mathcal{L}_{task}$就会升高,我们就是希望通过牺牲一点$\mathcal{L}_{task}$,来换取更好的泛化性能,这个过程是通过“降低$\mathcal{L}_{ref}$、升高$\mathcal{L}_{task}$”来实现的。但是权重尺度偏移不变性告诉我们:我们完全可以降低$\mathcal{L}_{reg}$,又不用升高$\mathcal{L}_{task}$呀。所以$\mathcal{L}_{reg}$降低了,但是没有提升泛化性能。
这个现象是存在性的,当然实际优化不一定会按照这个轨迹运作(也就是乘积不一定为1),但是既然存在这种风险(说不准会隐含更大的风险),所以我们自然就要想办法规避这个风险。
September 4th, 2020
谢谢说明和指导,看了论文的那个w1,w2图,确实这个现象是存在性的,