






18
Jun
OCR技术浅探:3. 特征提取(2)
By 苏剑林 | 2016-06-18 | 51156位读者 |逐层识别 #
当图像有效地进行分层后,我们就可以根据前面的假设,进一步设计相应的模型,通过逐层处理的方式找出图像中的文字区域.
连通性
8邻接
可以看到,每一层的图像是由若干连通区域组成的,文字本身是由笔画较为密集组成的,因此往往文字也能够组成一个连通区域. 这里的连通定义为8邻接,即某个像素周围的8个像素都定义为邻接像素,邻接的像素则被定义为同一个连通区域.
定义了连通区域后,每个图层被分割为若干个连通区域,也就是说,我们逐步地将原始图像进行分解,如图9.
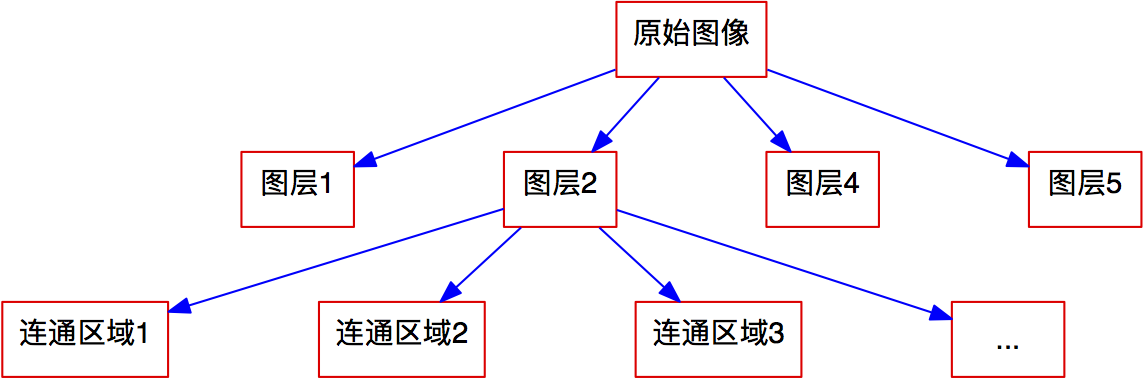
图9 图像分解结构图
抗腐蚀能力
将图像分解至连通区域这一粒度后,我们就不再细分了,下一步开始识别哪些区域是可能的文字区域. 这里我们要求文字具有一定的抗腐蚀能力. 因此我们先来定义腐蚀.
腐蚀是一种图像上的形态学变换,一般针对于二值图像,对于二值图像中的非零像素(即取值为1的像素),如果它邻接的像素都为1,则保持不变,否则变为0,这里我们同样采用的是8邻接的定义. 可以看到,如果连通区域的边界线越长,那么腐蚀运算对它的“伤害”就越大,反之,如果连通区域的边界线越短,那么腐蚀运算对它的“伤害”就越小.
根据以上腐蚀的定义,我们可以给出一个对文字区域的要求:
抗腐蚀要求 文字所在的连通区域应当具有一定的抗腐蚀能力.
这里的“一定”是指在一个连续的范围内,不能太大,也不能太小. 比如,一个面积较大的方形区域,它的抗腐蚀能力是很强的,因为它边界线很短,但这些区域明显不是文字区域,上一篇文章中分解后图层5的电饭锅便是属于这一类型;此外,抗腐蚀能力太弱也不可以,比如细长的线条,腐蚀之后可能就消失了,这些也不作为候选的文字区域,上一篇文章中分解后图层4的文字边界线就属于这一类型.
这里可以定义一个抗腐蚀能力的指标:
$$\text{连通区域的抗腐蚀能力}=\frac{\text{该区域被腐蚀后的总面积}}{\text{该区域被腐蚀前的总面积}}\tag{7}$$
经过测试,文字区域的抗腐蚀能力大概在$[0.1,0.9]$这个区间中.
经过抗腐蚀能力筛选分解的5个图层,得到如下图的特征层.

特征层1

特征层2

特征层3

特征层4
![只保留抗腐蚀能力在$[0.1,0.9]$这个区间中的连通区域](/usr/uploads/2016/06/3875269463.png)
只保留抗腐蚀能力在$[0.1,0.9]$这个区间中的连通区域
池化操作
到现在为止,我们得到了5个特征层,虽然肉眼可以看到,文字主要集中在第5个特征层. 但是,对于一般的图片,文字可能分布在多个特征层,因此需要对特征层进行整合. 我们这里进行特征整合的方法,类似于卷积神经网络中的“池化”,因此我们也借用了这个名称.
首先,我们将5个特征层进行叠加,得到一幅整体的图像特征(称为叠加特征). 这样的图像特征可以当作最后的特征输出,但并不是最好的方法. 我们认为,某个区域内的主要文字特征应该已经集中分布在某个特征层中,而不是分散在所有的特征层. 因此,得到叠加特征后,使用类似“最大值池化”的方式整合特征,步骤如下:
1. 直接叠加特征,然后对叠加特征划分连通区域;
2. 检测每个连通区域的主要贡献是哪个特征层,该连通区域就只保留这个特征层的来源.
经过这样的池化操作后,得到的最终特征结果如图11.

图11 池化后的特征
后期处理 #
对于我们演示的这幅图像,经过上述操作后,得到的特征图11已经不用再做什么处理了. 然而,对于一般的图片,还有可能出现一些没处理好的区域,这时候需要在前述结果的基础上进一步排除. 排除过程主要有两个步骤,一个是低/高密度区排除,另外则是孤立区排除.
密度排除
一种明显不是文字区域的连通区域是低密度区,一个典型的例子就是由表格线组成的连通区域,这样的区域范围较大,但点很少,也就是密度很低,这种低密度区可以排除. 首先我们来定义连通区域密度和低密度区:
连通区域密度 从一个连通区域出发,可以找到该连通区域的水平外切矩形,该区域的密度定义为
$$\text{连通区域密度}=\frac{\text{连通区域的面积}}{\text{外切矩形的面积}}\times \frac{\text{原图像总面积}}{\text{外切矩形的面积}}\tag{8}$$
低密度区 如果一个连通区域的密度小于16,那么这个连通区域定义为低密度区.
直觉上的定义应该是$\frac{\text{连通区域的面积}}{\text{外切矩形的面积}}$,但这里多了一个因子$\frac{\text{原图像总面积}}{\text{外切矩形的面积}}$,目的是把面积大小这个影响因素加进去,因为文字一般有明显的边界,容易被分割开来,所以一般来说面积越大的区域越不可能是文本区域. 这里的参数16是经验值.
低密度区排除是排除表格等线条较多的非文字区域的有效方法. 类似地,范围较大的高密度区也是一类需要排除的区域. 有了低密度区之后,就很容易定义高密度区了:
高密度区定义\cdot 如果一个连通区域以水平外切矩形反转后的区域是一个低密度区,那个这个连通区域定义为高密度区.
这个定义是很自然的,但是却有一定的不合理性. 比如“一”字,是一个水平的矩形,于是翻转后的密度为0,于是这个“一”字就被排除了,这是不合理的. 解决这个问题的一个方案是:
高密度区定义 当且仅当下面条件满足时才被定义为高密度区:
$$\frac{1+\text{外切矩形的面积}-\text{连通区域的面积}}{\text{外切矩形的面积}}\times \frac{\text{原图像总面积}}{\text{外切矩形的面积}} < 16\tag{9}$$
这是在原来定义的基础上加上了1,防止了翻转后密度为0的情况.
还有另外一种失效的情况,就是假如输入图片是单字图片,那么只有一个连通区域,且$\frac{\text{原图像总面积}}{\text{外切矩形的面积}}$接近于1,因此它就被判为低密度区,这样就排除了单字.这种情形确实比较难兼顾.一个可行的解决办法是通过人工指定是单字模式、单行模型还是整体图片模式,Google的Tesseract OCR也提供了这样的选项.
孤立区排除

孤立区演示
孤立区排除的出发点是:文字之间、笔画之间应该是比较紧凑的,如果一个区域明显地孤立于其他区域,那么这个区域很可能不是文字区域. 也就是说,可以把孤立区给排除掉. 首先我们定义孤立区的概念:
孤立区 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将这个矩形中心对称地向外扩张为原来的9倍(长、宽变为原来的3倍,如左图),扩展后的区域如果没有包含其他的连通区域,那么原来的连通区域称为孤立区.
在大多数情况,孤立区排除是一种非常简单有效的去噪方法,因为很多噪音点都是孤立区. 但是孤立区排除是会存在一定风险的. 如果一幅图像只有一个文字,构成了唯一一个连通区域,那么这个连通区域就是孤立的,于是这个文字就被排除了. 因此,要对孤立区加上更多的限制,一个可选的额外限制是:被排除的孤立区的占比$\frac{\text{连通区域的面积}}{\text{外切矩形的面积}}$要大于0.75(这个值源于圆与外切正方形的面积之比$\pi/4$).
转载到请包括本文地址:https://spaces.ac.cn/archives/3802
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 18, 2016). 《OCR技术浅探:3. 特征提取(2) 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/3802
@online{kexuefm-3802,
title={OCR技术浅探:3. 特征提取(2)},
author={苏剑林},
year={2016},
month={Jun},
url={\url{https://spaces.ac.cn/archives/3802}},
}

September 6th, 2016
[...]作者:苏剑林 来源网站:科学空间 原文链接: OCR技术浅探:3. 特征提取(2)[...]
April 18th, 2018
[...]OCR技术浅探:3. 特征提取(2)[...]
August 12th, 2020
为什么一定是用黑色腐蚀白色呢?文字的颜色有可能是黑色也有可能是白色
经过这样处理后,大多数情况下都已经变成了黑底白字。
November 17th, 2022
[...]OCR技术浅探:3. 特征提取(2)[...]
November 17th, 2022
[...]OCR技术浅探:3. 特征提取(2)[...]
April 1st, 2023
[...]OCR技术浅探:3. 特征提取(2)[...]